







前两天介绍完了scrapy基础操作之后,今天我们来实践操一下
全栈爬取笔趣阁小说,我们要先分析其主要URL地址,可分为以下三大类:
- 所有小说url地址总表
- 小说章节总表
- 小说章节内
根据分析,就需要写三个函数来对页面内容进行提取和处理
spider代码
# -*- coding: utf-8 -*-
import scrapy
from biquge.items import BiqugeItem
import os
class SpiderSpider(scrapy.Spider):
name = 'spider'
allowed_domains = ['www.xbiquge.la']
start_urls = ['http://www.xbiquge.la/xiaoshuodaquan/']
def parse(self, response):
#全部小说列表
name=response.xpath("//div[@class='novellist']/ul/li/a/text()").extract()
url=response.xpath("//div[@class='novellist']/ul/li/a/@href").extract()
for i in range(len(name)):
item=BiqugeItem()
item['name']=name[i]
item['url']=url[i]
if (not os.path.exists(name[i])):
os.makedirs(name[i])
yield scrapy.Request(url=item['url'],meta={'meta1':item},callback=self.url_parse)
def url_parse(self,response):
#小说章节列表
meta1=response.meta['meta1']
lists=response.xpath("//div[@id ='list']/dl//dd/a/@href").extract()
for i in range(len(lists)):
item=BiqugeItem()
item['title_url']="http://www.xbiquge.la"+lists[i]
item['name'] = meta1['name']
item['url'] = meta1['url']
yield scrapy.Request(url=item['title_url'],meta={'meta2':item},callback=self.detail_parse)
def detail_parse(self,response):
#章节详细内容
meta2=response.meta['meta2']
item = BiqugeItem()
item['title']=response.xpath("//div[@class='bookname']/h1/text()").extract()[0]
novel=response.xpath("//div[@id='content']/text()").extract()
item['novel']= "\n".join(novel).replace(" ", " ")
item['name']=meta2['name']
yield item
items代码
class BiqugeItem(scrapy.Item):
name=scrapy.Field()#小说名字
url=scrapy.Field()#小说章节目录
title_url=scrapy.Field()#小说章节地址
novel=scrapy.Field()#小说章节内容
title=scrapy.Field()#小说章节标题
pipelines代码
class BiqugePipeline(object):
def process_item(self, item, spider):
#同一个小说按章节名字保存txt文件
fp = open(item['name']+'/'+item['title']+".txt", "a",encoding='utf8')
fp.write(item['title'])
fp.write('\n')
novel=item['novel'].encode('GBK','ignore').decode('GBk')#转码,否则报错
fp.write(novel)
fp.write('\n')
fp.close()
return item
为什么不将小说保存进一个TXT文件里而是按照章节名字保存?
因为scrapy是异步,异步处理请求,也就是说Scrapy发送请求之后,不会等待这个请求的响应(也就是不会阻塞),而是可以同时发送其他请求或者做别的事情。而我们知道服务器对于请求的响应是由很多方面的因素影响的。但后面将会有对代码的改进将一部小说保存进一个TXT文件中
- 效果展示
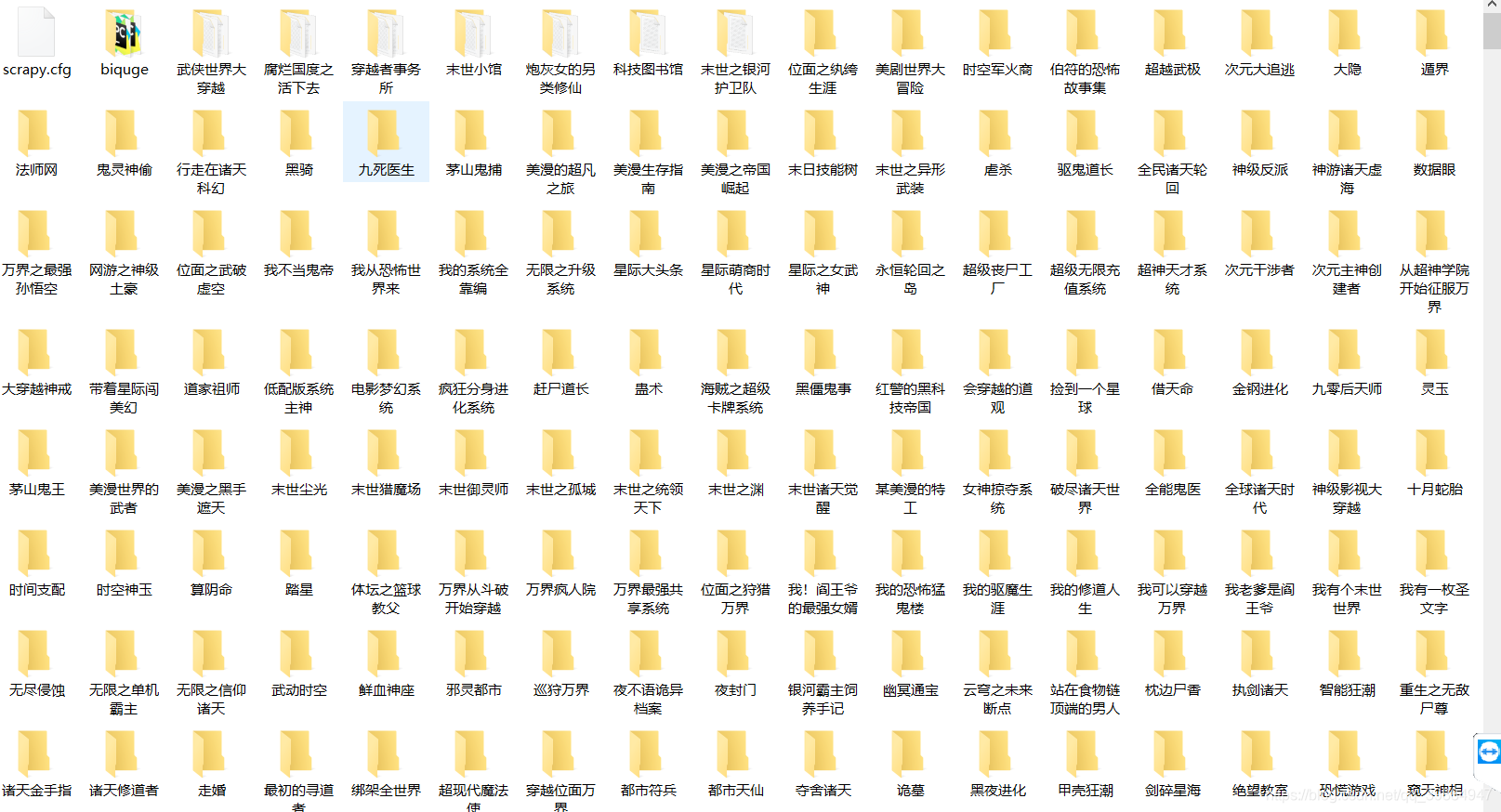

当然这只是一个很简陋的代码,更多的细节需要不断去完善。
没有一蹴而就的成功,只有不断努力的拼搏














 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









