







文章目录
概念:终结操作的意思是,执行完此方法之后,Stream流将不能再执行其他操作
一、总述
常见的终结方法会有以下四个
| 方法名 | 说明 |
|---|---|
void forEach(Consumer action) | 遍历 |
long count() | 统计 |
toArray() | 收集流中的数据,放到数组中 |
collect(Collector collector) | 收集流中的数据,放到集合中 |
思考为什么要收集?
我们使用 Stream流 可以用来处理 集合 / 数组 中的数据,那你处理完了之后,肯定要将这些数据保存起来,因此我们需要将它们收集起来。
二、遍历
void forEach(Consumer action)
代码示例
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "周芷若", "赵敏", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
//用list调用stream()获取到一个流水线,并把集合里面的数据放到流水线上
list.stream()
可以发现 forEach() 的返回值是 void,因此调用 forEach() 结束后就不能调用流里面的其他方法了,它是终结方法。

跟进 forEach() ,可以发现它的形参是 Consumer,继续跟进 Consumer。
发现它是一个函数式接口,因此一会我们会将它改写成 Lambda表达式。
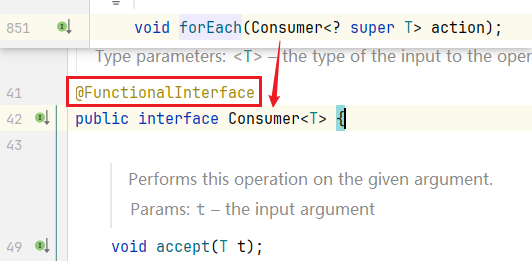
我们先写匿名内部类
//Consumer的泛型:表示流中数据的类型
//accept方法的形参s:依次表示流里面的每一个数据
//方法体:对每一个数据的处理操作(打印)
list.stream().forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
改写为 Lambda表达式
list.stream().forEach(s -> System.out.println(s));
三、统计
long count()
count() 的返回值是一个 long类型 的整数,因此 count() 结束后,也不能再调用流里面的其他方法了,它也是一个终结方法。

long count = list.stream().count();
System.out.println(count); // 9
四、收集流中的数据,放到数组中
toArray()
调用 toArray() 的时候会有两个,最简单的是空参的,表示我们需要收集到 Object类型 的数组中。
但是我们需要的是放到具体类型的数组中,就可以使用下面的方法。

首先来讲最简单的空参,返回的是 Object类型 的数组中。
Object[] arr1 = list.stream().toArray();
System.out.println(Arrays.toString(arr1));
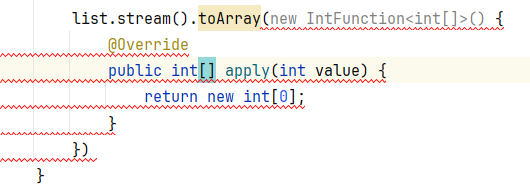
接下来讲有参的,跟进 toArray() 往下滑

点击 IntFunction,可以发现它也是一个函数式接口

这里先写匿名内部类
list.stream().toArray(new IntFunction<? extends Object[]>() {
@Override
public Object[] apply(int value) {
return new Object[0];
}
});
这个接口相对来将比较复杂。
IntFunction 的泛型是 ? extends Object[],前面的 ? extends Object 表示数据的类型,后面的 [] 表示数组,因此这个整体就表示具体类型的数组。
由于我们要的是 String 类型的,因此写 String[] 就行了。
list.stream().toArray(new IntFunction<String[]>() {
@Override
public Object[] apply(int value) {
return new Object[0];
}
});
接下来看里面的 apply()。
apply的形参:流中数据的个数,要跟数组的长度保持一致
apply的返回值:具体类型的数组,这个需要跟IntFunction的泛型类型对应
方法体:就是创建数组
toArray方法的参数的作用:负责创建一个指定类型的数组
toArray方法的底层,会依次得到流里面的每一个数据,并把数据放到数组当中
toArray方法的返回值:是一个装着流里面所有数据的数组
String[] arr = list.stream().toArray(new IntFunction<String[]>() {
@Override
public String[] apply(int value) {
return new String[value];
}
});
System.out.println(Arrays.toString(arr)); // [张无忌, 周芷若, 赵敏, 张强, 张三丰, 张翠山, 张良, 王二麻子, 谢广坤]
改写成 Lambda表达式
String[] arr2 = list.stream().toArray(value -> new String[value]);
System.out.println(Arrays.toString(arr2)); // [张无忌, 周芷若, 赵敏, 张强, 张三丰, 张翠山, 张良, 王二麻子, 谢广坤]
PS:如果需要转为基本数据类型的数组,泛型是不能写基本数据类型的,只能转为它的包装类
list.stream().toArray(new IntFunction<Integer[]>() {
@Override
public Integer[] apply(int value) {
return new Integer[0];
}
});
五、收集流中的数据,放到集合中
这个方法可以收集到 单列集合List / Set、双列集合Map
collect(Collector collector)
准备数据
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-男-15", "周芷若-女-14", "赵敏-女-13", "张强-男-20",
"张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41");
1)收集到 List集合 当中
需求:我要把所有的男性收集起来
PS:我们在比较的时候也可以将 s.split("-")[1] 放在前面跟 "男" 进行比较也是可以的,只不过我们在比较的时候有一个习惯:能用这种固定数据去调用的尽量就使用固定数据调用,因为前面的不可能是 null,但是后面的 s.split("-")[1] 就有可能是不确定的,不确定的东西就有可能是 null,null 的话就会导致空指针异常。
List<String> newList1 = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
// Collectors是Stream里面的工具类,它里面有个静态方法叫:tolist(),这个方法底层可以帮我们创建一个ArrayList集合,这样就可以将流里面所有的数据都放到这个ArrayList集合中了
.collect(Collectors.toList());
System.out.println(newList1); // [张无忌-男-15, 张强-男-20, 张三丰-男-100, 张翠山-男-40, 张良-男-35, 王二麻子-男-37, 谢广坤-男-41]
2)收集到 Set集合 当中
Set<String> newList2 = list.stream().filter(s -> "男".equals(s.split("-")[1]))
// toSet() 底层会帮我们创建一个HashSet集合,并将流里面的数据放到这个HashSet集合中
.collect(Collectors.toSet());
System.out.println(newList2);
3)收集到 List集合、Set集合 中的区别
当我将 list 集合中的数据改为
"张无忌-男-15", "张无忌-男-15", "周芷若-女-14", "赵敏-女-13", "张强-男-20",
"张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41"
此时数据就重复了,这时我们将 newList1 和 newList2 同时打印。
可以发现如果将数据收集到 HashSet 中,数据会去重。
System.out.println(newList1); // [张无忌-男-15, 张无忌-男-15, 张强-男-20, 张三丰-男-100, 张翠山-男-40, 张良-男-35, 王二麻子-男-37, 谢广坤-男-41]
System.out.println(newList2); // [张强-男-20, 张良-男-35, 张三丰-男-100, 张无忌-男-15, 谢广坤-男-41, 张翠山-男-40, 王二麻子-男-37]
4)收集到 Map集合 当中
收集到 Map 时,需要规定一件事情:谁作为键,谁作为值。
需求:
我要把所有的男性收集起来
键:姓名。 值:年龄。
性别就不要了,因为既然是将所有的男性收集起来,那么收集起来的肯定是男性。
在 toMap() 中,我们需要传入键和值的规则
//收集Map集合当中
//谁作为键,谁作为值.
//我要把所有的男性收集起来
//键:姓名。 值:年龄
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(键的规则, 值的规则);
跟进 toMap() 看一下,可以发现集合中有两个形参,形参一:keyMapper(键的规则),形参二:valueMapper(值的规则)。
在底下有一段代码,虽然我们看不懂,但是可以猜。
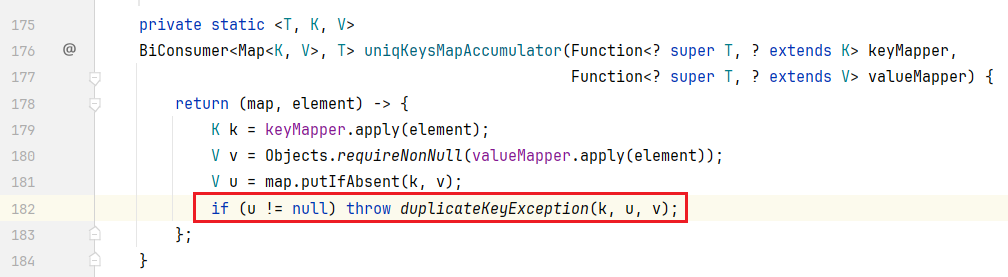
HashMap::new:new 了一个 HashMap,然后将键、值的规则传递进去,传递给 uniqKeysMapAccumulator()
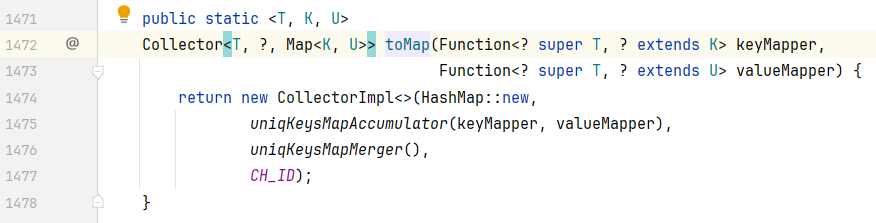
跟进 uniqKeysMapAccumulator(),可以看见它里面调用了 putIfAbsent(),将数据添加到 Map集合 中。
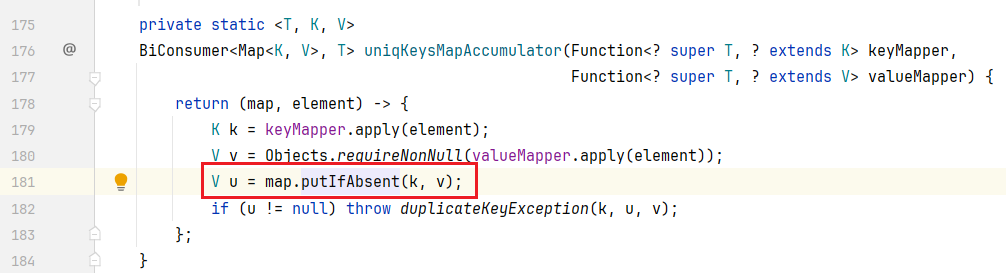
Function接口 和 apply() 的对应关系如下
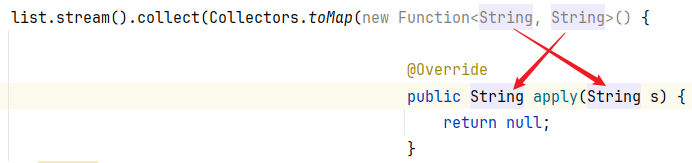
注意点:如果我们要收集到Map集合当中,键不能重复,否则会报错。

报错的原因就是因为它底层调用了 putIfAbsent(),这个方法里面会做一个判断:根据键先找值,如果值为 null,表示当前的键是不存在的,此时就将数据添加到 Map集合 中,但是在添加第二次的时候,这里的 v 就不是 null 了,直接返回 v。
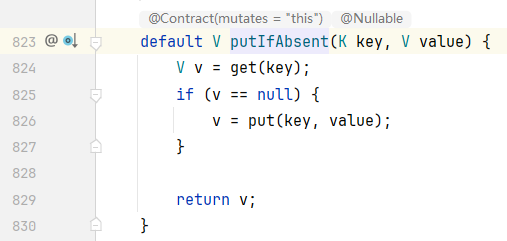
ctrl + alt + ← 返回上一步,可以发现它在下面又做了一个判断:如果 u 不是 null,它就会产生异常
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
/*
* toMap : 参数一表示键的生成规则
* 参数二表示值的生成规则
*
* 参数一:
* Function泛型一:表示流中每一个数据的类型
* 泛型二:表示Map集合中键的数据类型
*
* 方法apply形参:依次表示流里面的每一个数据
* 方法体:生成键的代码
* 返回值:已经生成的键
*
*
* 参数二:
* Function泛型一:表示流中每一个数据的类型
* 泛型二:表示Map集合中值的数据类型
*
* 方法apply形参:依次表示流里面的每一个数据
* 方法体:生成值的代码
* 返回值:已经生成的值
*
* */
.collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
//张无忌-男-15
return s.split("-")[0];
}
},
new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}));
改写为 lambda表达式
Map<String, Integer> map2 = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[2])));
















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









