







查阅elementtree官方APIhttps://docs.python.org/3.6/library/xml.etree.elementtree.html
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
1.SAX (simple API for XML )
Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
2.DOM(Document Object Model)
将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
3.ElementTree(元素树)
ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
注:因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
element. findall()只查找带有当前元素直接子标签的元素。
Element.find()查找带有特定标记和元素的第一个子元素。
text访问元素的文本内容。
element .get()访问元素的属性
Element.iter ():递归地遍历它下面的所有子树(子树的子树,子树的子树,等等)
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()
root = ET.fromstring(country_data_as_string)
以下使用ElementTree解析xml
#/bin/python3
import xml.etree.ElementTree as ET
def getXmlValueByName(xmlNodeName,xml):
root = ET.fromstring(xml)
for xmlNode in root.iter(xmlNodeName):
return str(xmlNode.text)
def getXmlNodeByName(xmlNodeName,xml):
root = ET.fromstring(xml)
for xmlNode in root.iter(xmlNodeName):
return str(ET.tostring(xmlNode,'utf-8',method='xml').decode('utf-8'))
def getXmlNodeListByName(xmlNodeName,xml):
list=[]
root = ET.fromstring(xml)
for xmlNode in root.iter(xmlNodeName):
x = str(ET.tostring(xmlNode,'utf-8',method='xml').decode('utf-8'))
list.append(x)
return list
def main():
xml ="""<Document>
<POQ>
<PH01>
<PH010R01>2020-10-16</PH010R01>
<PH010D01>1</PH010D01>
<PH010Q02>孙悟空</PH010Q02>
<PH010Q03>02</PH010Q03>
</PH01>
<PH01>
<PH010R01>2020-10-15</PH010R01>
<PH010D01>2</PH010D01>
<PH010Q02>猪八戒</PH010Q02>
<PH010Q03>02</PH010Q03>
</PH01>
<PH01>
<PH010R01>2020-10-14</PH010R01>
<PH010D01>3</PH010D01>
<PH010Q02>唐僧</PH010Q02>
<PH010Q03>02</PH010Q03>
</PH01>
</POQ>
</Document>"""
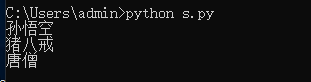
for x in getXmlNodeListByName("PH01",xml):
print(getXmlValueByName("PH010Q02",str(x)))
if __name__ == "__main__":
main()















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









