






1、工业场景
冶金过程中生产的各种煤气,例如高炉煤气、焦炉煤气、转炉煤气等。作为重要的副产品和二次能源,保证它们的梯级利用和减少放散是煤气能源平衡调控的一项紧迫任务,准确的预测煤气的发生量是实现煤气系统在线最优调控的前提。
2、数学模型
本次研究主要采用了长短记忆模型(LSTM)预测了正常工况下的高炉煤气发生量。后续研究方向希望将正常工况扩展到变化工况条件下,例如休风、减产、停产、检修等条件下煤气发生量,并引入更多特征维度,例如:焦比、煤比、风量、富氧、风温、风压、炉内压差等。下面重点介绍一下LSTM网络结构。
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。
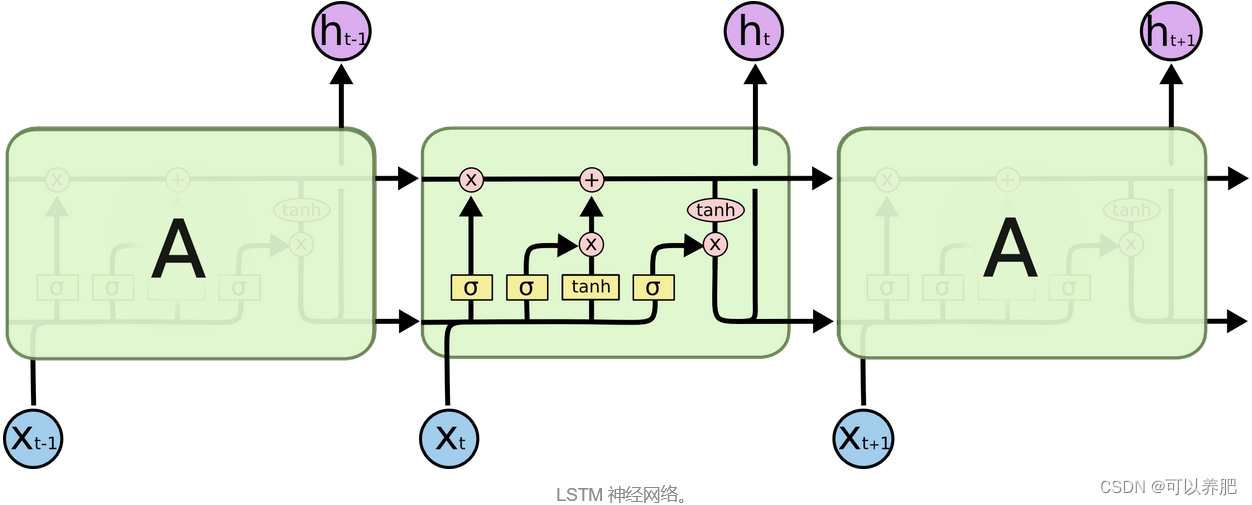 这张图片是经典的LSTM网络结构的图片,但是不好理解,图片把多维的空间结构压缩成了二维图片,所以需要大家脑补一下,回放到立体空间中去理解。相对比RNN 通过时间步骤地更新隐藏状态和输出结果。而LSTM 通过输入门、遗忘门和输出门来控制隐藏状态的更新和输出。在这里不过多的去讲解模型结构,大家可以从网上了解一下,LSTM网络模型作为世纪霸主被广泛应用于自然语言处理、语音识别、图像处理等领域。总之很厉害!
这张图片是经典的LSTM网络结构的图片,但是不好理解,图片把多维的空间结构压缩成了二维图片,所以需要大家脑补一下,回放到立体空间中去理解。相对比RNN 通过时间步骤地更新隐藏状态和输出结果。而LSTM 通过输入门、遗忘门和输出门来控制隐藏状态的更新和输出。在这里不过多的去讲解模型结构,大家可以从网上了解一下,LSTM网络模型作为世纪霸主被广泛应用于自然语言处理、语音识别、图像处理等领域。总之很厉害!
3、数据准备
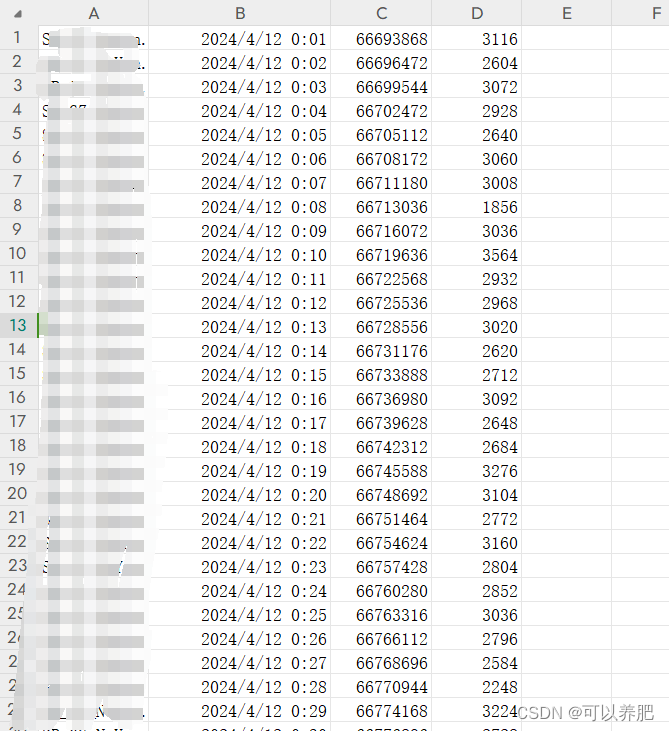
本次数据收集了1#高炉从4月12日0点到4月16日0点72小时的煤气累计发生量数据,时间间隔为60000ms也就是1分钟一次点位数据,通过计算获取5760个分钟级的煤气发生量数据。
如图:第一个字段是数采时序库中的点位标识,第二个字段是时间,第三个字段是当前煤气发生量累计值,第四个字段是计算获得的当前分钟内煤气发生量。
4、模型构建
class LSTM(nn.Module):
"""
LSMT网络搭建
"""
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1 # 单向LSTM
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
pred = self.linear(output)
pred = pred[:, -1, :]
return pred
5、模型训练
①数据预处理:加载数据文件,原始数据文件为csv(通过1#高炉84小时内煤气发生量累计值,时间间隔为60000ms,计算出84小时内每分钟的发生量)将数据分为训练集:验证集:测试集=3:1:1。
def load_data(file_name):
"""
加载数据文件,原始数据文件为csv(通过1#高炉24小时内煤气发生量累计值,时间间隔为60000ms,计算出24小时内每分钟的发生量)
:param file_name csv文件的绝对路径
:return 训练集、验证集、测试集、训练集中最大值、训练集中最小值
训练集:验证集:测试集=3:1:1
"""
dataset = pd.read_csv('D:\\LIHAOWORK\\' + file_name, encoding='gbk')
train = dataset[:int(len(dataset) * 0.6)]
val = dataset[int(len(dataset) * 0.6):int(len(dataset) * 0.8)]
test = dataset[int(len(dataset) * 0.8):len(dataset)]
max, nin = np.max(train[train.columns[3]]), np.min(train[train.columns[3]]) # 分钟内发生量是csv中第四个字段
return train, val, test, max, nin
②数据组装:把数据组装成训练、验证、测试需要的格式。实质是90个顺序数据为一组作为输入值x,第91个作为真实发生值y,如此循环。
def process_data(data, batch_size, shuffle, m, n, k):
"""
数据处理
:param data 待处理数据
:param batch_size 批量大小
:param shuffle 是否打乱
:param m 最大值
:param n 最小值
:param k 序列长度
:return 处理好的数据
"""
data_3 = data.iloc[0:, [3]].to_numpy().reshape(-1) #
data_3 = data_3.tolist()
data = data.values.tolist()
data_3 = (data_3 - n) / (m - n)
feature = []
label = []
for i in range(len(data) - k):
train_seq = []
train_label = []
for j in range(i, i + k):
x = [data_3[j]]
train_seq.append(x)
train_label.append(data_3[i + k])
feature.append(train_seq)
label.append(train_label)
feature_tensor = torch.FloatTensor(feature)
label_tensor = torch.FloatTensor(label)
data = TensorDataset(feature_tensor, label_tensor)
data_loader = DataLoader(dataset=data, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=True)
return data_loader
③模型训练:输入大小为1;隐藏层大小为128,隐藏层数为1,输出大小为1,批量大小为5,学习率为0.01,训练次数3。
def train(Dtr, Val, path):
"""
训练
:param Dtr 训练集
:param Val 验证集
:param path 模型保持路劲
"""
input_size = 1
hidden_size = 128
num_layers = 1
output_size = 1
epochs = 5
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=1e-4)
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# start training
for epoch in tqdm(range(epochs)):
train_loss = []
for (seq, label) in Dtr:
y_pred = model(seq)
loss = loss_function(y_pred, label)
train_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
# validation
model.eval()
val_loss = []
for seq, label in Val:
y_pred = model(seq)
loss = loss_function(y_pred, label)
val_loss.append(loss.item())
print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), np.mean(val_loss)))
model.train()
state = {'models': model.state_dict()}
torch.save(state, path)
训练过程如下:

④模型测试:
def test(Dte, path, m, n):
"""
测试
:param Dte 测试集
:param path 模型
:param m 最大值
:param n 最小值
"""
pred = []
y = []
input_size = 1
hidden_size = 128
num_layers = 1
output_size = 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)
model.load_state_dict(torch.load(path)['models'])
model.eval()
for (seq, target) in tqdm(Dte):
y.extend(target)
with torch.no_grad():
y_pred = model(seq)
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
# 出图
x = [i for i in range(len(y))]
x_smooth = np.linspace(np.min(x), np.max(x), 1000)
y_smooth = make_interp_spline(x, y)(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')
y_smooth = make_interp_spline(x, pred)(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
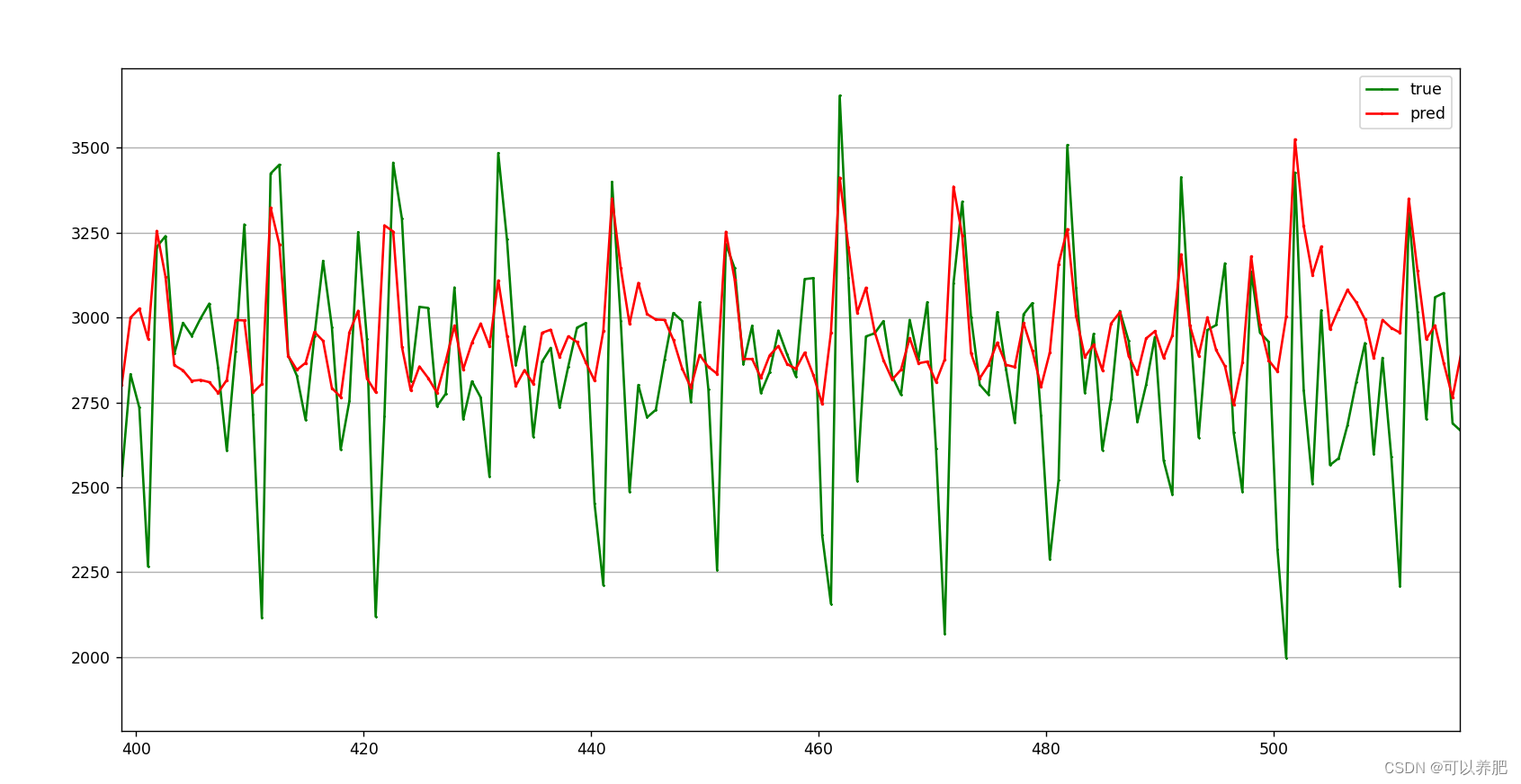
直接对比图:红色线为模型在测试数据集上的预测值,绿色线为真实的发生值。
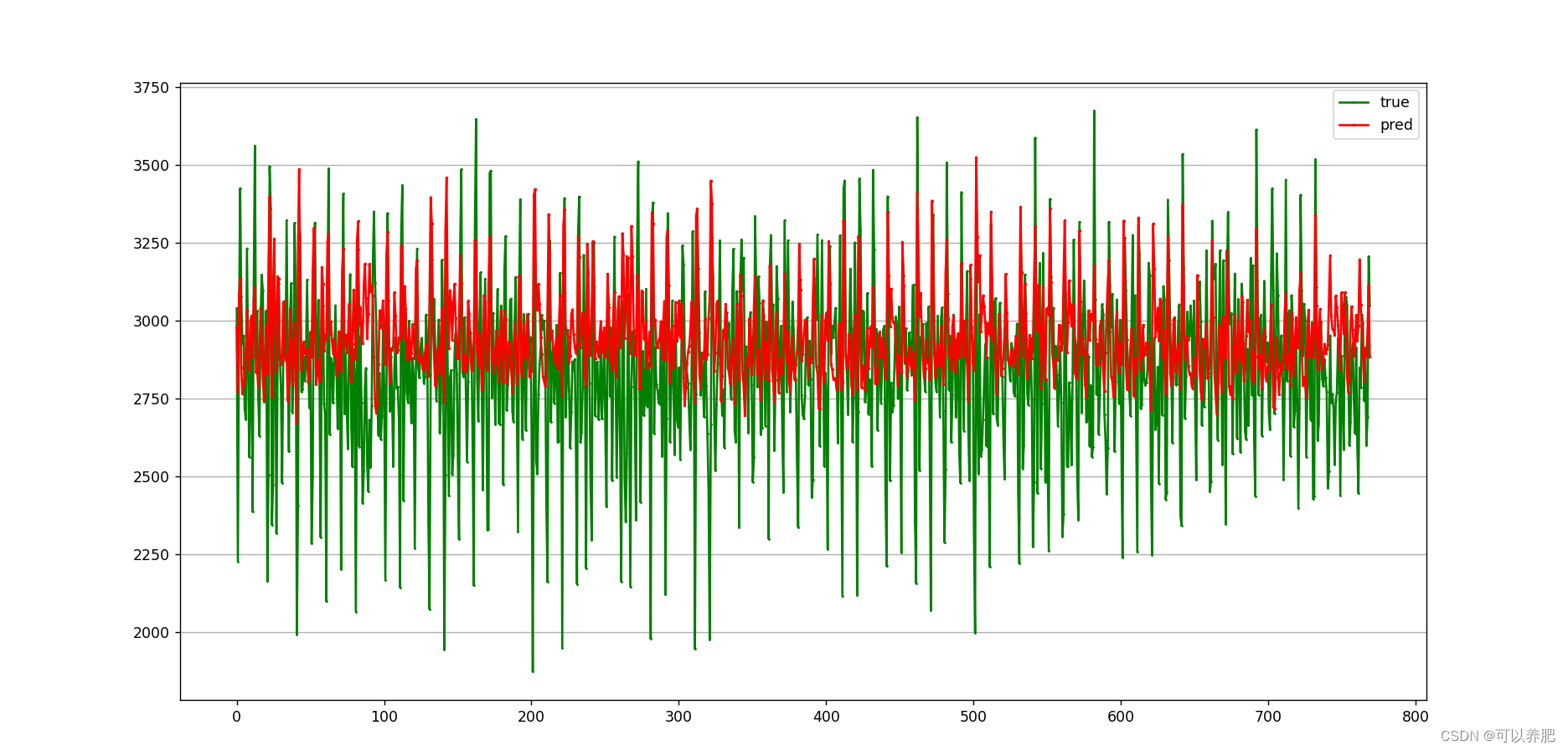 有点密密麻麻,我们可以看一下局部
有点密密麻麻,我们可以看一下局部
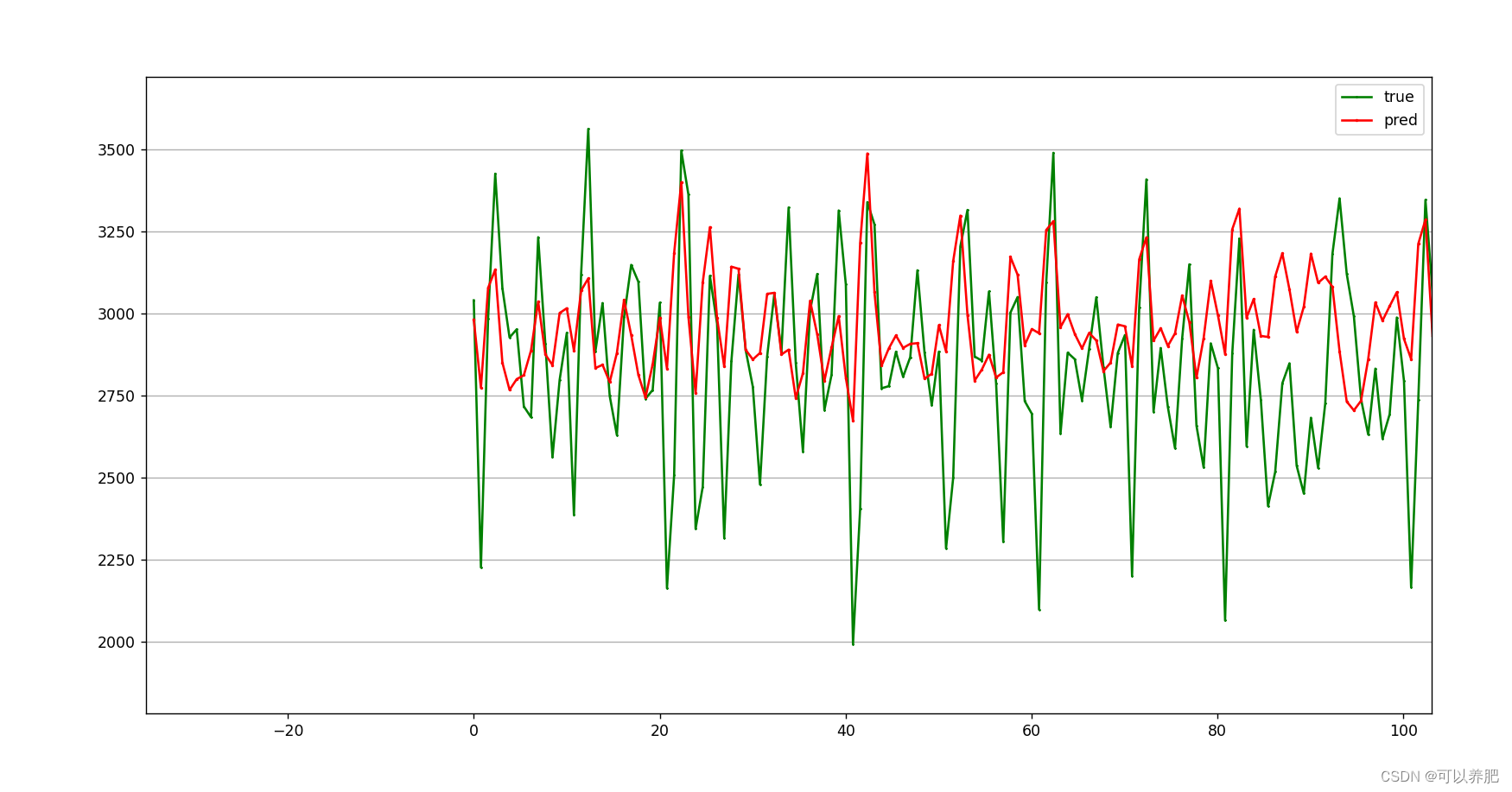
 ⑤滚动测试30分钟内发生值,利用前90分钟的真实发生值预测第91分钟的发生值,再将第91分钟的发生值加入到输入中,预测第92分钟的发生值,以此类推,预测30分钟内的高炉煤气发生量。
⑤滚动测试30分钟内发生值,利用前90分钟的真实发生值预测第91分钟的发生值,再将第91分钟的发生值加入到输入中,预测第92分钟的发生值,以此类推,预测30分钟内的高炉煤气发生量。
def test_rolling(Dte, path, m, n):
"""
滚动测试,预测30条
:param Dte 测试集
:param path 模型
:param m 最大值
:param n 最小值
"""
pred = []
y = []
input_size = 1
hidden_size = 128
num_layers = 1
output_size = 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=1)
model.load_state_dict(torch.load(path)['models'])
model.eval()
i = 0 # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量
for (seq, target) in tqdm(Dte):
y.extend(target)
with torch.no_grad():
seq = seq.numpy().tolist()[0]
seq.extend(pred) # 预测值追加到后面
seq = seq[-90:] # 截取后90条数据,滚动预测
seq = torch.tensor(seq).resize(1, 90, 1)
y_pred = model(seq)
pred.extend(y_pred)
i = i + 1
if i >= 30: # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量
break
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
# 出图
x = [i for i in range(len(y))]
x_smooth = np.linspace(np.min(x), np.max(x), 1000)
y_smooth = make_interp_spline(x, y)(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')
y_smooth = make_interp_spline(x, pred)(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
出图
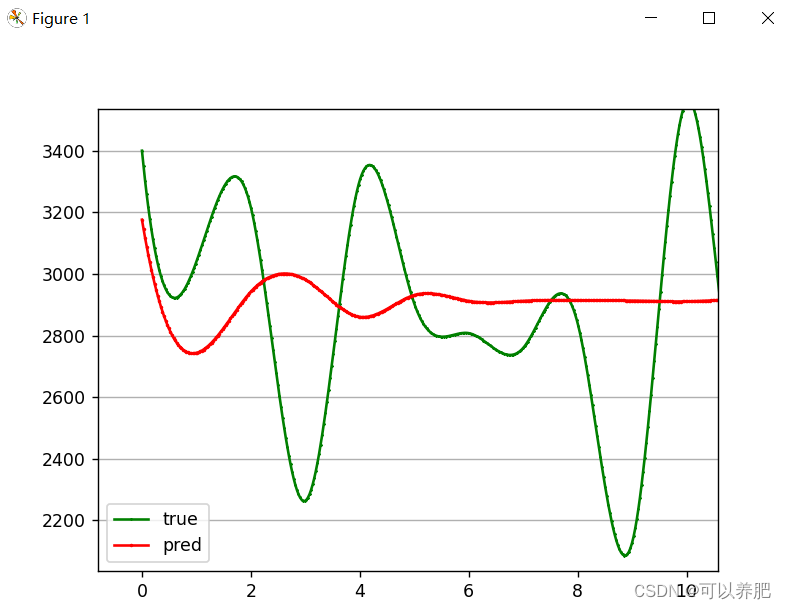 有点过分拟合
有点过分拟合
调整参数num_layers = 2 增加dropout=0.3 后
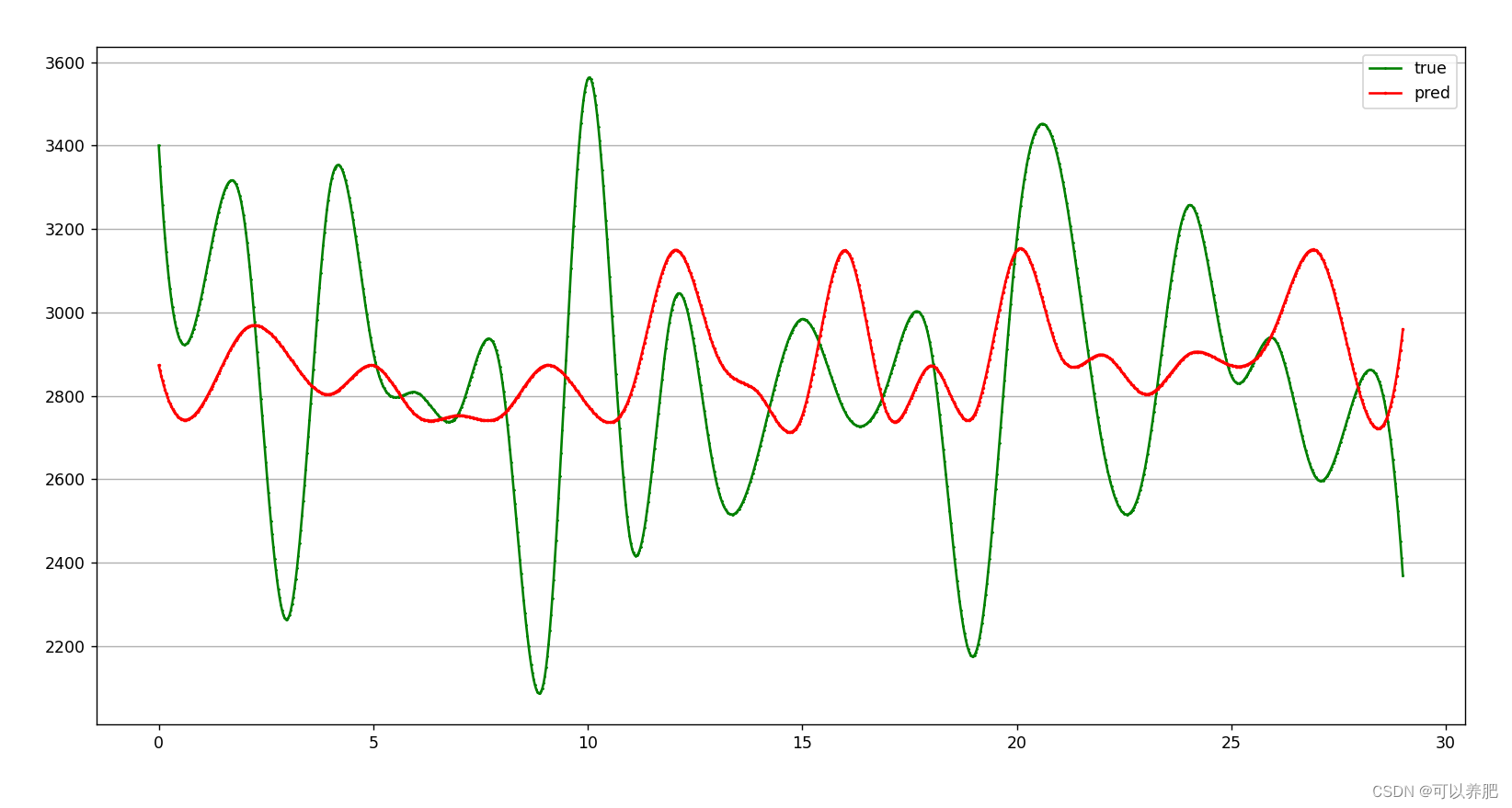 整体效果不是很理想,可能再调一下参会好一些。
整体效果不是很理想,可能再调一下参会好一些。
目前的完整代码如下:
import pandas as pd
import numpy as np
import torch
from matplotlib import pyplot as plt
from scipy.interpolate import make_interp_spline
from torch import nn
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
def load_data(file_name):
"""
加载数据文件,原始数据文件为csv(通过1#高炉24小时内煤气发生量累计值,时间间隔为60000ms,计算出24小时内每分钟的发生量)
:param file_name csv文件的绝对路径
:return 训练集、验证集、测试集、训练集中最大值、训练集中最小值
训练集:验证集:测试集=3:1:1
"""
dataset = pd.read_csv('D:\\LIHAOWORK\\' + file_name, encoding='gbk')
train = dataset[:int(len(dataset) * 0.6)]
val = dataset[int(len(dataset) * 0.6):int(len(dataset) * 0.8)]
test = dataset[int(len(dataset) * 0.8):len(dataset)]
max, nin = np.max(train[train.columns[3]]), np.min(train[train.columns[3]]) # 分钟内发生量是csv中第四个字段
return train, val, test, max, nin
def process_data(data, batch_size, shuffle, m, n, k):
"""
数据处理
:param data 待处理数据
:param batch_size 批量大小
:param shuffle 是否打乱
:param m 最大值
:param n 最小值
:param k 序列长度
:return 处理好的数据
"""
data_3 = data.iloc[0:, [3]].to_numpy().reshape(-1) #
data_3 = data_3.tolist()
data = data.values.tolist()
data_3 = (data_3 - n) / (m - n)
feature = []
label = []
for i in range(len(data) - k):
train_seq = []
train_label = []
for j in range(i, i + k):
x = [data_3[j]]
train_seq.append(x)
train_label.append(data_3[i + k])
feature.append(train_seq)
label.append(train_label)
feature_tensor = torch.FloatTensor(feature)
label_tensor = torch.FloatTensor(label)
data = TensorDataset(feature_tensor, label_tensor)
data_loader = DataLoader(dataset=data, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=True)
return data_loader
class LSTM(nn.Module):
"""
LSMT网络搭建
"""
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1 # 单向LSTM
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, dropout=0.3, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
pred = self.linear(output)
pred = pred[:, -1, :]
return pred
def train(Dtr, Val, path):
"""
训练
:param Dtr 训练集
:param Val 验证集
:param path 模型保持路劲
"""
input_size = 1
hidden_size = 128
num_layers = 2
output_size = 1
epochs = 3
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=1e-4)
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# start training
for epoch in tqdm(range(epochs)):
train_loss = []
for (seq, label) in Dtr:
y_pred = model(seq)
loss = loss_function(y_pred, label)
train_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
# validation
model.eval()
val_loss = []
for seq, label in Val:
y_pred = model(seq)
loss = loss_function(y_pred, label)
val_loss.append(loss.item())
print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), np.mean(val_loss)))
model.train()
state = {'models': model.state_dict()}
torch.save(state, path)
def test(Dte, path, m, n):
"""
测试
:param Dte 测试集
:param path 模型
:param m 最大值
:param n 最小值
"""
pred = []
y = []
input_size = 1
hidden_size = 128
num_layers = 2
output_size = 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)
model.load_state_dict(torch.load(path)['models'])
model.eval()
for (seq, target) in tqdm(Dte):
y.extend(target)
with torch.no_grad():
y_pred = model(seq)
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
# 出图
x = [i for i in range(len(y))]
x_smooth = np.linspace(np.min(x), np.max(x), 1000)
y_smooth = make_interp_spline(x, y)(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')
y_smooth = make_interp_spline(x, pred)(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
def test_rolling(Dte, path, m, n):
"""
滚动测试,预测30条
:param Dte 测试集
:param path 模型
:param m 最大值
:param n 最小值
"""
pred = []
y = []
input_size = 1
hidden_size = 128
num_layers = 2
output_size = 1
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=1)
model.load_state_dict(torch.load(path)['models'])
model.eval()
i = 0 # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量
for (seq, target) in tqdm(Dte):
y.extend(target)
with torch.no_grad():
seq = seq.numpy().tolist()[0]
seq.extend(pred) # 预测值追加到后面
seq = seq[-90:] # 截取后90条数据,滚动预测
seq = torch.tensor(seq).resize(1, 90, 1)
y_pred = model(seq)
pred.extend(y_pred)
i = i + 1
if i >= 30: # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量
break
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
# 出图
x = [i for i in range(len(y))]
x_smooth = np.linspace(np.min(x), np.max(x), 1000)
y_smooth = make_interp_spline(x, y)(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')
y_smooth = make_interp_spline(x, pred)(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
if __name__ == '__main__':
Dtr, Val, Dte, m, n = load_data("4.csv")
Dtr = process_data(Dtr, 5, False, m, n, 90)
Val = process_data(Val, 5, False, m, n, 90)
#Dte = process_data(Dte, 5, False, m, n, 90)
Dte = process_data(Dte, 1, False, m, n, 90)
train(Dtr, Val, "D:\\LIHAOWORK\\model.pth")
#test(Dte, "D:\\LIHAOWORK\\model.pth", m, n)
test_rolling(Dte, "D:\\LIHAOWORK\\model.pth", m, n)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









