






本人是一个小说迷,喜欢用电纸书看小说,但苦于难以寻找网络小说的txt版本,加之最近学习了一下怎么用scrapy爬取网页数据,所以想到去使用scrapy框架来爬取笔趣阁小说存为txt文件,在爬取过程中对于并发请求的章节排序是一个难点,本代码采用字典来解决这一问题。废话不多说,直接上思路和代码。
首先看一下小说的网页界面,今天爬取的小说是最近比较火的大奉打更人

首先在终端创建一个scrapy项目
scrapy startproject dagengren终端输出:

按照提示在终端输入:
cd dagengren
scrapy genspider quge quge7.com在pycharm打开这个项目:
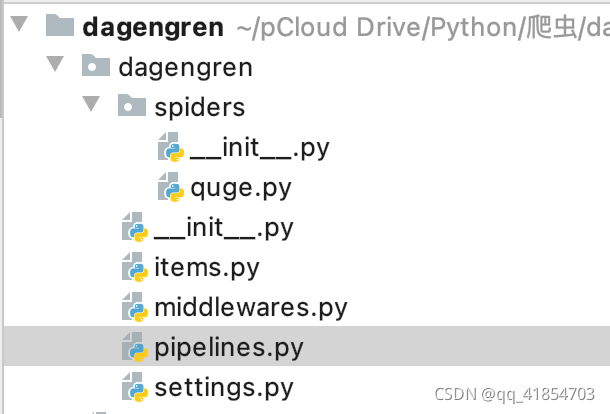
首先编辑quge.py这个文件:
import re
import scrapy
import urllib
class QugeSpider(scrapy.Spider):
name = 'quge'
allowed_domains = ['quge7.com']
# start_urls填入爬取的网页链接
start_urls = ['https://www.quge7.com/book/1472/']
def parse(self, response):
items = {}
# 'cur'项记录爬取的章节数
items['cur'] = 0
# 'xpath'提取小说标题
items['title'] = response.xpath("//div[@class='info']/h1/text()").extract_first()
# 'xpath'提取小说作者
items['author'] = response.xpath("//div[@class='small']/span[1]/text()").extract_first()
# 'xpath'提取小说目录
dd_list = response.xpath('//div[@class="listmain"]/dl/dd')
# 'max_page_href'为最后一章的链接
max_page = dd_list[-1]
max_page_href = max_page.xpath('./a/@href').extract_first()
# 因为'max_page_href'得到的链接不完整,如/book/1472/1.html
# 通过urlib.parse.urljoin()方法可将链接补全
max_page_href = urllib.parse.urljoin('https://www.quge7.com/book/1472/',max_page_href)
# 提取最大章节数
max_number = int(re.findall(r'https://www.quge7.com/book/1472/(.*?)\.html', max_page_href)[-1])
# 生成爬取的网页链接列表
url_list = ["https://www.quge7.com/book/1472/"+str(i)+".html" for i in range(1,max_number+1)]
# 爬取网页链接列表里面的网页
for url in url_list:
# 创造请求,交给parse_content处理响应
yield scrapy.Request(url,callback=self.parse_content,meta={'items':items})
# 在item里面存入章节数
items['max_page'] = max_number
def parse_content(self,response):
# 拿出items
items = response.meta['items']
# 爬取的章节数加一
items['cur'] += 1
# 'current_page'为当前第几章
current_page = int(re.findall(r'https://www.quge7.com/book/1472/(.*?)\.html',response.url)[-1])
# 提取章节标题
small_title = response.xpath("//span[@class='title']/text()").extract_first()
# 提取章节文本
texts = response.xpath("//div[@id='chaptercontent']/text()").extract()
# 过滤文本
texts = [re.sub(r'\u3000\u3000',r'\n',text) for text in texts]
# 把文本列表转换成字符串
items[current_page] = "".join(texts)
# 将章节标题加入到文本中
items[current_page] = small_title+'\n'+items[current_page]
# 把item传递给piplines处理
yield items
这里有一个很巧妙的地方就是将章节数与章节文本做了一个键值对:
items[current_page] = small_title+'\n'+items[current_page]到时候写入文本的时候就可以依照这个键值对按顺序写入文件中,解决章节排序问题
pipelines.py中的配置
from itemadapter import ItemAdapter
class DagengrenPipeline:
def process_item(self, item, spider):
# 显示爬取的章节数目
print(item['cur'])
# 如果爬取的章节数目等于最大章节数,开始将小说写入文件
if item['cur']==item['max_page']:
with open("novel.txt",'w+') as file_object:
try:
# 写入小说标题
file_object.write(item['title']+'\n')
# 写入作者名
file_object.write(item['author']+'\n')
# 按章节顺序写入小说正文
for i in range(1,item['max_page']+1):
file_object.write(item[i])
except:
pass
注意到这段处理代码中只有当爬取的章节数等于最大章节数时,才在文件中写入小说文本,方便在接下来的循环中按顺序写入小说。
settings.py配置:
BOT_NAME = 'dagengren'
SPIDER_MODULES = ['dagengren.spiders']
NEWSPIDER_MODULE = 'dagengren.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
LOG_LEVEL = 'WARNING'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'dagengren.middlewares.DagengrenSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'dagengren.middlewares.DagengrenDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'dagengren.pipelines.DagengrenPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'爬取速度:

可以看到下载速度已经很快了,这还只是使用了默认的16线程的结果,想要更快的话可以在settings.py里面修改并发数目。
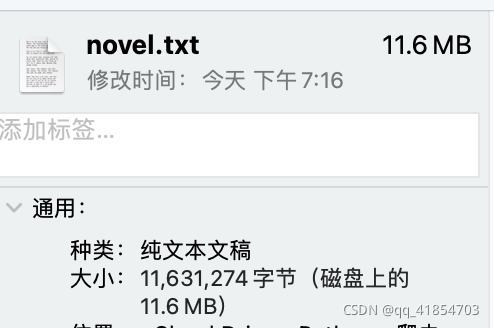
最终成品:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









