







音频是我们日常生活中不可或缺的一部分。从早晨的闹钟声,到晚上的音乐会,我们都会接触到各种各样的音频资源。但是在需求不同的情况下,音频的使用方式也各不相同。当你需要从一段音频中提取特定信息时,如何快速有效地获取这些内容呢?答案就是通过音频转文字技术。音频转文字技术可以将语音转换为文本,从而使得这些文本可以被编辑、存储、甚至是翻译。那么,大家知道怎样音频转文字吗?一起来看看吧!

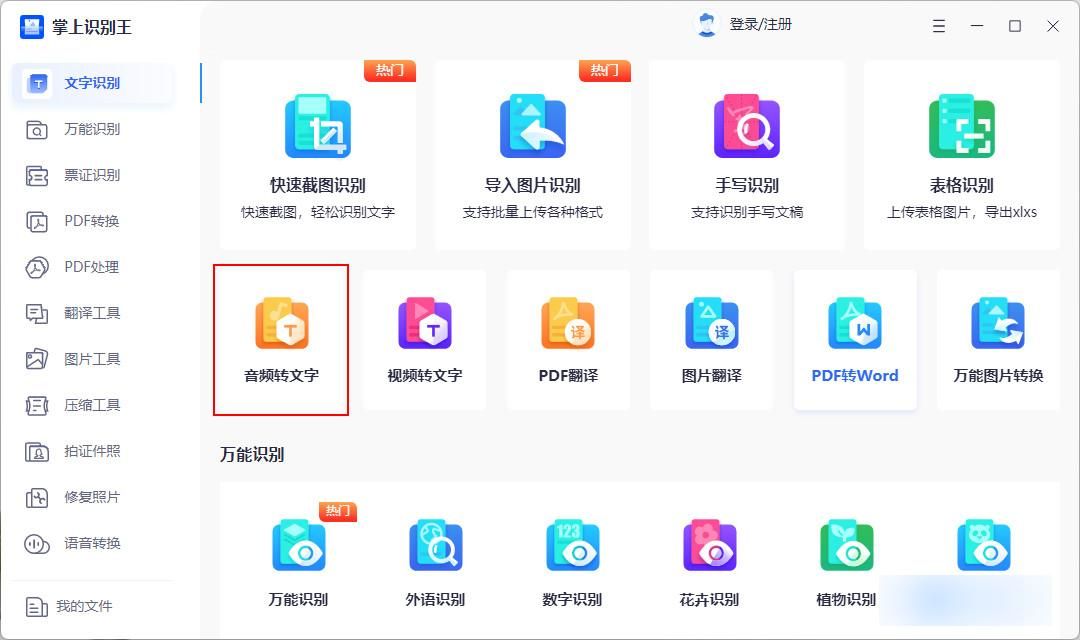
方法一:用“掌上识别王”把音频转成文字
软件介绍:掌上识别王是一款非常实用的语音识别软件,可以将音频文件转化为文本,帮助我们更加方便快捷地进行文字编辑和记录。
操作步骤:打开软件,选择“音频转文字”模块,接着在弹出的界面中选择需要转换的音频文件,点击“开始识别”按钮,等待转换完成即可。
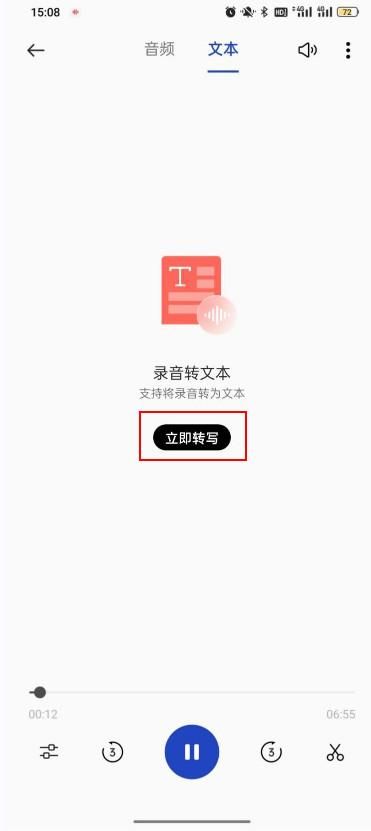
方法二:用“手机录音机”把音频转成文字
软件介绍:使用手机录音机,您可以轻松地记录和保存音频文件,并将它们转换成文字文档。
操作步骤:打开应用程序,找到需要转换的音频文件,并点击“立即转写”按钮
等待几秒钟,系统会自动将音频文件转换成文字。
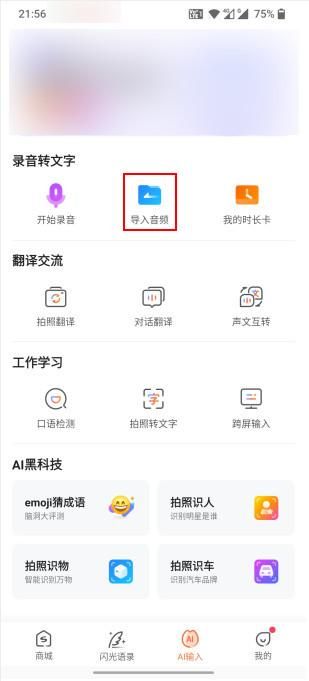
方法三:用“搜狗输入法”把音频转成文字
软件介绍:搜狗输入法的音频转文字功能是非常实用的工具,它可以将音频文件中的语音内容转换成文字,提高我们的工作效率。
操作步骤:打开软件,在AI输入模块中找到“导入音频”图标,点击进入,接着添加需要转换的音频文件就可以实现音频转文字操作了。
现在大家知道怎样音频转文字了吧!总之,音频转文字是一种非常有效和便捷的工具,可以帮助我们更好地处理口述内容,并提高工作效率。

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









