







Redis队列Stream
前置说明:Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的支持多播的可持久化的消息队列,作者声明 Redis Stream 地借鉴了 Kafka 的设计。
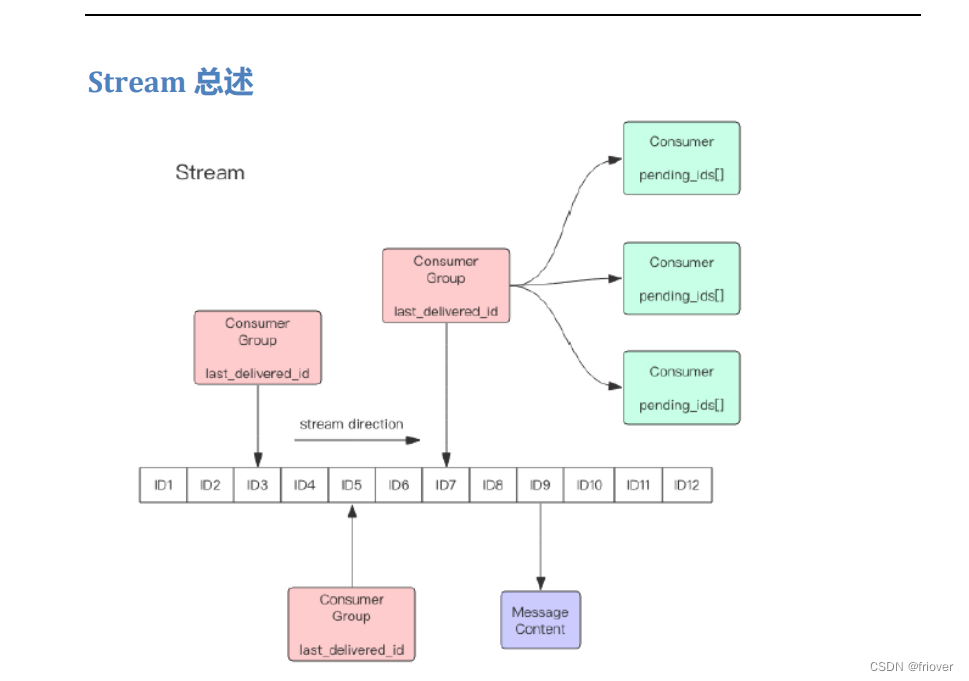
- Redis Stream 的结构如上图所示,每一个Stream都有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。消息是持久化的,Redis 重启后,内容还在。
- 每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用xadd指令追加消息时自动创建。
- 每个 Stream 都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个 Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从 Stream 的某个消息 ID开始消费,这个ID 用来初始化last_delivered_id变量。
- 每个消费组 (Consumer Group) 的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
- 同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往 前移动。每个消费者有一个组内唯一名称。
- 消费者 (Consumer) 内部会有个状态变量 pending_ids,它记录了当前已经被客户端读取,但是还没有 ack 的消息。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为 PEL,也就是 Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
- 消息 ID 的形式是 timestampInMillis-sequence,例如 1527846880572-5,它表示当前的消息在毫米时间戳 1527846880572 时产生,并且是该毫秒内产生的第5 条消息。消息 ID 可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的 ID 要大于前面的消息 ID。
- 消息内容就是键值对,形如 hash 结构的键值对
常用操作命令
生产端
xadd 追加消息
xdel 删除消息,这里的删除仅仅是设置了标志位,不会实际删除消息。
xrange 获取消息列表,会自动过滤已经删除的消息
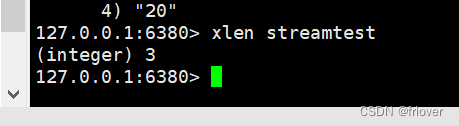
xlen 消息长度
del 删除 Stream
例如:

- streamtest 表示这个队列的名字
- *表示服务器自动生成id,一般建议自动生成
- 后面是我们对消息存入的键值对
- 返回值是生成的消息 ID,它由两部分组成:时间戳-序号。时间戳时毫秒级单位,是生成消息的 Redis 服务器时间,它是个 64 位整型。序
号是在这个毫秒时间点内的消息序号。(因为redis一条命令是纳秒级别的,所以需要时间戳加号码确定唯一 一条消息)
为了保证消息是有序的,因此 Redis 生成的 ID 是单调递增有序的。由于 ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis 的每个 Stream 类型数据都维护一个 latest_generated_id 属性,用于记录最后一个消息的 ID。若发现当前时间戳退后(小于 latest_generated_id 所记录的),则采用时间戳不变而序号递增的方案来作为新消息 ID(这也是序号为什么使用 int64 的原因,保证有足够多的的序号),从而保证 ID 的单调递增性质。
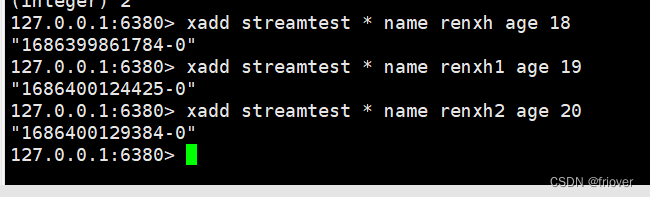
在插入两条数据,此刻这队列一共三条数据
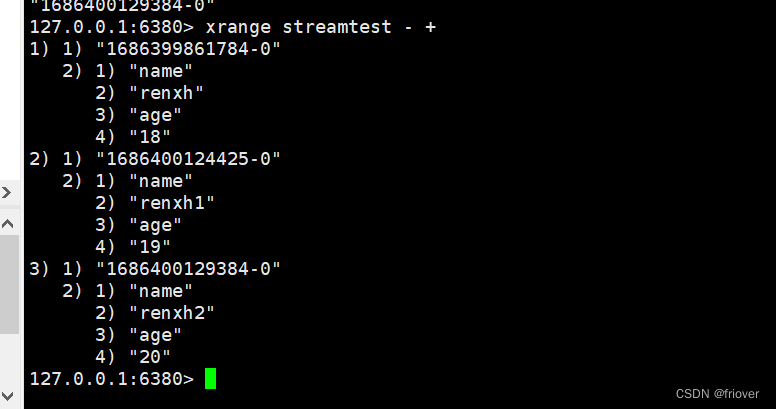
#其中-表示最小值 , + 表示最大值
xrange streamtest - +
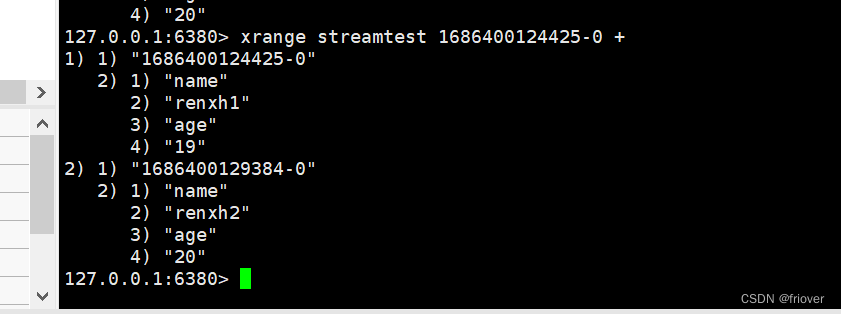
或者我们可以指定消息 ID 的列表:
#复制编号,从第二条查询
xrange streamtest 1686400124425-0 +
#查看消息队列长度
xlen streamtest
#删除消息
xdel streamtest 1686400124425-0

消费端
- 单消费者
虽然 Stream 中有消费者组的概念,但是可以在不定义消费组的情况下进行Stream 消息的独立消费,当 Stream 没有新消息时,甚至可以阻塞等待。Redis 设计了一个单独的消费指令 xread,可以将 Stream 当成普通的消息队列 (list) 来使用。使用 xread 时,我们可以完全忽略消费组 (Consumer Group) 的存在,就好比 Stream 就是一个普通的列表 (list)。
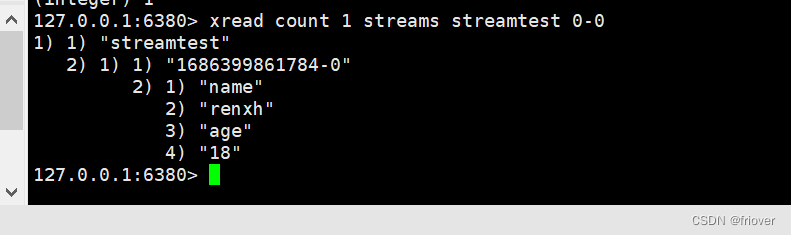
xread count 1 streams streamtest 0-0
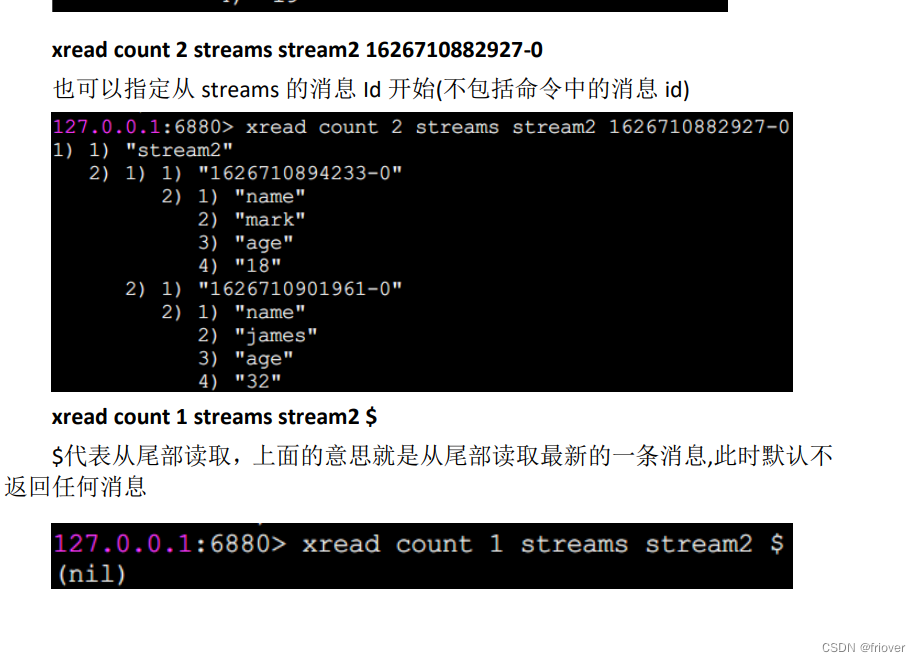
所以最好以阻塞的方式读取尾部最新的一条消息,直到新的消息的到来
xread block 0 count 1 streams streamtest $


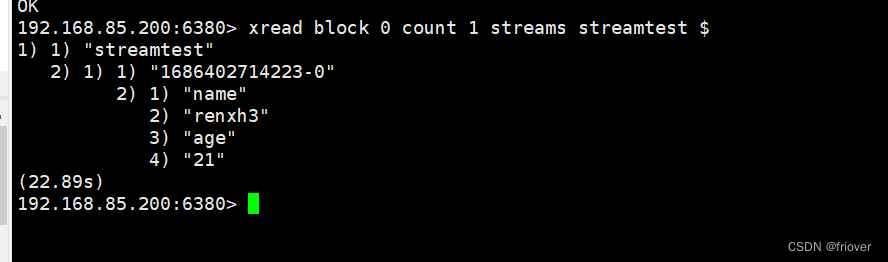
可以看到阻塞解除了,返回了新的消息内容,而且还显示了一个等待时间,这里我们等待了 22s
一般来说客户端如果想要使用 xread 进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息 ID。下次继续调用 xread 时,将上次返回的最后一个消息 ID 作为参数传递进去,就可以继续消费后续的消息。
消费组
创建消费组
Stream 通过 xgroup create 指令创建消费组 (Consumer Group),需要传递起始消息 ID 参数用来初始化 last_delivered_id 变量。
#“streamtest”指明了要读取的队列名称,“cg1”表示消费组的名称,
#“0-0”表示从头开始消费
xgroup create streamtest cg1 0-0
# $表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略
xgroup create streamtest cg2 $

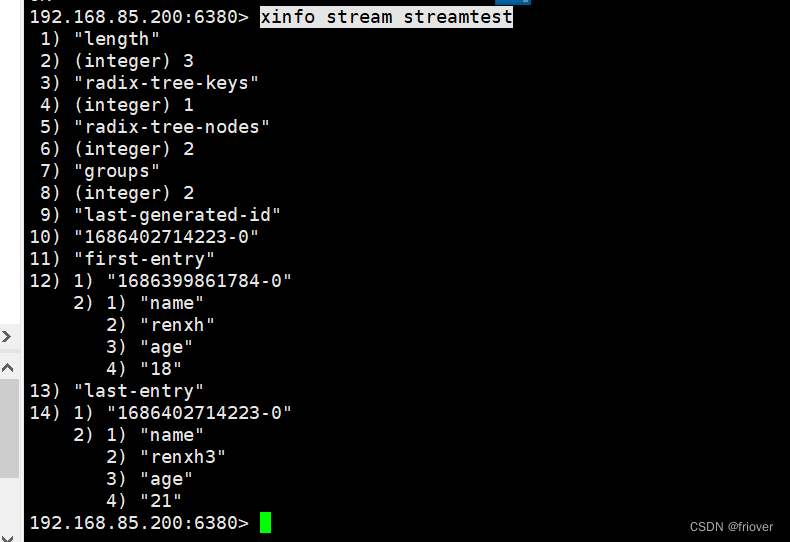
# 1 2可以看到消费队列长度,9 10可以看到最后生成消息id,7 8可以看到有两个消费组
xinfo stream streamtest
消息消费
有了消费组,自然还需要消费者,Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息 ID。
它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的 PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除。
#“GROUP”属于关键字,“cg1”是消费组名称,“c1”是消费者名称,“count
#1”指明了消费数量,> 号表示从当前消费组的 last_delivered_id 后面开始
#读,每当消费者读取一条消息,last_delivered_id 变量就会前进
xreadgroup group cg1 c1 count 1 streams streamtest >

在一直读的时候很快就把插入的三条信息读完了
然后设置阻塞等待
xreadgroup GROUP cg1 c1 block 0 count 1 streams streamtest >


回到原来的客户端,发现阻塞解除,收到新消息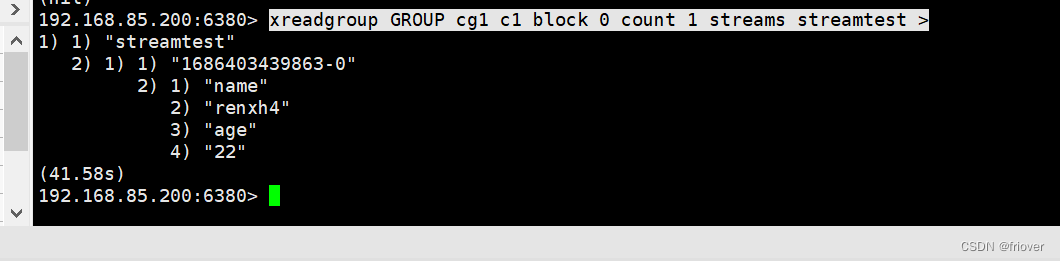
我们来观察一下观察消费组状态
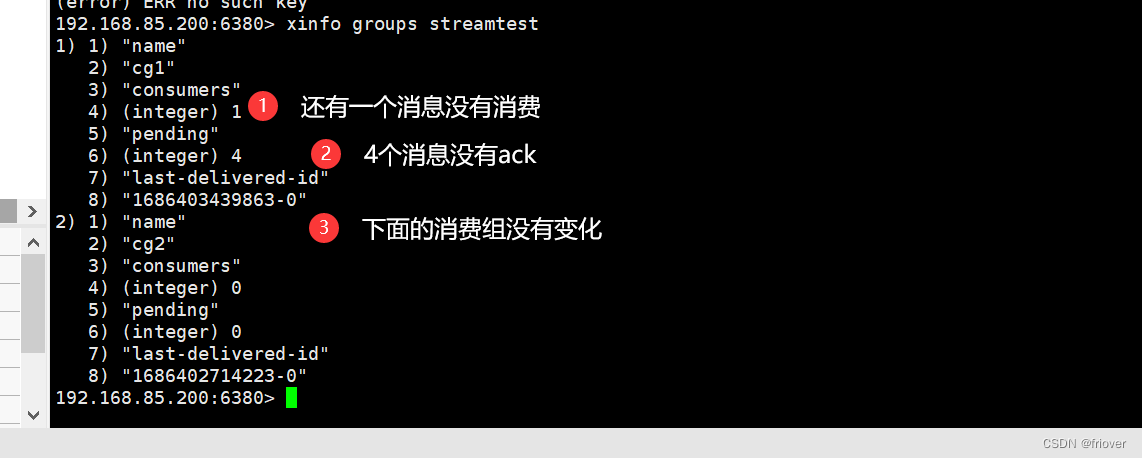
如果同一个消费组有多个消费者,我们还可以通过 xinfo consumers 指令观察每个消费者的状态
xinfo consumers streamtest cg1
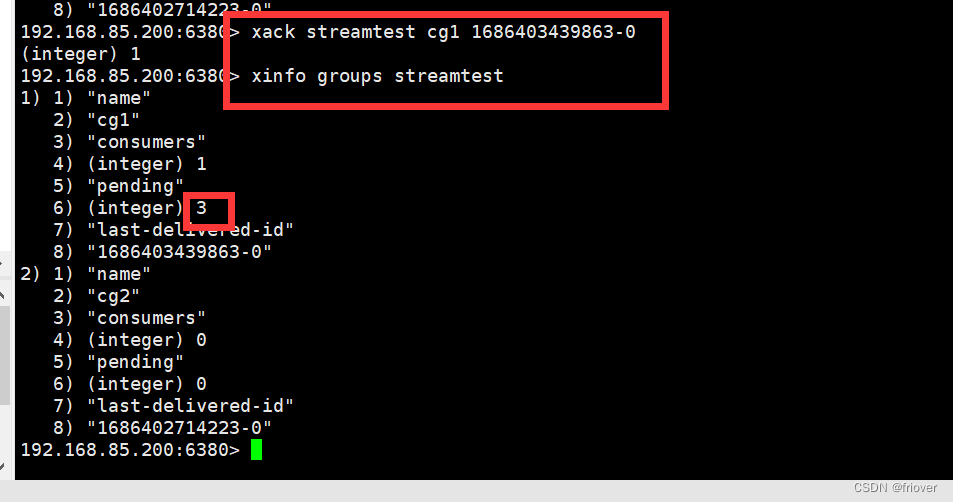
如果我们确认一条消息,发现就还有三条没有ack确认
xack streamtest cg1 1686403439863-0


Redis 中的线程和 IO 模型
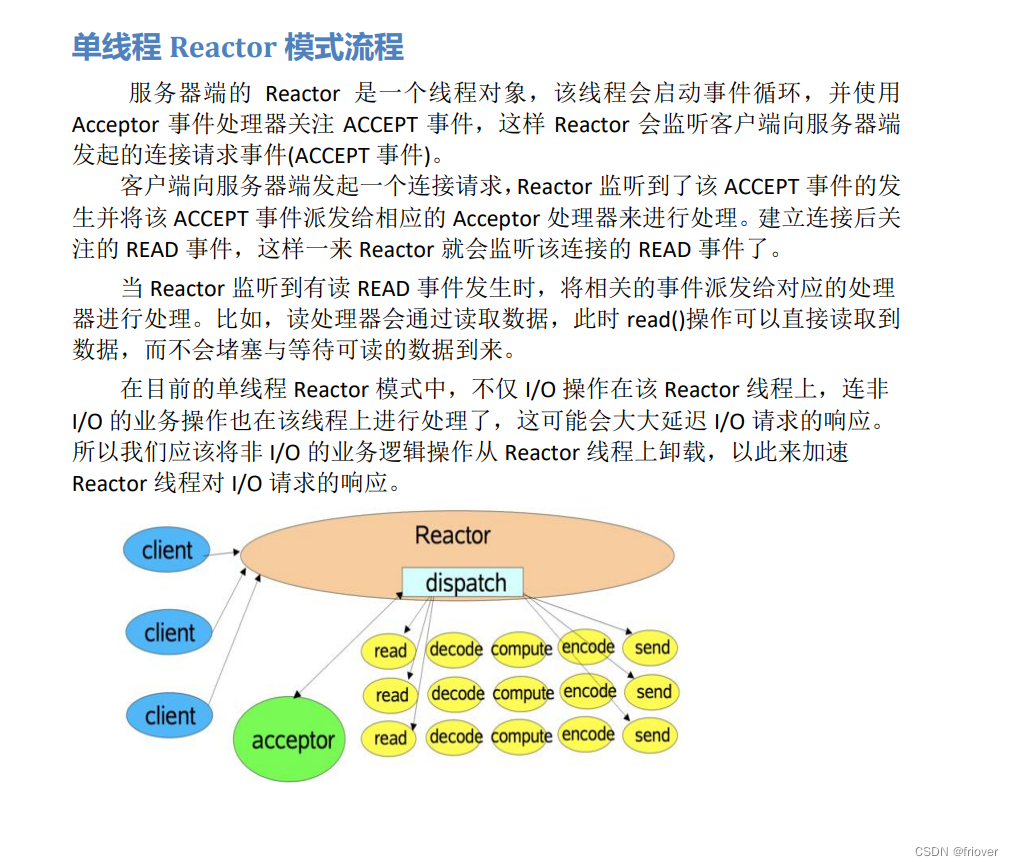
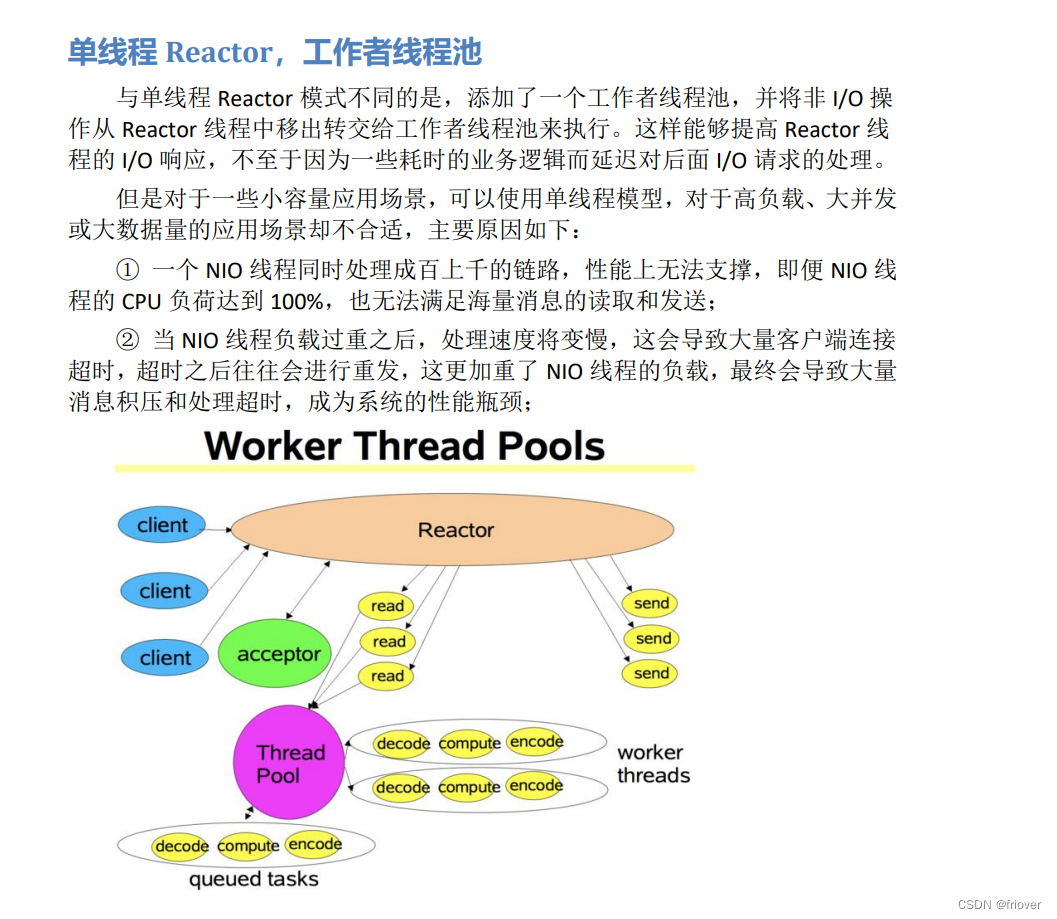
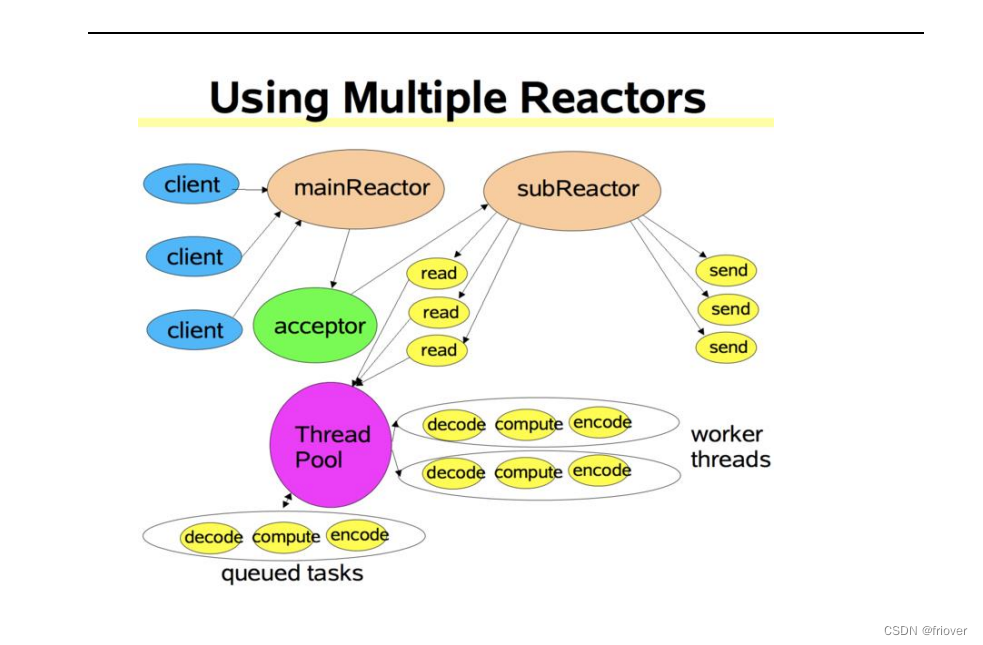
什么是 Reactor 模式 ?
“反应”器名字中”反应“的由来:
“反应”即“倒置”,“控制逆转”,具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有时间来了,具体事件处理程序通过事件处理器对某个指定的事件发生做出反应;这种控制逆转又称为“好莱坞法则”(不要调用我,让我来调用你)

Redis 中的线程和 IO 概述

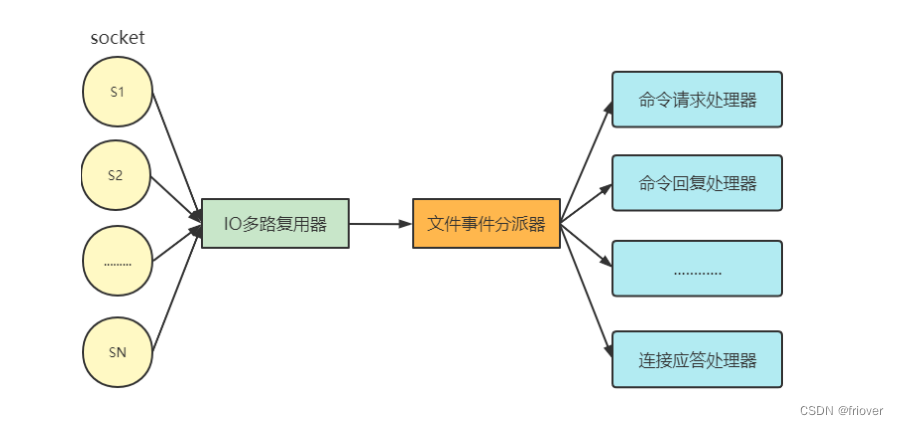

I/O 多路复用程序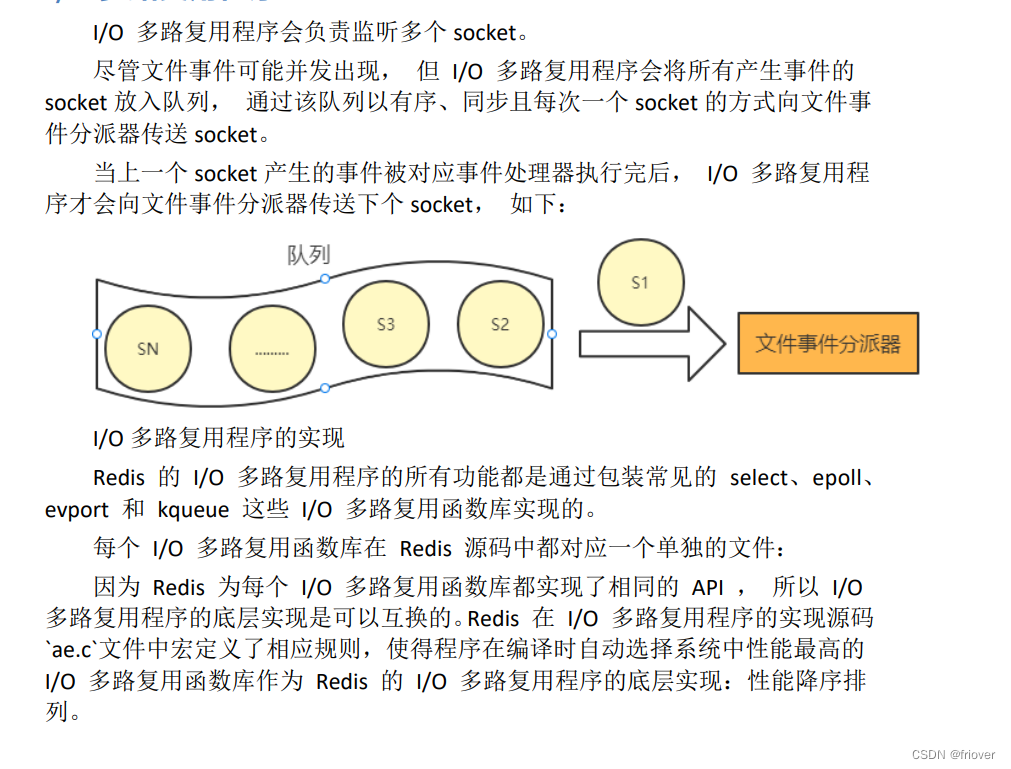
文件事件分派器
- 文件事件分派器接收 I/O 多路复用程序传来的 socket, 并根据 socket 产生的事件类型, 调用相应的事件处理器。
文件事件处理器
- 服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
- Redis 为各种文件事件需求编写了多个处理器,若客户端连接 Redis,对连接服务器的各个客户端进行应答,就需要将 socket映射到连接应答处理器写数据到 Redis,接收客户端传来的命令请求,就需要映射到命令请求处理器从 Redis读数据,向客户端返回命令的执行结果,就需要映射到命令回复处理器当主服务器和从服务器进行复制操作时, 主从服务器都需要映射到特别为复制功能编写的复制处理器。
文件事件的类型
I/O 多路复用程序可以监听多个 socket 的 ae.h/AE_READABLE 事件和
ae.h/AE_WRITABLE 事件, 这两类事件和套接字操作之间的对应关系如下:
当 socket 可读(比如客户端对 Redis 执行 write/close 操作),或有新的可应答的 socket 出现时(即客户端对 Redis 执行 connect 操作),socket 就会产生一个 AE_READABLE 事件。
当 socket 可写时(比如客户端对 Redis 执行 read 操作),socket 会产生一个AE_WRITABLE 事件。
I/O 多路复用程序可以同时监听 AE_REABLE 和 AE_WRITABLE 两种事件,要是一个 socket 同时产生这两种事件,那么文件事件分派器优先处理 AE_REABLE 事件。即一个 socket 又可读又可写时, Redis 服务器先读后写 socket。

Redis6 中的多线程
1. Redis6.0 之前的版本真的是单线程吗?
Redis 在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返回 (socket 写)等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。
但如果严格来讲从 Redis4.0 之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等。
2. Redis6.0 之前为什么一直不使用多线程?
官方曾做过类似问题的回复:使用 Redis 时,几乎不存在 CPU 成为瓶颈的情况, Redis 主要受限于内存和网络。例如在一个普通的 Linux 系统上,Redis 通过使用 pipelining 每秒可以处理 100 万个请求,所以如果应用程序主要使用 O(N)或O(log(N))的命令,它几乎不会占用太多 CPU。
使用了单线程后,可维护性高。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。Redis通过 AE 事件模型以及 IO 多路复用等技术,处理性能非常高,因此没有必要使用多线程。单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性Rehash、Lpush 等等 “线程不安全” 的命令都可以无锁进行。
3. Redis6.0 为什么要引入多线程呢?
Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,Redis 服务器可以处理 80,000 到 100,000 QPS,这也是 Redis 处理的极限了,对于 80%的公司来说,单线程的 Redis 已经足够使用了
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。
常见的解决方案是在分布式架构中对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的 Redis 服务器太多,维护代价大;某些适用于单个 Redis 服务器的命令不适用于数据分区;数据分区无法解决热点读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从 Redis 自身角度来说,因为读写网络的 read/write 系统调用占用了 Redis执行期间大部分 CPU 时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
• 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
• 使用多线程充分利用多核,典型的实现比如 Memcached。协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis 支持多线程主要就是两个原因:
• 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
• 多线程任务可以分摊 Redis 同步 IO 读写负荷
4. Redis6.0 默认是否开启了多线程?
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改
redis.conf 配置文件:io-threads-do-reads yes

开启多线程后,还需要设置线程数,否则是不生效的。
关于线程数的设置,官方有一个建议:4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为 6 个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了 8 个基本就没什么意义了。
5.Redis6.0 采用多线程后,性能的提升效果如何?
Redis 作者 antirez 在 RedisConf 2019 分享时曾提到:Redis 6 引入的多线程IO 特性对性能提升至少是一倍以上。国内也有大牛曾使用 unstable 版本在阿里云 esc 进行过测试,GET/SET 命令在 4 线程 IO 时性能相比单线程是几乎是翻倍了。如果开启多线程,至少要 4 核的机器,且 Redis 实例已经占用相当大的 CPU耗时的时候才建议采用,否则使用多线程没有意义。
6.Redis6.0 多线程的实现机制?

7.开启多线程后,是否会存在线程并发安全问题?
从上面的实现机制可以看出,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以我们不需要去考虑控制key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。















 3080
3080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











