







文章目录
一、分组
分组其实就是一个小括号而已,例如下图的正则表达式。
第一个是:邮箱的正则,这里我们是将红色框框起来的这一堆进行了分组,这一堆在正式的邮箱中就表示 .cn 或者 .edu.cn,这一部分是出现一次或两次。

第二个是:身份证号码的简易正则表达式,这里就是将后面的四位分成了一组。

那为什么要这么分呢?因为这里是有 | 符号的,如果我们没有将它分组,它就会把左边这个整体当做是第一个条件,中间的 X 是第二个条件,右边的 x 是第三个条件。

但是我现在加上了分组,此时它就会认为:\\d 是第一个条件,中间的 X 是第二个条件,右边的 x 是第三个条件。

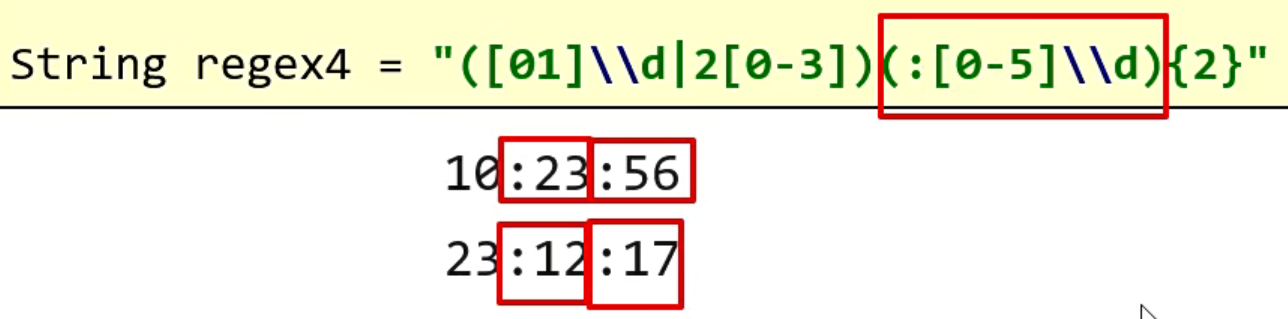
第三个是:我们之前写的关于24小时时间的正则表达式
我们还是以案例来看正则:在这里,我把小时做了一个单独的分组,这里的原因也是因为在小时中有一个 |,如果这里你没有进行分组,它就会将右边的所有当做第二个条件。

但现在我已经分组了,它就会认为 [01]\\d 是第一个条件,2[0-3] 是第二个条件,因为在小时中,有可能是 1 开头的,也有可能是 2 开头的,如果你是 1 开头的,后面可以是任意的数字;但是如果你是 2 开头的,后面只能是 0-3,两种情况是不一样的,所以我们需要分开书写。

关于 24小时 的正则表达式我们还有一种写法:由于 :分钟 和 :秒钟 的规则其实是一样的,既然是一样的,我们就没有必要去写两遍,我们可以把 :分钟 看做是一组,这一组一共出现两次。
这就是我们之前写的分组,但是在分组的时候有一些小细节需要掌握一下。
二、细节
正则表达式中,每一组其实是有组号的,也就是序号,它的规则有两个。
规则1:从 1 开始,连续不间断。
规则2:以左括号为基准,最左边的是第一组,其次为第二组,以此类推。
例如:(\\d+)(\\d+)(\\d+)
以左括号为基准,即:只看左括号,不看其他的。
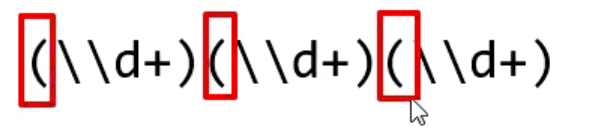
现在,最左边的是第一组(红色),中间的是第二组(蓝色),右边的是第三组(绿色)。
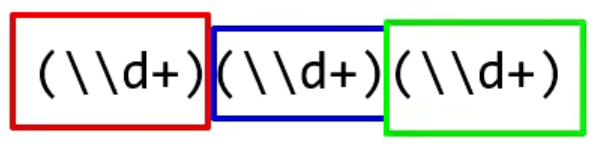
接下来考你个问题:下面蓝色框起来的这一组,它是第几组呢?
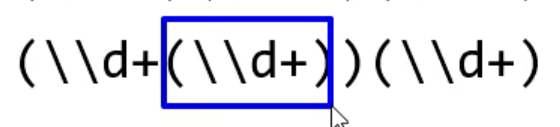
正确答案:第二组。
根据规则二:以左括号为基准,因此只看左括号,不看其他的,下图用红框框起来了。
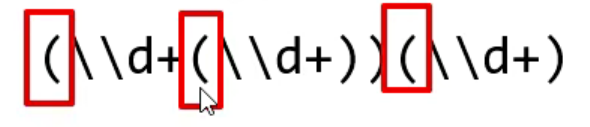
最左的的是第一组(红色),中间的是第二组(蓝色),最右边的是第三组(绿色)。
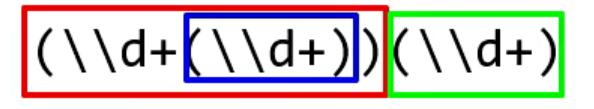
这个组号在正则表达式中是有实际用处的,接下来就通过几个练习来阐述。
三、捕获分组
捕获分组:把这一组的数据捕获出来,再用一次。
1)需求1:判断一个字符串的开始字符和结束字符是否一致?在这里只考虑一个字符
前面的第一个字符我不知道你写的是什么,就可以把第一个字符看做是单独的一组,结尾的时候再把第一组中的数据拿出来再用一次。

举例: a123a b456b 17891 &abc& a123b(false)

接下来开始写正则表达式,在写正则表达式之前先来回忆一下之前说过的技巧:拿着一个正确的数据,从左往右依次去写。
例如:a123a ,我可以将它分成三个部分 a 123 a。
一部分是开始,可以是字母,可以是数字也可以是负号,也就是说可以是任意的,写一个 (.) 就行了,这就表示:首字母可以是任意的,而且我现在将首字母当成了是第一组。
String regex1 = "(.)";
第二部分是中间的,中间可以是任意的,并且至少出现一次,.+ 就OK。
String regex1 = "(.).+";
第三部分是末尾,注意,末尾就不能再写 . 了,如果你此时再写 .,就表示任意的字符,这样就跟第一组没什么关联了,在末尾得写:\\1,表示:我要把第一组的数据拿出来再用一次。
\\组号:表示把第X组的内容再拿出来用一次。
String regex1 = "(.).+\\1";
System.out.println("a123a".matches(regex1)); // true
System.out.println("b456b".matches(regex1)); // true
System.out.println("17891".matches(regex1)); // true
System.out.println("&abc&".matches(regex1)); // true
System.out.println("a123b".matches(regex1)); // false
2)需求2:判断一个字符串的开始部分和结束部分是否一致?这里可以有多个字符
需求2就是在需求1的基础上增加了一点点
举例: abc123abc b456b 123789123 &!@abc&!@ abc123abd(false)
第一部分任意的字符至少出现一次,.+ 就行了。
然后再写中间的这部分,和后面部分
String regex2 = "(.+).+\\1";
System.out.println("a123a".matches(regex1)); // true
System.out.println("b456b".matches(regex1)); // true
System.out.println("17891".matches(regex1)); // true
System.out.println("&abc&".matches(regex1)); // true
System.out.println("a123b".matches(regex1)); // false
3)需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致
举例: aaa123aaa bbb456bbb 111789111 &&abc&&
在书写的时候还是把它分成三部分。
首先来写开始部分,开始部分肯定也要把它分为一组,并且字符可以是任意的,因此写个 . 就行了。
但是后面有多个字符,能写 .+ 吗?肯定不行,因为 .+ 表示任意的字符至少出现一次,如果是 abc,它也是满足的;
但是题目要求了:开始部分内部每个字符也需要一致,必须要 aaa 才能满足。
那怎么办呢?
注意,当你在正则表达式中看见:XXX需要一致,此时就需要用到我们上面所说的捕获分组:要把XXX数据看做一组,然后把这一组的数据再用一次,这样才能一致,数据才能重复。
因此我们可以这么写:将第一个字符单独看做一组
String regex3 = "(.)";
而这个字符需要反复出现,所以这里可以写 \\1。
String regex3 = "(.)\\1";
那到底出现多少次呢?不知道,这个是没有上限的,因此我们在后面写个 * 就行了。
* 表示 0次或多次。
要注意的是,这里的 * 控制的是这里的 \\1,它表示重复的内容可以不出现,也可以出现多次。
String regex3 = "(.)\\1*";
再来写第二部分,第二部分很简单,就是 .+
String regex3 = "(.)\\1*.+";
最后一部分:将前面 (.)\\1* 这个整体,还需要再拿出来用,有的人说:这还不简单,再将这一堆括起来不就行了吗?
String regex3 = "((.)\\1*).+";
但是你要注意了,括起来之后,里面的需要就需要变成 2 了。
因为组号是以左括号为基准,最先出现的就是第一组。
String regex3 = "((.)\\2*).+";
在后面,就要写 \\1,下面就是最终的结果了
String regex3 = "((.)\\2*).+\\1";
System.out.println("aaa123aaa".matches(regex3)); // true
System.out.println("bbb456bbb".matches(regex3)); // true
System.out.println("111789111".matches(regex3)); // true
System.out.println("&&abc&&".matches(regex3)); // true
System.out.println("aaa123aab".matches(regex3)); // false
刚刚我们已经学会了正则表达式中的捕获分组,当我们在正则表达式中后续还需要使用本组内容的时候,就可以用到它了。
在正则表达式内部可以使用 \\组号 的形式来使用;但是在正则表达式的外面,它也是可以用组里面的信息的:使用的时候用 $组号 来进行体现。
4)练习:口吃替换
需求:将字符串:我要学学编编编编程程程程程程。
替换为:我要学编程
相当于将重复的字去掉,只留下一个字就行了。
题目说了替换,那肯定要用到方法。
首先定一个字符串,把原来的大串放这里
String str = "我要学学编编编编程程程程程程";
然后再用 str 去调用方法,注意调用的是 replaceAll()。
如果用的是 replace(),它方法的形参叫做 target,这是不识别正则表达式的,因此需要使用下面的 replaceAll(),它的形参是 regex,是识别正则表达式的。

写正则之前,需要先想清楚需求:把重复的内容,替换成单个的
因此现在我们要做的是,先把前面重复的东西去写一个正则表达式。
我们可以把重复部分的首字母,单独去分成一组:(.),这一组是第一组,因此就是 \\1。而
str.replaceAll("(.)");
现在我需要将第一组的拿出来再用,再用的时候出现几次比较好?是不是至少出现一次
String result = str.replaceAll("(.)\\1+");
那我们要替换成谁呢?应该替换成:第一组的内容,因此这里我需要继续使用第一组的东西,因此这里写 $1 就行了。
$ 表示:把正则表达式中第一组的内容,再拿出来用,但是由于现在是在正则表达式的外面用的,因此不能用 \\1,而是 $1 。
String result = str.replaceAll("(.)\\1+", "$1");
System.out.println(result); // 我要学编程
四、非捕获分组
捕获分组就是:我可以把数据用括号括起来,后续如果还要继续使用本组数据的时候,可以用 \\组号 或者 $组号 的形式再次使用。
但是在有些情况下,我仅仅是要把数据括起来,在以后不需要再使用本组的数据了,这个就叫做非捕获分组。
它的格式我们之前见过,它就是将数据仅仅括起来,而且它是不占用这里的组号的。

非捕获分组:分组之后不需要再用本组数据,仅仅是把数据括起来,不占用组号。
身份证号码: 41080119930228457x
510801197609022309
15040119810705387X
130133197204039024
430102197606046442
下面是复制粘贴过来的 简易版校验身份证号码。
String regex1 ="[1-9]\\d{16}(\\d|X|x)}";
在 (\\d|X|x) 中,我仅仅是想把它括起来而已,在以后,我不想用里面的数据,此时就可以在左括号的后面加一个 ?:,这种方式就叫做 非捕获分组,它的特点是:不占用组号。
String regex1 ="[1-9]\\d{16}(?:\\d|X|x)}";
但如果你后面还写一个 \\1,它就会报错。
这里 \\1 报错原因 :(?:) 就是非捕获分组,此时是不占用组号的。
也就是说此时它压根就不知道谁是第一组

除此之外,(?:) (?=) (?!)都是非捕获分组。
但一般情况下更多的使用第一个 ?:,之前我们将 ?: 的时候曾经说了,这里的 ? 相当于前面所有数据,: 指的就是前面的数据 [1-9]\\d{16} 后面跟随的就是 \\d|X|x,那么匹配获取的时候,获取的是整体,因此更多的使用第一个 ?:。
那能不能不写呢?可以不写,那为什么还要讲呢?
这是因为我们百度搜出来的一些正则表达式,还有插件中找到的正则表达式都有写,如果不讲,我们就看不懂。
五、总结
1、正则表达式中分组有两种
捕获分组、非捕获分组
2、捕获分组(默认情况)
捕获分组可以获取每组中的内容,反复使用。
在正则表达式内部可以使用 \\组号 的形式来使用;但是在正则表达式的外面,它也是可以用组里面的信息的:使用的时候用 $组号 来进行体现。
3、组号的特点
规则1:从 1 开始,连续不间断。
规则2:以左括号为基准,最左边的是第一组,其次为第二组,以此类推。
4、非捕获分组
非捕获分组:分组之后不需要再用本组数据,仅仅是把数据括起来,不占用组号。
(?:) 、(?=)、(?!) 都是非捕获分组。
















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









