









第三章介绍了计算机图形学的基本概念。那一章的主要主题是如何使用表面原语(如点、线和多边形)表示和渲染几何。在本章中,我们主要关注体积图形。与表面图形相比,体图形在呈现非均匀材料方面具有更大的表达范围,是三维图像(体)数据集可视化的主要技术。本章的开始,我们将介绍两种对表面图形和体积图形都很重要的技术。它们使用简单的混合函数来模拟物体透明度,并使用纹理映射来增加真实感,而不需要过多的计算成本。我们还描述了这些技术固有的各种问题和挑战。然后,我们将重点讨论体积图形,包括对象顺序和图像顺序技术,照明模型,混合表面和体积图形的方法,以及提高性能的方法。最后,本章总结了创建更逼真的可视化的各种重要技术。这些技术包括立体观看、抗锯齿和高级相机技术,如运动模糊、焦距模糊和相机运动。
7.1透明度和Alpha值
到目前为止,我们一直专注于渲染不透明物体——也就是说,我们已经假设物体在其表面反射、散射或吸收光线,并且没有光线通过它们的内部传输。虽然渲染不透明的对象肯定是有用的,但是有很多第7章的超新星数据集的体渲染。214先进的计算机图形应用程序,可以受益于渲染传输光的物体的能力。透明的一个重要应用是体绘制,我们将在本章后面更详细地探讨它。另一个简单的例子是让物体变成半透明的,这样我们就可以看到被表面包围的区域内部,如图12 - 4所示。如本例所示,通过使皮肤半透明,可以看到内部器官。
透明度和它的补充,不透明度,经常被称为阿尔法在计算机图形。例如,一个50%不透明的多边形的alpha值在0到1的范围内为0.5。alpha值为1表示不透明对象,0表示完全透明对象。通常,alpha被指定为整个参与者的属性,但它也可以像颜色一样在顶点基础上完成。在这种情况下,颜色的RGB规范被扩展为RGBA,其中a代表alpha分量。在许多显卡上,帧缓冲区可以存储alpha值和RGB值。更典型的情况是,应用程序只请求存储显卡上的红色、绿色和蓝色,并使用前后混合来避免存储alpha。
不幸的是,使用透明角色会给呈现过程带来一些复杂性。如果你回想一下光线追踪的过程,观察光线从相机投射到世界上,在那里它们与第一个actor相交。使用不透明actor,应用照明方程,并将结果颜色绘制到屏幕上。对于一个半透明的actor,我们必须解决这个actor的照明方程,然后继续将光线投射到更远的地方,看看它是否与任何其他actor相交。产生的颜色是它所相交的所有actor的合成。对于每个曲面交点,这可以表示为公式7-1。
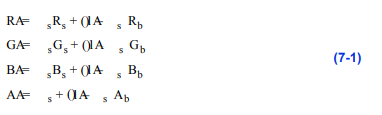
在这个方程中,下标s指的是参与者的表面,而下标b指的是参与者背后的东西。这个术语被称为透射率,它代表了通过行动者传输的光的量。例如,考虑从三个颜色为红色、绿色和蓝色的多边形开始,每个多边形的透明度为0.5。如果红色多边形在前面,背景是黑色的,得到的RGBA颜色将是(0.4,0.2,0.1,0.875),从0到1(图7 - 1)。
需要注意的是,如果我们切换多边形的顺序,得到的颜色将会改变。这是使用透明度的一个主要技术问题。如果我们用光线追踪一个场景,我们将以一种定义良好的方式——从前到后——交叉表面。利用这些知识,我们可以追踪一条射线到它相交的最后一个曲面,然后通过将公式7-1应用到所有反顺序的曲面(即从后到前)来合成颜色。在对象顺序呈现方法中,这种合成通常在硬件中得到支持,但不幸的是,我们不能保证以任何特定的顺序呈现多边形。即使我们的多边形位于图7 - 1中,多边形渲染的顺序可能是蓝色多边形,其次是红色多边形,最后是绿色多边形。因此,得到的颜色是不正确的。
如果我们观察一个像素的RGBA值,我们就能发现问题所在。当蓝色多边形被渲染时,帧缓冲区和z缓冲区是空的,所以RGBA四边形(0,0,0.8,0.5)被存储
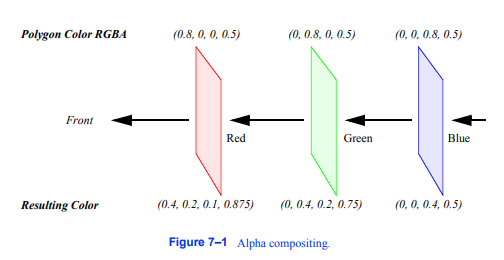
它的z-buffer值。当渲染红色多边形时,它的z值与当前z缓冲区的比较表明它在前一个像素条目的前面。因此,公式7-1使用帧缓冲区的RGBA值应用。这将导致RGBA值(0.4,0,0.2,0.75)被写入缓冲区。现在,绿色多边形被渲染,z比较表明它落后于当前像素的值。再次应用这个方程,这一次使用帧缓冲区的RGBA值的表面和多边形的值从后面。这将导致最终像素颜色为(0.3,0.2,0.175,0.875),这与我们之前计算的不同。一旦红色和蓝色多边形被合成并写入帧缓冲区,就无法将最后的绿色多边形插入到它所属的中间位置。
这个问题的一个解决方案是将多边形从后到前排序,然后按此顺序渲染它们。通常,这必须在需要额外计算开销的软件中完成。排序还会干扰参与者属性(比如高光功率),这些属性通常在呈现参与者多边形之前被发送到图形引擎。一旦我们开始混合不同参与者的多边形,我们必须确保为渲染的每个多边形设置正确的参与者属性。
另一种解决方案是在帧缓冲区中存储多组RGBAZ值。由于额外的内存需求,这是昂贵的,并且仍然受限于您可以存储的RGBAZ值的数量。一些新技术使用多个RGBAZ值存储和多通道渲染的组合来生成正确的结果,并且性能损失最小[Hodges92]。
渲染透明对象的第二个技术问题出现的频率较低,但仍然可能造成灾难性的影响。在某些应用程序中,例如体绘制,需要有成千上万个alpha值较小的多边形。如果RGBA四边形作为四个8位值存储在帧缓冲区中,那么四舍五入会在许多多边形上累积,导致输出图像中的严重错误。如果图形硬件开始为每个组件存储16位或更多的纹理和帧缓冲区,这在将来可能就不是什么问题了。
7.2纹理映射
纹理映射是一种为图像添加细节而不需要建模细节的技术。纹理映射可以被认为是将图片粘贴到对象的表面。使用纹理映射需要两个信息:纹理映射和纹理坐标。纹理映射是我们粘贴的图片,而纹理坐标指定了图片被粘贴的位置。更一般地说,纹理映射是在对象呈现时应用于对象的颜色、强度和/或透明度的表查找。纹理贴图和坐标通常是二维的,但是大多数新的图形硬件都支持三维纹理贴图和坐标。
纹理映射的值可以通过渲染木桌的简单示例来显示。桌子的基本几何形状可以很容易地创建,但实现木纹细节是困难的。把桌子涂成棕色是一个很好的开始,但图像仍然不现实。为了模拟木纹,我们需要在桌子表面上有许多小的颜色变化。使用顶点颜色将需要我们有数百万个额外的顶点来获得小的颜色变化。解决方法是将木纹纹理贴图应用到原始多边形上。这就像在廉价的刨花板上涂上一层橡木饰面,这也是电子游戏所使用的策略,即提供带有较少多边形的真实场景以实现交互性。
有几种方法可以应用纹理数据。对于纹理贴图中的每个像素(通常称为纹理元素的texel),可能有一到四个组件会影响纹理贴图如何粘贴到底层几何图形的表面上。具有一个组件的纹理映射称为强度映射。应用强度映射会导致结果像素的强度(或HSV值)发生变化。如果我们将木纹的灰度图像,然后将其纹理映射到一个棕色多边形上,我们将得到一个合理的外观表。多边形的色调和饱和度仍然由棕色决定,但强度将由纹理图决定。通过使用木材的彩色图像,可以得到一个更好看的桌子。这是一个三组分纹理映射,其中每个纹理都表示为一个RGB三元组。使用RGB地图可以让我们获得更真实的图像,因为我们将不仅仅是木材的强度变化。
通过将alpha值添加到强度图中,我们得到两个分量。我们可以对RGB纹理映射做同样的操作,以获得一个四组件的RGBA纹理映射。在这些情况下,alpha值可用于使底层几何图形的某些部分透明。计算机图形学中一个常见的技巧是使用RGBA纹理来渲染树。而不是试图建模复杂的几何树,我们只是渲染一个矩形与RGBA纹理映射应用到它。在有叶子或树枝的地方,alpha为1,在有空隙和开放空间的地方,alpha为0。因此,我们可以看到矩形的部分,给人一种通过树木的树枝和树叶观看的错觉。
除了可以定义纹理映射的不同方式外,还可以选择如何与对象的原始颜色进行交互。RGB和RGBA地图的一个常见选项是忽略原始颜色;也就是说,只应用指定的纹理颜色。另一种选择是通过纹理贴图颜色(或强度)来调制原始颜色,以产生最终颜色。
虽然我们一直专注于2D纹理映射,但它们可以是任何维度,尽管最常见的是2D和3D。三维纹理图用于作为3D空间函数的纹理,如木纹、石头或x射线强度(即CT扫描)。事实上,一个体积数据集本质上是一个3D纹理。我们可以通过让平面穿过3D纹理,并使用正确顺序的半透明alpha值来进行高速体渲染。
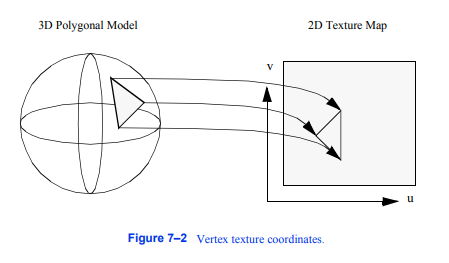
图7-2顶点纹理坐标
使用纹理映射硬件进行体绘制的技术将在本章后面讨论。纹理映射过程中的一个基本步骤是确定如何将纹理映射到几何图形上。
为了实现这一点,每个顶点除了它的位置、表面法线、颜色和其他点属性外,还有一个相关的纹理坐标。纹理坐标将顶点映射到纹理映射中,如图7 - 2所示。纹理坐标系使用参数(u,v)和(u,v,t)或等效的(r,s)或(r,s,t)来指定2D和3D纹理值。顶点之间的点被线性插值以确定纹理映射值。
纹理映射的另一种方法是使用过程性纹理定义而不是纹理映射。在这种方法中,在呈现几何图形时,为每个像素调用一个过程来计算texel值。不是使用(u,v,t)纹理坐标来索引到图像中,而是将它们作为参数传递给使用它们来计算结果的过程纹理。这种方法在纹理设计中提供了几乎无限的灵活性;因此,几乎不可能在专用硬件中实现。最常见的是,程序纹理与不大量使用现有图形硬件的软件渲染系统一起使用。
虽然纹理映射通常用于为渲染图像添加细节,但也有重要的可视化应用程序。
纹理映射可以作为数据的函数程序生成。一个例子是根据本地数据值更改曲面的外观。
纹理坐标可以作为数据的函数程序生成。例如,我们可以通过创建一个特殊的纹理映射来阈值几何,然后根据本地数据值设置纹理坐标。
纹理映射由两个条目组成:全透明()和全不透明()。然后,如果标量值小于某个阈值,纹理坐标将被设置为索引到映射的透明部分,否则将索引到不透明部分。纹理贴图可以随时间变化而动画化。通过选择一个强度从暗到亮单调变化的纹理映射,然后沿着一个对象“移动”纹理,对象看起来就像在纹理映射运动的方向上爬行。我们可以利用这项技术
图7-3使用纹理贴图的矢量场动画中的一帧
(animVectors。tcl)。
Nique为刺猬等物体添加了明显的运动来显示矢量大小。图7 - 3是一个用于模拟矢量场运动的纹理贴图动画的例子。
这些技术将在第9章中更详细地介绍。(详见362页的“纹理算法”。)
7.3体绘制
到目前为止,我们主要通过使用几何原语(如点、线和多边形)来实现数据的可视化。对于许多应用程序,如架构演练或地形可视化,这显然是最高效和有效的数据表示方式。相反,一些应用程序要求我们可视化本质上是体积的数据(我们称之为3D图像或体积数据集)。例如,在生物医学成像中,我们可能需要可视化从MR或CT扫描仪、共聚焦显微镜或超声研究中获得的数据。天气分析和其他模拟也产生大量三维或多维的体积数据,这需要有效的可视化技术。在过去的几十年里,由于体数据的流行和有用性,出现了一大类称为体绘制的渲染技术。体绘制的目的是在体数据中有效地传递信息。
在过去,研究人员试图将体绘制定义为直接在数据集上操作以生成图像而不生成中间几何表示的过程。随着最近图形硬件的进步和巧妙的实现,开发人员已经能够使用几何原语来生成与直接体绘制技术生成的图像相同的图像。由于这些新技术,几乎不可能以一种与几何绘制截然不同的方式定义体绘制。因此,我们选择了一个广义的体绘制定义,即任何对体数据进行操作以生成图像的方法。
接下来的几节将介绍使用直接渲染技术、几何原语渲染技术或这两种方法的组合来生成图像的各种体绘制方法。本章中讨论的一些直接体绘制技术gen图7-3使用纹理映射的矢量场动画的一帧(animVectors。tcl)。7.4图像顺序体绘制219生成的图像与前面章节中讨论的几何绘制技术生成的图像几乎相同。例如,使用射线投射方法来生成等值面图像与使用第六章中描述的移动立方体轮廓绘制技术提取的几何原语相似,但并不完全等效。
在第3章中描述的两种基本的表面绘制方法,图像顺序和对象顺序,也适用于体绘制技术。在图像顺序方法中,通过体积对图像平面中的每个像素投射光线以计算像素值,而在对象顺序方法中,通常以从前到后或从后到前的顺序遍历体积,处理每个体素以确定其对图像的贡献。此外,还有其他体绘制技术,不能简单地划分为图像顺序或对象顺序。例如,体绘制技术可以同时遍历图像和体,或者图像可以在频域而不是空间域中计算。
由于体渲染通常用于生成在2D图像中表示整个3D数据集的图像,因此引入了几个新的挑战。必须执行分类以将颜色和不透明度分配给体积内的区域,并且必须定义体积照明模型以支持阴影。此外,由于体绘制方法的复杂性和典型体数据集的大小,效率和紧凑性是非常重要的。由一百万个基本元素组成的几何模型通常被认为是大的,而具有一百万个体素的体积数据集则相当小。典型的卷包含一千万到几亿体素,十亿或更多体素的数据集变得越来越常见。显然,在决定在每个体素上存储辅助信息或增加处理每个体素所需的时间时,必须谨慎。
7.4图像顺序体绘制
图像顺序体渲染通常被称为射线投射或射线跟踪。基本思想是,我们根据当前的相机参数,通过向场景中发送一条穿过像素的射线,来确定图像中每个像素的值。然后,为了计算像素值,我们使用一些指定的函数计算沿射线遇到的数据。正如我们将在本章中演示的那样,光线投射是一种灵活的技术,可以用于渲染任何3D图像数据集,并可以生成各种图像。此外,将为具有统一体素的体数据集设计的基本射线投射技术扩展到直线或结构化网格上也相对容易。不幸的是,基本光线投射也相当缓慢;因此,在本章的后面,我们将讨论一些可以用来提高性能的加速方法,尽管通常会有一些额外的内存需求或灵活性的损失。
射线铸造过程如图7 - 4所示。这个例子使用标准的正字法相机投影;因此,所有的射线都彼此平行并垂直于视图平面。沿着每条射线的数据值根据射线函数进行处理,在本例中,该函数确定沿着射线的最大值并将其转换为灰度像素值,其中体积中的最小标量值映射为透明黑色,最大标量值映射为不透明白色。
射线投射的两个主要步骤是确定沿着射线遇到的值,然后根据射线函数处理这些值。虽然在实现中这两个步骤通常是结合在一起的,但我们暂时将它们单独处理。因为具体的

图7-4图像顺序体绘制。高电位铁蛋白数据由加州拉霍亚的斯克里普斯诊所提供。
射线函数通常决定了沿着射线提取值的方法,我们将从考虑一些基本的射线函数类型开始。
图7 - 5显示了一条射线经过8位体积数据时的数据值剖面,其中数据值的范围在0到255之间。配置文件的x轴表示与视图平面的距离,y轴表示数据值。从四个不同的简单射线函数得到的结果显示在剖面下面。为了显示,我们使用类似于前一个示例中的方法将原始结果值转换为灰度值。
前两个射线函数,最大值和平均值,是标量值本身的基本操作。第三个射线函数计算第一次遇到大于或等于30的标量值时沿射线的距离,而第四个使用alpha合成技术,将沿射线的值视为每单位距离积累的不透明度样本。与前三个射线函数不同,合成技术的结果不是可以在射线剖面上表示的标量值或距离。
最大强度投影(MIP)可能是可视化体积数据的最简单方法。当涉及到有噪声的数据时,这种技术是相当宽容的,并且生成的图像提供了对底层数据的直观理解。这种方法的一个问题是,不可能从静止图像中判断出沿射线的最大值发生在哪里。例如,考虑图7 - 6所示的颈动脉图像。我们无法从这张静止图像中完全了解血管的结构,因为我们无法确定某些血管是在另一些血管的前面还是后面。这个问题可以通过生成显示数据旋转的小图像序列来解决,尽管对于并行摄像机投影,即使这个动画也会模糊。这是由于两个图像生成的相机
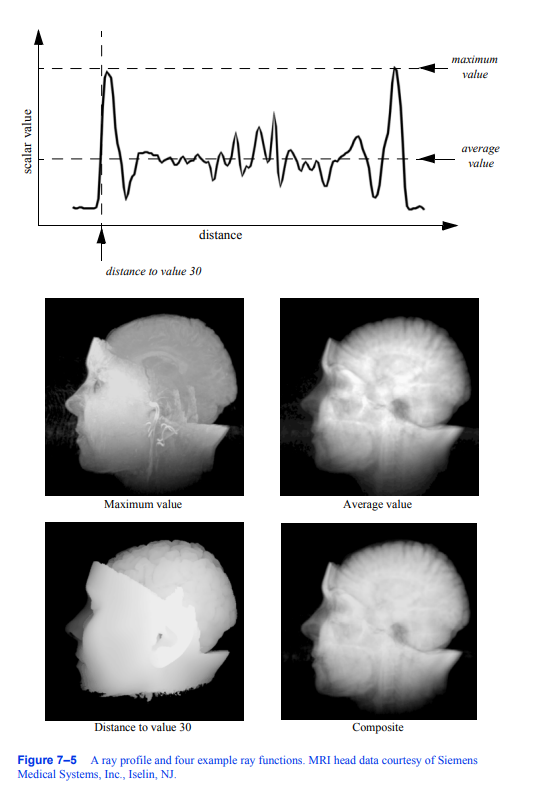
图7-5射线轮廓图和四个射线函数示例。MRI头部数据由西门子提供
医疗系统公司,Iselin,新泽西州。
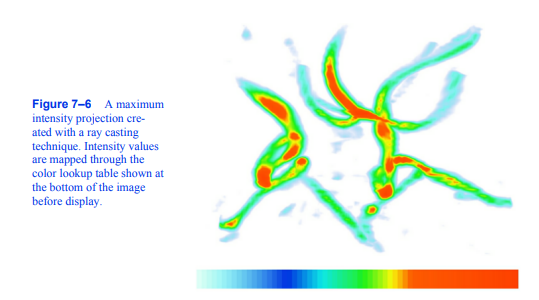
图7-6用射线投射技术创建的最大强度投影。强度值通过显示在图像底部的颜色查找表映射。
从相反的方向查看数据将是相同的,除了关于图像Y轴的反射。
在本章的后面,在分类和照明的讨论中,我们将考虑更复杂的射线函数。虽然新方法生成的彩色阴影图像可能包含更多信息,但它们也可能比前面例子中的简单图像更难解释,而且往往更容易被误解。因此,使用多种技术来可视化您的容量数据是有益的。
一个体积表示为一个三维图像数据集,其中标量值定义在规则网格的点上,但在光线投射中,我们经常需要在任意位置对体积进行采样。为此,我们必须定义一个插值函数,它可以为网格点之间的任何位置返回一个标量值。最简单的插值函数被称为零阶、常数或最近邻插值,它返回最近网格点的值。该函数定义了以网格点为中心的相同值的相同矩形框的网格,如图7 - 7左侧的2D所示。在右边的图像中,我们看到了一个三线性插值的例子,其中在某个位置的值是通过使用基于沿三个轴的距离的线性插值来定义的。通常,我们将由8个相邻网格点定义的区域称为体素。在离散算法与最近邻插值结合使用的特殊情况下,我们可以将常值区域称为体素。
为了沿着一条射线遍历数据,我们可以以统一的间隔对体积进行采样,或者我们可以通过体积遍历射线的离散表示,检查遇到的每个体素,如图7 - 8所示。方法的选择取决于诸如插值技术、射线函数以及图像精度和速度之间所需的权衡等因素。射线通常以参数形式表示为
光线的原点在哪里(要么是摄像机的位置,用于透视观看trans
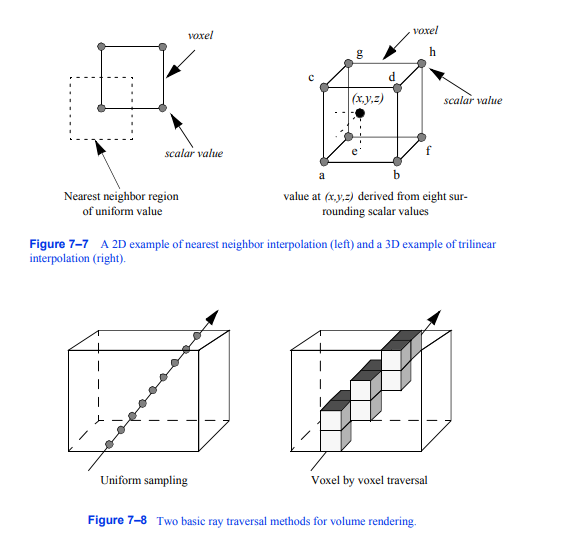
图7-7最近邻插值的二维示例(左)和三线性插值的三维示例(右)。
图7-8体绘制的两种基本射线遍历方法。
(用于并行查看转换的视图平面上的形成或像素),并且是归一化的射线d方向向量。如果t1和t2分别表示光线进入和离开体积的距离,delta_t表示步长,那么我们可以使用下面的代码片段进行均匀距离采样:


图7-9使用三种不同步长的射线投射方法生成的图像。花瓶数据由纽约州立大学石溪分校提供。
均匀距离抽样方法的难点之一是步长的选择。如果步长太大,那么我们的采样可能会错过数据中的特征,但如果我们选择一个小的步长,我们将显著增加渲染图像所需的时间。这个问题如图7 - 9所示,使用一个体积数据集,其中网格点沿X、Y和Z轴间隔一个单元。这些图像是使用步长为2.0、1.0和0.1的单位生成的,其中,步长为0.1的图像生成所需的时间是步长为1.0的图像的近10倍,而后者渲染所需的时间是步长为2.0的两倍。使用合成方法生成图像,其中数据集内的标量值从透明的黑色急剧过渡到不透明的白色。如果步长太大,则沿观察射线在距离射线原点等距离的体积的图像高亮区域出现条带效应。为了减少这种影响,当出于性能原因需要更大的步长时,每条射线的原点可以沿着观看方向向前颠簸一些小的随机偏移,这将通过消除混叠的规则模式产生更令人愉悦的图像。
在某些情况下,沿着射线检查每个体素可能比取样更有意义。例如,如果我们正在使用最近邻插值方法可视化数据,那么我们可能能够使用离散射线遍历和整数算术实现更有效的算法。检查体素的另一个原因可能是在某些射线函数上获得更好的精度。当使用三线性插值时,我们可以通过对插值函数沿射线求一阶导数并求解得到的方程来计算极值,从而计算出每个体素内沿射线遇到的确切最大值。类似地,我们可以沿着射线找到第一次遇到选定值的确切位置,以生成体积内等值曲面的更好图像。
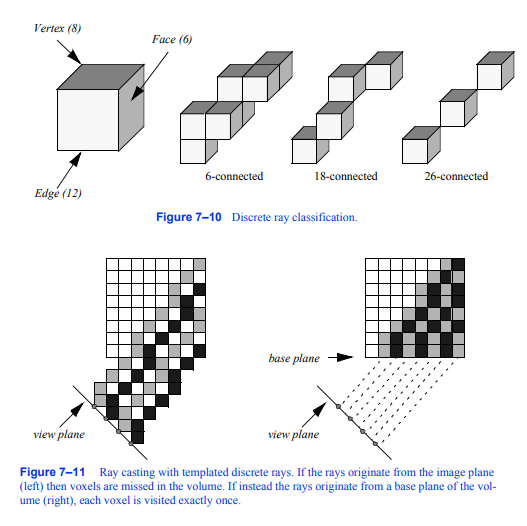
图7-11离散射线模板浇铸如果光线来自像面
(左)则体素在体积中丢失。相反,如果光线来自体的基平面(右),则每个体素只访问一次。
3D扫描转换技术,如改进的布雷森汉姆方法,可用于将连续射线转换为离散表示。离散射线是体素的有序序列,…,可分为6连通、18连通和26连通,如图7 - 10所示。每个体素包含6个面,12条边和8个顶点。如果沿着射线的每对体素共享一个面,则射线是6连通的,如果它们共享一个面或一条边,则射线是18连通的,如果它们共享一个面、一条边或一个顶点,则射线是26连通的。扫描转换和遍历一个26连接的射线所需的时间比一个6连接的射线更少,但更有可能错过体积数据集中的小特征。
如果我们正在使用并行观察转换,并且我们的射线函数可以通过体素遍历方法使用体素有效地计算,那么我们可以使用模板射线投射技术[Yagel92b]使用26连接的射线来生成图像。所有的射线方向相同;因此,我们只需要扫描转换一次,对每条射线使用这个“模板”。当这些光线从图像平面上的像素投射出来时,如图7 - 11的左侧图像所示,那么数据集中的一些体素将不会对图像做出贡献。如果我们把光线从体素投射到
与图像平面最平行的体的基平面,如右图所示,然后射线紧密地贴合在一起,以便数据集中的每个体素都被访问一次。图像会出现扭曲,因为它是从基平面生成的,因此需要最后的重采样步骤来将该图像投影回图像平面。
7.5对象-顺序体绘制
对象顺序体绘制方法基于数据集中体素的组织和当前相机参数来处理体中的样本。当使用alpha合成方法时,必须以从前到后或从后到前的顺序遍历体素以获得正确的结果。这个过程类似于在每次投影之前对半透明多边形进行排序,以确保正确的混合。当图形硬件被用于合成时,向后到前的排序通常是首选的,因为这样就可以执行alpha混合,而不需要在帧缓冲区中使用alpha位平面。如果使用软件合成方法,从前到后排序更常见,因为部分图像结果在视觉上更有意义,并且可以用来避免在像素达到完全不透明时进行额外的处理。基于视图平面距离的体素排序并不总是必要的,因为一些体渲染操作,如MIP或平均,可以以任何顺序处理,并且仍然产生正确的结果。
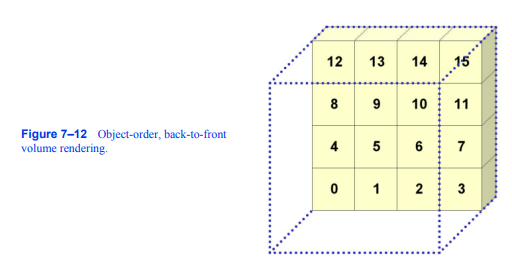
图7 - 12说明了一个简单的对象顺序,前后的方法来投影体素在一个体中进行正字法投影。体素遍历从距离视图平面最远的体素开始,然后逐步向更近的体素继续,直到访问了所有体素。这是在一个三重嵌套循环中完成的,从外部循环到内部循环,遍历卷中的平面,处理平面中的行,最后访问一行中的体素。图7 - 12显示了前7个体素随着体积的投影的有序标记。以这种方式处理体素不会产生从最远到最近的严格顺序。然而,它对于正字法投影来说已经足够了,因为它确实确保了投射到单个像素的体素按照正确的顺序进行处理。
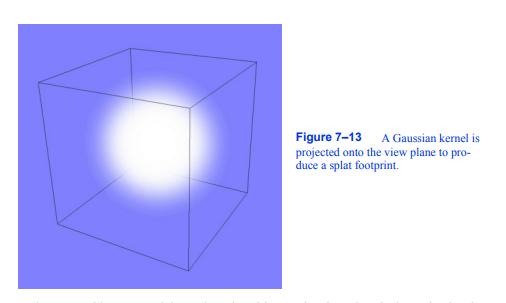
图7-13将高斯核投影到视图平面上,产生splat footprint。
当处理体素时,确定其在视图平面上的投影位置,并使用体素和图像信息在该像素位置执行操作。此操作符类似于图像顺序射线投射技术中使用的射线函数。虽然这种投影体素的方法既快速又有效,但由于投影图像像素的离散选择,它经常产生图像伪影。例如,当我们在透视投影中将相机移动到体积附近时,相邻的体素将投射到视图平面上越来越远的像素上,导致图像中出现分散注意力的“洞”。
一种称为溅射的体绘制技术通过将体素的能量分布到许多像素来解决这个问题。飞溅是由Westover [Westover90]提出的一种对象顺序体绘制技术,顾名思义,它将体素的能量投射到图像平面上,每次一个飞溅或印迹。在每个数据样本周围放置一个有限范围的核。足迹是该样本在图像平面上的投影贡献,并通过沿观察方向积分内核并将结果存储在2D足迹表中来计算。图7 - 13说明了高斯核在图像平面上的投影,然后可以用作飞溅足迹。对于平行观察变换和球对称核,除了图像空间偏移外,每个体素的足迹是相同的。因此,对样本的足迹表和图像空间范围的评估可以作为体绘制的预处理步骤执行一次。飞溅是更困难的透视体绘制,因为图像空间范围是不相同的所有样本。在飞溅方法中精确校正透视效果会使算法效率大大降低。然而,如果我们用椭圆近似椭球的像面范围,我们仍然可以使用通用足迹表,但精度损失很小。
在使用飞溅方法进行体绘制时,有几个重要的注意事项。内核的类型、内核的半径和内存占用表的分辨率都将影响最终图像的外观。例如,核半径小于相邻样本之间的距离可能会导致图像中的间隙,而更大的半径将导致图像模糊。此外,低分辨率的内存占用表可以更快地预计算,但高分辨率的内存占用表

图7-14使用2D(左)和3D(右)纹理映射技术的体绘制
Tion表允许我们使用最近邻采样更快的渲染时间,而不显着损失的图像精度。
本章前面描述的纹理映射最初是为了在渲染几何表面时提供高表面复杂度的外观。随着纹理映射方法的成熟并进入标准图形硬件,研究人员开始利用这些新功能来执行体绘制[Cabral94]。基于目前可用的两种主要类型的纹理硬件,有两种主要的纹理映射体绘制技术。二维纹理映射体绘制使用2D纹理映射硬件,而3D纹理映射体绘制使用较少可用的3D纹理映射图形硬件。
我们可以将纹理映射体渲染分解为两个基本步骤。第一个是采样步骤,其中使用某种形式的插值从卷中提取数据样本。根据可用的纹理硬件类型,这可以是最近邻插值、双线性插值或三线性插值,并且可以仅在硬件中执行,也可以通过软件和硬件技术的组合来执行。第二步是混合步骤,其中采样值与帧缓冲区中的当前图像相结合。这可能是一个简单的极大算子,也可能是一个更复杂的合成算子。
纹理映射体渲染器通过投影一组跨越整个卷的纹理映射多边形来对卷进行采样和混合以生成图像。在2D纹理映射体绘制中,数据集被分解为一组正交切片,沿着与观看方向最平行的体的轴。基本的渲染算法包括以前后顺序在正交切片上进行循环,其中对于每个切片,一个2D纹理被下载到纹理内存中。每个切片都是一个矩形多边形,投影显示整个2D纹理。如果相邻的切片相对于图像大小相差很远,那么可能需要使用软件双线性插值方法从体积中提取额外的切片,以实现一个
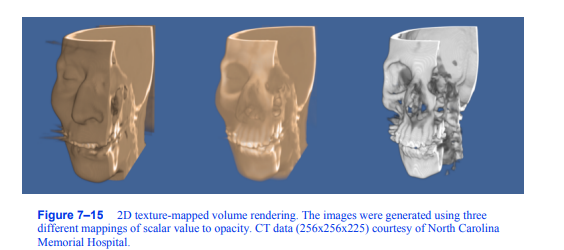
图7-15二维纹理映射体绘制。这些图像是使用三种不同的标量值到不透明度的映射生成的。CT数据(256x256x225)由北卡罗来纳州提供
纪念医院。
期望的图像精度。图7 - 14左侧的图像说明了使用2D纹理映射方法渲染的正交切片。使用2D纹理映射体绘制生成的几个示例图像如图7 - 15所示。
该算法的性能可以分解为软件采样率、纹理下载率和纹理映射多边形扫描转化率。软件采样步骤需要创建纹理图像,并且在访问存储在线性数组中的体积数据时,由于缓存局部性,通常依赖于视图方向。一些实现以牺牲内存为代价,通过为三个主要的体积方向预计算和保存图像来最小化软件采样成本。纹理下载速率是图像从主内存传输到纹理映射内存的速率。多边形的扫描转换通常受到图形硬件处理图像中像素的速率或像素填充速率的限制。对于给定的硬件实现,卷的下载时间是固定的,不会因查看参数而改变。然而,减少投影体积的相对大小将减少图形硬件处理的样本数量,反过来,将以牺牲图像质量为代价提高体积渲染率。
与2D硬件不同,3D纹理硬件能够通过使用3D插值技术(如三线性插值)在一个卷中的多个切片之间加载和插值。如果纹理内存足够大,可以容纳整个卷,那么渲染算法就很简单。整个卷被下载到纹理内存一次作为预处理步骤。为了渲染图像,沿着观看方向并平行于图像平面的一组等距平面被剪切到体积上。得到的多边形,如图7 - 14右侧的图像所示,然后用适当的3D纹理坐标以前后顺序投影。
对于大的卷,可能不可能将整个卷加载到3D纹理内存中。这个问题的解决方案是将数据集分解成足够小的子卷,或砖,以便每个砖都能适合纹理内存。砖块必须按照前后顺序处理,同时计算砖块内部适当裁剪的多边形顶点。必须特别注意确保砖块之间的边界不会导致图像伪影
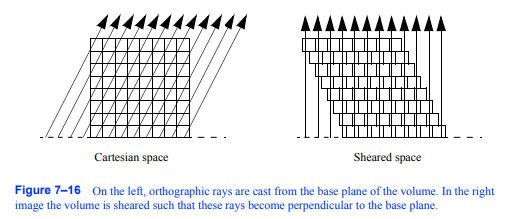
图7-16左侧,正射光从体量的基面投射。在右边的图像中,体积被剪切,使得这些射线垂直于基面。
与2D纹理映射方法类似,3D算法受到机器的纹理下载和像素填充率的限制。然而,3D纹理映射在对体积进行采样的能力上优于2D版本,通常会产生更高质量的图像和更少的伪影。由于它能够执行三线性插值,我们能够在体积内的任何位置采样。例如,3D纹理映射算法可以沿着表示同心球体的多边形进行采样,而不是更常见的视图对齐平面。
理论上,3D纹理映射体渲染器和光线投射体渲染器执行相同的计算,具有相同的复杂性,并产生相同的图像。两者都使用最近邻或三线性插值对整个体积进行采样,并使用例如最大值或合成函数将样本组合成像素值。因此,我们可以将3D纹理映射和标准射线投射方法视为功能等效的。使用纹理映射方法的主要优点是能够利用相对快速的图形硬件来执行采样和混合操作。然而,目前使用图形硬件进行体渲染存在一些缺点。硬件纹理映射体渲染往往比软件光线投射技术有更多的工件,因为在混合期间在每个像素存储部分结果的帧缓冲区内的精度有限。此外,硬件只支持少量的光线功能,诸如遮阳等高级技术更难实现。然而,随着纹理映射硬件的发展,这些限制开始消失。通过使用OpenGL标准的扩展,可以定义每个像素向量,允许硬件阴影体纹理映射。其他扩展允许最大强度的投影,更深的framebuffer消除了工件
7.6其他体绘制方法
并不是所有的体绘制方法都可以清晰地归入图像顺序或对象顺序类别。例如,体绘制的剪切-翘曲方法[Lacroute94]同时遍历图像和物体空间。这种方法背后的基本思想类似于模板射线投射。如果我们从体积的基面投射光线进行正交投影,则可以剪切体积,使光线垂直于基面,如图7 - 16所示。这样看问题,可以清楚地看到,如果所有的射线都来自基平面上的体素内的同一位置,那么这些射线就会与每个子轴上的体素相交。图7-16在左侧,正射射线从体积的基平面投射出来。在右边的图像中,体积被剪切,使得这些射线垂直于基面。笛卡尔空间剪切空间7.7体积分类231平面的体积在一致的位置。在数据集的2D平面上使用双线性插值,我们可以为每个平面预先计算一组插值权值。可以使用对象顺序遍历方法,而不是通过沿着每条射线评估样本来遍历体积,以从前到后的顺序访问每个平面中每一行的体素。在体积平面上的样本和图像平面上的像素之间存在一一对应关系,使得同时遍历样本和像素成为可能。与模板射线投射一样,必须执行最后的重采样(扭曲)操作,以将图像从基平面上的剪切空间转换到图像平面上的笛卡尔空间。
剪切-翘曲体渲染本质上是一种有效的射线投射变体。样本和像素之间的对应关系使我们能够利用一种称为早期射线终止的标准射线投射技术。当我们确定一个像素在合成过程中已经达到完全不透明度时,我们不再需要考虑投射到这个像素上的剩余样本,因为它们不构成最终的像素值。剪切变形体绘制中最大的效率改进来自于对体的运行长度编码。这种压缩方法从数据集中删除所有空体素,只留下可能对图像有贡献的体素。根据数据的分类,可以实现大于10:1的体素减少。当我们步进压缩卷时,由于运行长度编码而跳过的体素数量也指示了图像中要跳过的像素数量。这种方法的一个缺点是,它需要三个压缩卷的副本,以允许从所有视图方向进行从前到后的遍历。此外,如果我们希望使用透视图查看转换,那么我们可能需要遍历卷的所有三个压缩副本,以实现正确的遍历顺序。
体绘制也可以使用傅里叶切片投影定理[Totsuka92]进行,该定理指出,如果我们在频域中提取包含中心且平行于图像平面的体积切片,那么该切片的2D频谱等效于通过从图像平面上的像素对该体积进行线积分获得的2D图像。因此,我们可以通过从三维傅里叶体中提取适当的切片,然后计算该切片的二维傅里叶反变换来对数据集进行体积渲染。这使我们能够及时渲染图像,而不是大多数其他体渲染算法所要求的复杂性。
在实现频域体渲染器时,必须解决两个问题:从傅里叶体积提取切片时的高插补成本,以及存储傅里叶体积所需的高内存要求(通常每个样本需要两个双精度浮点值)。虽然这种方法可以提供一些阴影和深度线索,但遮挡是不可能的。
7.7卷分类
对数据集中感兴趣的相关对象进行分类是生成大量渲染图像的关键步骤。这些信息用于确定物体对图像的贡献,以及物体的材料属性和外观。例如,通常通过指定密度阈值来对CT数据集中的数据样本是否对应于骨骼进行简单的二进制分类。当体素上的标量值大于此阈值时,将其分类为骨,否则将其视为空气。这本质上是在空气和骨骼之间的过渡体积中指定了一个等值面。如果我们把这个操作画在所有可能的标量上,我们会得到
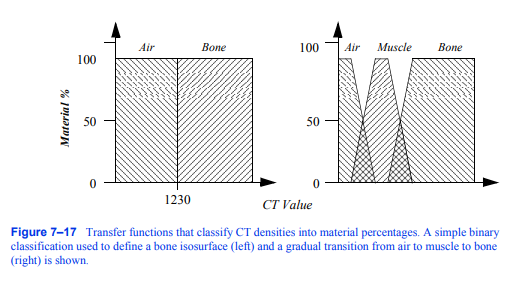
图7-17将CT密度划分为材料百分比的传递函数。一种简单的二元分类,用于定义骨等值面(左)和从空气到肌肉再到骨骼的逐渐过渡
(右)所示。
即图7 - 17中左边所示的二进制步进函数。在体绘制中,我们把这个函数称为传递函数。传递函数负责将体素位置上的信息映射为不同的值,如材质、颜色或不透明度。体绘制的优势在于它可以处理比二进制步进函数复杂得多的传递函数。这通常是必要的,因为数据集包含多种材料,分类方法不能总是以100%的概率将单一材料分配给样本。利用先进的图像分割和分类技术,可以将单个组分体积处理成多个材料百分比体积[Drebin88]。回顾我们的CT示例,我们现在可以指定一个材料百分比传递函数,定义从空气到肌肉,然后从肌肉到骨骼的逐渐过渡,如图7 - 17右侧所示。
除了材料百分比传递函数,我们还可以定义四个独立的传递函数,将标量值映射为数据集中每种材料的红色、绿色、蓝色和不透明度值。为了简单起见,在分类阶段结束时,这些传递函数集通常被预处理为红、绿、蓝和不透明度各一个函数。在渲染过程中,我们必须决定如何执行插值来计算体积中任意位置的不透明度和颜色。我们可以插值标量值,然后计算传递函数,或者我们可以在网格点处计算传递函数,然后插值得到的不透明度和颜色。这两种方法会产生不同的图像结果。通常认为在网格点上分类比插值更准确,以获得颜色和不透明度;虽然如果我们插值然后分类,图像往往看起来更令人满意,因为高频可以删除插值。
仅根据标量值对卷进行分类通常无法隔离感兴趣的对象。Levoy [Levoy88]引入的一种技术在传递函数的规范中添加了一个梯度幅度维度。使用这种技术,我们可以根据标量值和梯度幅度的组合在体积中指定一个对象。这允许我们定义一个不透明度传递函数,该函数可以在密度范围内的标量值和梯度范围内的梯度范围内针对体素。这对于避免在卷中选择同构区域和突出显示快速变化的区域非常有用。CT扫描如图7 - 18所示
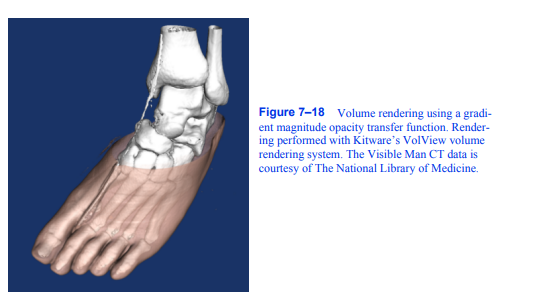
图7-18使用梯度幅度不透明度传递函数绘制体。使用Kitware的VolView体绘制系统进行渲染。可见人CT数据由国家医学图书馆提供。
一只人的脚。体积的急剧变化,如从空气到皮肤,从肉到骨头的转变,都显示出来了。然而,同质区域,如内部肌肉,大多是透明的。如果我们使用高阶插值函数,如三次三次插值,那么我们可以通过计算插值函数的一阶导数来分析计算数据集中任何位置的梯度向量。虽然我们可以将这种方法用于三线性插值,但由于三线性插值的一阶导数在体素边界上不是连续的,因此它可能会产生不可取的伪影。另一种方法是使用有限差分技术来近似梯度向量:
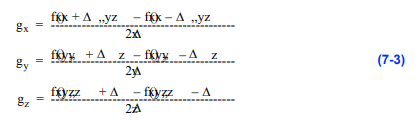
其中表示根据插值函数在数据集中某个位置的标量值,、、和分别是该函数在、、和轴上的偏导数。处梯度的大小就是得到的向量的长度。这个向量也可以归一化得到一个单位法向量。和的选择至关重要,如图7 - 19所示。如果这些值太小,则由公式7-3导出的梯度向量场可能包含高频率,但如果这些值太大,我们将失去数据集中的小特征。
通常情况下,基于标量值甚至梯度幅度的传递函数都不能完全分类一个体积。超声波数据是一个特别困难的数据的例子,它不能很好地使用简单的分割技术。虽然没有一种技术是普遍适用的,但有各种各样的技术可以产生分类

图7-19正常估计时使用的两种不同步长阴影图像的比较。共聚焦显微镜数据由纽约州立大学霍华德休斯医学研究所提供
石溪分校。
每个样品的阳离子信息。例如,[Kikinis96]提供了对人脑进行分类的技术。为了正确地处理这些信息,卷渲染器必须访问原始卷和分类卷。分类卷通常包含每个样品的材料百分比,以及用于定义外观的每种材料的一组颜色和不透明度传递函数。
7.8容积照明
到目前为止,我们在本章中展示的体积渲染图像不包括任何灯光效果。科学家们有时更喜欢使用这些更简单的方法来可视化他们的体积,因为他们担心在图像上添加灯光效果会干扰他们的解释。例如,在最大强度投影中,图像中的黑暗区域清楚地表明在体积的相应区域中缺乏高不透明度值,而阴影图像中的黑暗特征可能表明低不透明度值或指向远离光源的梯度方向的值。
光照有几个优点,通常可以证明图像中额外的复杂性是合理的。首先,考虑到体绘制是一个从3D数据创建2D图像的过程。查看该数据的人希望能够从该图像中了解体积的3D结构。当然,如果你看一张骨骼的照片,从2D表示中很容易理解它的结构。你从图片中得到的两个主要线索是遮挡和灯光效果。如果你看一段骨架的视频,你会得到运动视差的额外线索。显示最大强度投影的静态图像不包括遮挡或照明效果,因此很难理解结构。用合成技术生成的图像确实包括遮挡和合成射线
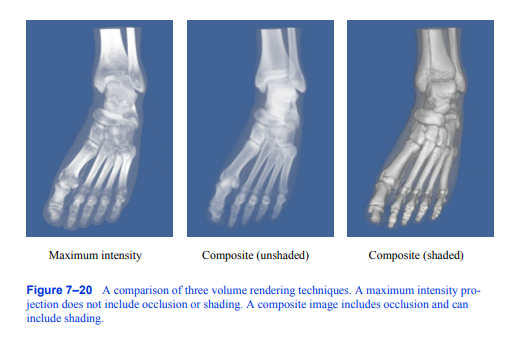
图7-20三种体绘制技术的比较。最大强度投影不包括遮挡或阴影。合成图像包括遮挡,也可以包括阴影。
函数也可以修改为包含底纹。这三种方法的对比如图7 - 20所示,用于人体足部的CT扫描。为了准确地捕捉照明效果,我们可以使用传输理论照明模型[Krueger91],该模型通过沿着光线的路径积分来描述到达像素的光强度:
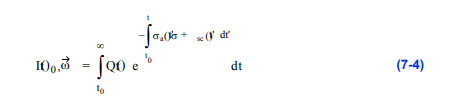
如果我们使用的是相机剪辑平面,那么和将分别被到近剪辑平面的距离tnear和到远剪辑平面的距离tfar所取代。沿着射线在一定距离上的每个样品的贡献是衰减的,这取决于在从到途中由于吸收和散射而损失了多少强度。的贡献可以定义为:
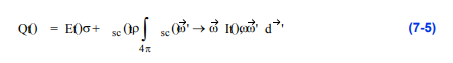
贡献由样品直接发射的光量,加上来自各个方向的光量,被样品沿着射线散射回来。图7-20三种体绘制技术的比较定义了从该方向到达的散射到该方向的光的比例。最大强度投影不包括遮挡或阴影。合成图像包括遮挡,也可以包括阴影。最大强度复合(无阴影)复合(阴影)I It()0,w Qt() e sa()st' sc + ()t' t' t0 t ò - dt t0¥ò = t0¥Qt() t w t t0 sa() t' ssc ()t' t Qt() Et()s sc ()rt sc ()w'®w It,()ww' d ' 4p ò = + Et() w' w 236高级计算机图形学散射函数。为了计算由于多次反射散射而从各个方向到达的光,我们必须递归地计算照明函数。
如果精确地模拟了散射,那么基于传输理论照明模型的射线函数将产生具有真实照明效果的图像。不幸的是,这个照明模型太复杂而无法评估,因此在实际实现中需要近似。最简单的近似之一是完全忽略散射,得到以下强度方程:

我们可以进一步简化这个方程,允许表示沿射线每单位长度发射的光量和每单位长度吸收的光量。外部的积分可以用沿着射线在某个剪切范围内的样本的和来代替,而内部的积分可以用一个over算子来近似:
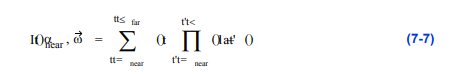
这个方程通常以递归形式表示:
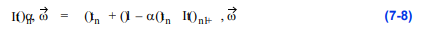
这相当于使用前面描述的over运算符的简单合成方法。显然,在这种情况下,我们已经简化了照明模型,以至于这个射线函数不会产生看起来真实的图像。
如果我们在体积数据中可视化等值面,那么我们可以使用第3章中描述的表面照明模型来捕获环境照明和漫射照明以及高光。有各种各样的技术估计表面法线需要评估阴影方程。如果作为体渲染结果产生的图像包含每个像素从视图平面到表面的距离,那么我们可以使用2D梯度估计器对图像进行后处理,以获得表面法线。在某些像素点的梯度可以用中心差分技术估计:

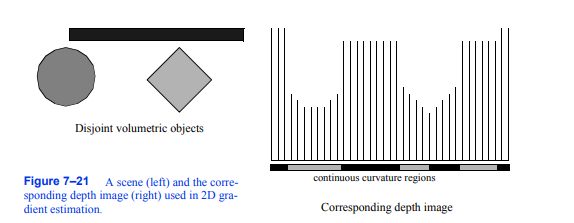
图7-21二维梯度估计的场景(左)和对应的深度图像(右)。
结果经过归一化得到一个单位法向量。与公式7-3中给出的三维有限差分梯度估计器一样,在选择和时必须小心。通常,这些值只是像素间距,因此邻近的像素值被用来估计梯度,尽管更大的值可以用来平滑图像。
上面描述的2D梯度估计技术的一个问题是法线是从深度值计算出来的,这些深度值可能表示体积中的不相交区域,如图7 - 21所示。这可能会导致物体边缘锐利特征的模糊。为了减少这种影响,我们可以在深度图像中定位连续曲率区域,然后仅使用落在相同曲率区域内的其他像素值来估计像素的法线[Yagel92a]。这可能需要减少我们的和值,或使用偏离中心的差异技术来估计梯度的成分。例如,梯度的分量可以用正向差来计算:
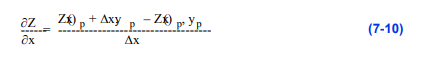
或者是向后的差异:

虽然2D梯度估计不像3D版本那样准确,但它通常更快,并且允许快速照明和表面属性的变化,而不需要我们重新计算深度图像。然而,如果我们希望在用合成技术计算的图像中包含阴影效果,我们需要估计每个像素在体积内许多位置的梯度。三维梯度估计技术更适合于此目的。合成时的光照方程可以写成:
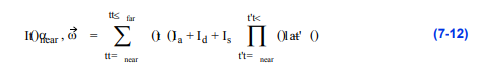
其中,环境照明、漫射照明和镜面照明计算为使用估计的体积梯度代替表面法线的表面阴影。式中,表示每单位长度上沿射线反射的光量,表示每单位长度上透射光的比例。
与分类一样,我们必须决定是直接计算体积中任意位置的照明,还是计算网格点的照明,然后进行插值。在精度的基础上,这并不是一个困难的决定,因为在期望的位置估计梯度显然比从邻近的估计中插值更好。另一方面,如果我们从网格点进行插值,那么我们可以一次预先计算整个数据集的梯度,并使用这一点来提高分类和照明的渲染性能。主要问题是存储预先计算的梯度所需的内存数量。简单的实现将为每个标量值的梯度的每个组件存储一个浮点值(通常为四个字节)。对于具有单字节标量的数据集,这将使存储需求从16兆字节增加到218兆字节。
为了减少存储需求,我们可以量化预先计算的梯度,使用一些位数来表示向量的大小,使用一些位数来编码向量的方向。量化可以很好地存储梯度的大小,但是如果我们简单地在矢量的三个分量中划分比特,就不能提供良好的方向分布。较好的解决方法是将八面体均匀分形细分为球体作为方向编码的基础,如图7 - 22所示。左上方的图像显示了递归替换每个三角形后得到的结果,用四个新的三角形,递归深度为2。在这种表示中编码的矢量方向是通过创建一条起源于球体中心并经过球体顶点的射线形成的所有方向。该图中的其余图像说明了如何将这些方向映射到索引中。首先,我们将所有顶点推回到八面体的原始面上,然后我们将这个球面压平到平面上。最后,我们将生成的网格旋转。我们将网格中的顶点标记为索引,从左上角顶点的0开始,然后继续跨行,然后沿着列向下,直到右下角顶点的索引40。这些索引只代表编码法线的一半,因为当我们将八面体平展时,我们在除了边缘位置之外的所有位置上都放置了两个顶点。因此,我们可以使用指标41到81来表示z分量为负的向量。边缘上的顶点表示没有z分量的向量,尽管我们可以用一个索引表示它们,但使用两个索引使索引方案更加一致,因此更容易实现。
上面的简单示例只需要82个值来编码66个唯一的向量方向。如果我们使用unsigned short来存储编码的方向,那么在生成顶点时,我们可以使用6的递归深度。这就有16,642个指数,代表16,386个不同的方向。
一旦为我们的体积编码了梯度,我们只需要为每个可能的索引计算一次照明,并将结果存储在一个表中。由于具有相同编码梯度方向的数据样本可能具有不同的颜色,因此该照明值表示阴影方程中与颜色无关的部分。每个标量值可以为环境、漫反射和镜面照明定义单独的颜色;因此,预先计算的照明通常是一个值数组。
尽管使用着色表可以加快渲染时间,但这种方法也有一些局限性。由于位置光源的不同会导致相同梯度的数据样本的光矢量不同,因此只能精确地支持无限个光源
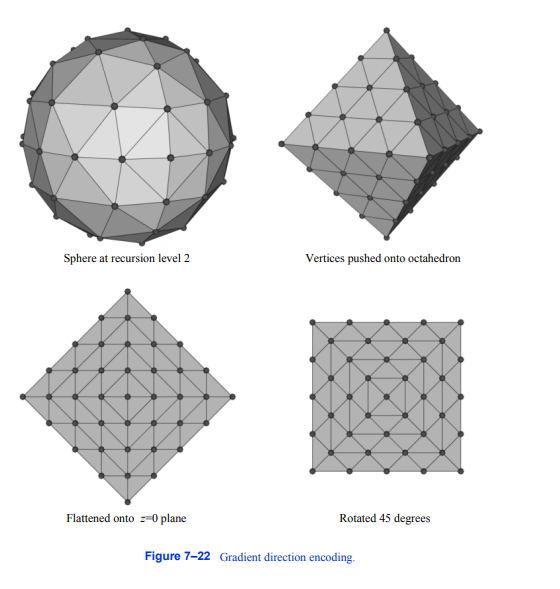
图7-22梯度方向编码。
卷中的位置。此外,高光的高光只被准确地捕捉到正射观看方向,其中视图矢量不基于样本位置而变化。在实践中,位置光源通常近似于无限光源,并且由于快速渲染的需要通常超过精确照明的需要,因此使用单个视图方向来计算高光。
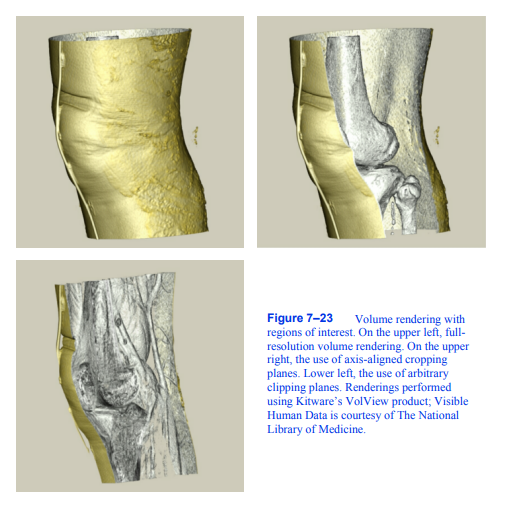
图7-23感兴趣区域的体绘制。在左上方,全分辨率的体渲染。在右上方,使用轴对齐的裁剪平面。左下,使用任意裁剪平面。渲染使用Kitware的VolView产品;可见
人体数据由《国家报》提供
医学图书馆。
7.9兴趣领域
用迄今为止提出的方法可视化体积数据的一个困难是,为了研究体积中心的某些特征,我们必须查看数据集中的其他特征。例如,如果我们正在可视化一个番茄数据集,那么我们将无法使用最大强度投影看到番茄内的种子,因为种子的强度低于周围的果肉。即使使用合成技术,也很难可视化种子,因为在到达数据集的这个区域之前可能会获得完全的不透明度。
我们可以通过在我们的卷中定义一个感兴趣的区域来解决可视化内部特征的问题,并只渲染数据集的这一部分,如图7 - 23所示。有许多技术可以定义感兴趣的区域。我们可以使用相机的近、远剪切平面来排除部分体积。或者,我们可以使用六个正字法裁剪平面来定义一个矩形子体积;我们可以使用一组任意方向的半空间裁剪平面;或者我们可以把感兴趣的区域定义为体积的一部分
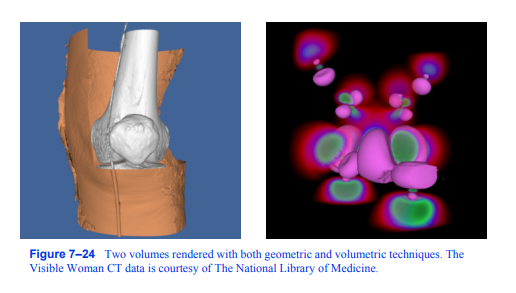
图7-24用几何和体积技术绘制的两个体块。的
可见女性CT数据由国家医学图书馆提供。
包含在一组封闭的几何对象中。另一种方法是创建一个带有二进制标量值的辅助卷,这些值定义一个掩码,指示在呈现期间应该考虑卷中的哪些值。使用图像顺序射线投射方法实现
所有这些感兴趣的区域方法都相当简单。作为光线投射的预处理步骤,光线根据所有几何区域定义被剪切。然后,只沿着感兴趣区域内的射线段计算射线函数。每个样本的掩码值都被参考,以确定是否应该包括或排除它的贡献。
对于对象顺序方法,我们必须确定每个样本是否在感兴趣的区域内,然后将其贡献合并到图像中。如果底层图形硬件被用于对象顺序体绘制,就像纹理映射方法的情况一样,硬件裁剪平面可能可用来帮助支持感兴趣的区域。
7.10混合体积和几何
虽然在体可视化中,体积通常是图像的焦点,但在场景中添加几何对象通常是有帮助的。例如,显示数据集的包围框或切割平面的位置和方向可以提高查看者对体积数据的理解。此外,在同一图像中同时使用几何和体积方法可视化体积数据也很有用。图7 - 24中的左图显示了人类膝盖的CT扫描,其中使用轮廓法提取皮肤等值面。使用标准图形硬件将此等值面渲染为三角形。皮肤的右上部分被切割以显示下面的骨头,这是使用软件射线投射技术和合成射线功能渲染的。在右侧图像中,使用几何等值面和体绘制技术可视化了铁蛋白的波函数值。
当使用图形硬件执行体渲染时,就像纹理映射方法一样,在场景中混合不透明的几何图形是微不足道的。所有不透明的几何图形都是图7-24用几何和体积技术渲染的两个体。可见女性CT数据由国家医学图书馆提供。242张高级计算机图形先渲染,然后半透明的纹理映射多边形以前后顺序混合到图像中。如果我们希望在场景中包含半透明的几何体,那么这个几何体和纹理映射的多边形必须在渲染之前进行排序。类似于纯几何场景,这可能涉及分割多边形以获得排序顺序。
如果使用软件体绘制方法,例如对象顺序飞溅方法或图像顺序射线投射方法,则可以通过渲染几何图形,捕获存储在硬件深度缓冲区中的结果,然后在体绘制阶段使用这些结果来将不透明几何图形合并到图像中。对于射线投射,我们将简单地将像素的深度值转换为沿视图射线的距离,并使用它来绑定我们在体绘制期间考虑的射线段。在体绘制期间为像素计算的最终颜色然后与使用over运算符的几何绘制产生的颜色混合。在对象顺序方法中,我们必须考虑每个样本的深度,并将其与该样本图像范围内每个像素处的深度缓冲区中存储的值进行比较。只有当样本位于该像素的几何图形前面时,我们才在每个像素处累积该样本对体积渲染图像的贡献。最后,将体渲染图像混合在几何图像上。
7.11高效的体绘制
渲染体积数据集是一项计算密集型任务。如果是在所有三个维度上的体积大小,并且我们在投影期间访问每个体素一次,则体绘制的复杂性为。即使是一个高度优化的软件算法也很难以交互速率投影一个中等大小或大约1.34亿体素的体积。如果体积中的每个体素都以某种方式对最终图像有贡献,而我们不愿意妥协图像质量,那么我们提高效率的选择就有限了。然而,据观察,许多体积数据集包含大量空白或无趣的数据,在分类过程中分配了不透明度值。此外,那些包含有趣数据的区域可能被相干或几乎均匀的区域所占据。人们已经开发了许多技术来利用这些观察结果。
空间跳跃是指一种一般的效率改进技术,它试图避免处理对最终图像没有贡献的体积区域。一种常用的技术是构建一个八叉树数据结构,它在层次上包含卷中的所有重要区域。八叉树的根节点包含整个卷,它有8个子节点,每个子节点代表卷的1/8。这八个子区域是通过沿x、y和z轴将卷分成两半来创建的。这种细分继续递归地进行,直到八叉树中的一个节点表示卷的同构区域。使用对象顺序呈现技术,在呈现过程中只遍历八叉树的非空叶节点,从而避免所有空区域,同时有效地处理所有贡献的齐次区域。类似地,图像顺序射线投射技术将通过叶节点投射射线,八叉树的规则结构允许我们快速跳过空节点。
一种混合空间跳跃技术[Sobierajski95]利用图形硬件在软件光线投射期间跳过体积的一些空区域。首先,创建一个多边形表示,它完全包含或包围卷中的所有重要区域。然后将该多边形表示投影两次——第一次在深度缓冲区上使用通常的小于运算符,第二次在深度缓冲区上使用大于运算符。这将产生2个n On 3() 512512512´´0 7.12交互式体绘制243个深度图像,其中包含图像中每个像素与相关数据的最近和最远距离。然后在光线投射过程中使用这些距离来剪辑光线。
另一种用于光线投射的空间跳跃技术涉及使用辅助距离体积[Zuiderveld92],每个值表示到数据集中非透明样本的最近距离。这些距离值用于在卷的空区域中迈出更大的一步,同时确保我们不会跨越卷中的任何不透明特征。不幸的是,要精确地计算距离体积,计算成本很高,需要额外的存储,并且每次修改体积的分类时都必须重新计算。
这些空间跳跃技术的一个困难是它们高度依赖于数据。在有少量相干数据的空卷上,我们可以大大加快卷渲染的速度。然而,当遇到完全由高频信息组成的数据集(如典型的超声数据集)时,这些技术就会失效,通常会导致渲染时间增加而不是减少。
7.12交互式体绘制
生成一个体积渲染图像可能需要几分之一秒到几十分钟的时间,这取决于各种因素,包括硬件平台、图像大小、数据大小和渲染技术。如果我们是为了医学诊断而生成图像,我们显然希望生成高质量的图像。另一方面,如果图像是在交互会话期间生成的,那么实现所需的渲染更新速率可能更重要。因此,很明显,我们需要根据应用的需要,在质量和速度之间进行权衡。与我们关于提高效率的讨论相反,这里描述的技术并不能保持图像质量。相反,为了达到速度,它们允许有控制的质量退化。
由于按图像顺序进行射线投射所需的时间主要取决于图像的像素大小和沿射线采集的样本数量,因此我们可以调整这两个值以实现所需的更新速率。全尺寸图像可以从降低分辨率的图像中使用最近邻或双线性插值方法生成。如果使用双线性插值,在交互过程中,沿每个图像维度投射的射线数量通常可以减少1 / 2,从而使速度提高4倍,而图像质量不会明显下降。进一步的加速可以通过更大的缩减来实现,但代价是图像模糊、不那么详细。
如果我们不减少沿着每条射线采集的样本数量,我们可以实现光线投射的渐进细化方法。在交互过程中,我们可以只计算沿着每个图像维度的每一条射线,并使用插值来填充剩余的像素。当用户停止与场景交互时,插值像素逐渐被实际值填充。
有几种对象顺序技术可以以牺牲图像质量为代价来实现交互式渲染率。如果使用了飞溅算法,则渲染速度取决于数据集中的体素数量。可以预先计算数据的低分辨率版本,并且可以在交互过程中根据所需的帧速率选择分辨率级别。如果我们使用基于八叉树表示的飞溅方法,那么我们可以在每个父节点中包含一个近似标量值和一个错误值,其中错误值表示子节点中的标量值与父节点中的近似值的偏差程度。分层飞溅[Laur91]可以通过下降八叉树来执行,直到遇到一个小于第n个244的节点。该区域的体积对图像的贡献可以通过渲染splat的几何原语来近似[Shirley90], [Wilhelms91]。增加允许的误差将减少呈现数据所需的时间,因为允许在八叉树的更高级别上近似更大的区域。
当使用纹理映射方法进行体渲染时,可以通过减少用于表示体的纹理映射多边形的数量来实现更快的渲染速度。这本质上相当于减少沿射线在图像顺序射线投射方法中所取的样本数量。同样,如果纹理下载速率是一个瓶颈,那么一个降低分辨率的卷版本可以加载到纹理内存中进行交互。这类似于在图像顺序方法中同时减少投射的射线数量和沿着射线采集的样本数量。
7.13 Volume Rendering Future
在过去的二十年里,体绘制已经从一个需要在高端工作站上生成图像的算法的研究主题发展到一个积极发展的领域,并使用商用软件用于家用计算机。然而,随着对批量渲染需求的增加,挑战也在增加。一个典型数据集中的体素数量正在增长,这既是由于采集硬件的进步,也是由于在模拟和体图形等领域体绘制越来越受欢迎[Kaufman93]。为了满足这些大型数据集上高质量图像和交互性的相互冲突的需求,需要新的方法。此外,包含离散时间间隔采样的体积数据的时间依赖数据集对插值、图像精度和交互性提出了新的挑战,同时为分类和插值方法提供了新的机会。
本章中大部分关于体绘制的讨论都集中在常规的体数据集上。虽然很明显可以扩展大多数光线投射和对象顺序方法来可视化直线网格、结构化网格,甚至不规则数据,但在实践中,使用这些方法很难同时提供高质量的图像和交互性。这些数据类型的渲染技术仍然是体可视化中积极研究的一个领域[Cignoni96], [Silva96], [Wilhelms96]。
7.14立体渲染
到目前为止,在我们的计算机图形实践中,我们已经使用了许多技术在2D显示设备上模拟3D图形。这些技术包括使用透视和比例,赋予深度的阴影,以及看到物体的所有方面的运动/动画。然而,最有效的3D模拟技术之一是双目视差。
双眼视差是用两只眼睛观看3D物体的结果。由于每只眼睛看到的图像略有不同,我们的大脑就会通过解释这些差异来确定我们视野中物体的深度。已经有很多“3D”电影利用了我们的双眼视差。一般来说,这包括在看电影时戴一套特殊的眼镜。
这种效果在我们可视化复杂数据集和CAD模型的努力中很有价值。立体视觉提供的额外深度线索有助于我们确定场景几何形状的相对位置,以及形成场景的心理图像。有几种不同的方法
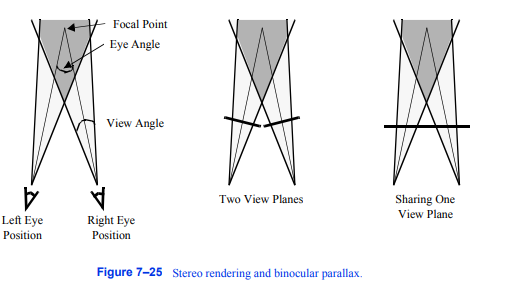
用于将双目视差引入渲染。我们将整个过程称为立体渲染,因为在这个过程中的某些点涉及到一对立体图像。
为了生成正确的左右眼图像,我们需要在第三章中介绍的相机参数之外的信息。我们需要的第一个信息是两眼之间的距离。视差产生的量可以通过调整这个距离来控制。我们还需要知道生成的图像是在一个还是两个显示器上观看。对于使用两个显示器(因此有两个视图平面)的系统,视差可以通过执行相机方位角来正确地产生,以达到左右眼的位置。头戴式显示器和臂架是两种显示系统的例子。不幸的是,这并不适用于只有一个视图平面的系统。如果在一个显示器上同时显示左右视图,会被强制显示在同一个视图平面上,如图7 - 25所示。我们早期的相机模型假设视场平面垂直于投影方向。为了处理这种不垂直的情况,我们必须平移和剪切相机的视锥体。Hodges提供了这个操作的一些细节,以及立体渲染的一个很好的概述[Hodges92]。
现在让我们来看看向用户展示立体图像的一些不同方法。大多数方法都基于两大类之一:时间多路复用技术和时间并行技术。时间多路复用方法通过在左右眼图像之间交替工作。时间并行方法同时显示两幅图像,并结合提取左右眼视图的过程。有些方法可以实现为时间多路复用或时间并行技术。
时间多路复用技术最常用于单个显示系统,因为它们依赖于交替图像。通常情况下,这与另一种方法相结合,用于交替使用哪只眼睛查看图像。一种具有成本效益的时间多路复用技术利用了现有的电视标准,如NTSC和PAL。这两个标准都使用隔行,这意味着首先在屏幕上画偶数线,然后是奇数线。通过将左眼图像渲染为屏幕的偶数线,将右眼图像渲染为奇数线,我们可以生成适合在标准电视上显示的立体声视频流。当用双眼观看时,会出现两个视图平面图7-25立体渲染和双目视差。共享一个视图平面右眼位置左眼位置视图角度角度焦点246高级计算机图形学作为一个图像不断从左向右跳转。必须佩戴一套特殊的眼镜,以便在显示左眼图像时,用户的左眼能看到,右眼也能看到。这种眼镜的设计使每个镜头都由一个液晶快门组成,可以是透明的,也可以是不透明的,这取决于施加在它上面的电压。通过以电视交错的相同速度关闭眼镜,我们可以确保用正确的眼睛观看正确的图像。
这个系统有几个缺点。与计算机显示器相比,NTSC和PAL的分辨率都较低。NTSC (60 Hz)和PAL (50 Hz)的刷新率会产生相当多的闪烁,特别是当你考虑到每只眼睛的更新频率是这个频率的一半时。此外,这种方法需要在电视上观看图像,而不是连接到计算机的显示器。
为了克服这些困难,一些电脑制造商提供立体声显卡。这些系统使用液晶百叶窗眼镜直接查看计算机显示器。为了获得交替立体图像,左眼图像被渲染到屏幕的上半部分,右眼图像被渲染到屏幕的下半部分。然后显卡进入一种特殊的立体模式,在这种模式下,显示器的刷新率会提高一倍。因此,最初以60Hz显示两种图像的显示器开始以120Hz的频率在左眼和右眼之间交替。这导致每只眼睛以60Hz的频率更新,其原始水平分辨率和原始垂直分辨率的一半。要使这个过程工作,应用程序在呈现时必须占用整个屏幕。
一些最新的显卡有一个左图像缓冲区和一个右图像缓冲区用于立体渲染。虽然这需要更多的内存或更低的分辨率,但它确实提供了立体渲染,而不必占用整个屏幕。对于这样的卡片,双缓冲与立体渲染相结合的结果是四缓冲,这可能导致每个像素有大量的比特。例如:RGB颜色为24位,后面缓冲区的颜色为24位,加上z缓冲区的24位,结果是每像素72位。现在,对于两个不同的视图,你有144位每像素或18mb 1K * 1K的显示。
时间并行技术同时显示两个图像。头戴式显示器和吊杆有两个独立的屏幕,每只眼睛一个。要生成两个视频流,要么需要两个显卡,要么需要一个可以生成两个独立输出的显卡。然后,渲染过程只涉及将每个眼睛渲染到正确的显卡或输出。目前,这种方法的最大缺点是所需硬件的成本。
相比之下,SIRDS(单图像随机点立体图)不需要特殊的硬件。两个视图同时显示在一张图中,如图7 - 26所示。要查看这样的图像,用户必须将焦点放在图像的前面或后面。当用户的焦点正确时,图像顶部的两个三角形切口将显示为一体,图像应该是聚焦的。这是因为点模式在一定的间隔内重复。在这里,结果图像中只显示深度信息。这是通过改变模式之间的间隔来实现的,就像我们的眼差随着深度的变化而变化一样。
接下来的两种立体渲染技术可以使用时间并行或时间多路复用方法实现。这种区别有点模糊,因为大多数情况下并行方法可以多路复用,尽管它通常没有什么优势。这两种方法都被电影业用来制作“3D”电影。第一种通常被称为红蓝(或红绿或红青色)立体声,要求使用者戴上一副过滤进入光线的眼镜。左眼只能通过红色滤镜看到图像,右眼只能通过蓝色滤镜看到图像。渲染过程通常包括为两个视图生成图像,转换它们的RGB

图7-26四面体单图随机点立体图。
值转换成强度,然后创建结果图像。此图像的红色值取自左眼图像强度。同样,蓝色值(蓝色和绿色的混合)取自右眼图像强度。生成的图像没有原始的色调或饱和度,但它包含了原始图像的强度。(另外注意:红-绿的方法也被使用,因为人眼对绿色比蓝色更敏感。)这种技术的好处是所产生的图像可以显示在显示器、纸张或胶片上,人们只需要一副便宜的眼镜就能看到它们。
第二种技术与第一种技术相似,但它保留了原始图像中的所有颜色信息。它利用偏振光将不同的景色分开。通常情况下,我们所看到的光具有多种偏振角度的混合,但有些透镜可以滤掉这些角度的一个子集。如果我们通过垂直偏振光滤光片投射彩色图像,然后通过另一个垂直滤光片观看它,我们将看到原始图像,只是稍微暗一些,因为我们过滤掉了所有的水平偏振光。如果我们把水平的滤镜和垂直的滤镜放在一起,所有的光都会被挡住。偏振立体渲染通常通过垂直滤镜投射一只眼睛的图像
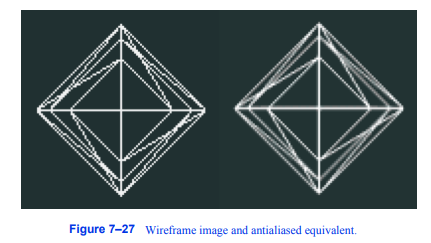
图7-27线框图像和抗锯齿等效图像。
另一个通过水平过滤器。使用者佩戴一副眼镜,一只眼睛上有垂直过滤器,另一只眼睛上有水平过滤器。这样每只眼睛都能看到正确的图像。
我们讨论的所有立体渲染方法都有各自的优点和缺点,通常围绕成本和图像质量。在本章的最后,我们将看一个使用红蓝技术渲染立体图像的示例程序。
7.15混叠
在某种程度上,大多数计算机用户都遇到过混叠问题。之所以会出现这种“阶梯”,是因为我们用离散的像素表示连续的曲面几何。在计算机图形学中,最常见的混叠问题是在渲染线条或表面边界时出现锯齿状边缘,如图7 - 27所示。
混叠问题源于图形系统将原语(如线段)转换为屏幕上的像素时的栅格化过程。例如,栅格化一行的最快方法是使用全有或全无策略。如果直线穿过像素,那么像素被设置为直线的颜色;否则,它不会被改变。如图7 - 28所示,这导致了阶梯状的外观。
有几种处理混叠问题的技术,它们统称为抗混叠技术。一种抗锯齿的方法是改变图形系统栅格化原语的方式。我们不使用全有或全无的方法来栅格化一条线,而是查看这条线占用了多少像素。该像素的结果颜色是其原始颜色和直线颜色的混合。这两种颜色的比例是由线条的占用率决定的。这在主要使用线框模型时尤其有效。类似的方法将每个像素分解成更小的子像素。原语使用全有或全无的策略呈现,但在亚像素分辨率。然后对子像素进行平均,以确定结果像素的颜色。这往往需要更多的内存。
通过将每个像素分解为10个子像素,可以获得良好的结果,这需要大约10倍的内存和渲染时间。如果您无法访问硬件亚像素渲染,您可以通过渲染一个大图,然后缩小它来近似它。使用这样的程序
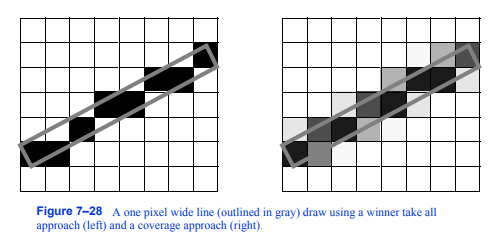
图7-28采用赢家通吃法(左)和覆盖法(右)绘制1像素宽的直线(灰色部分)。
作为pnmscale,它进行双线性插值,您可以将1000 * 1000像素的图像缩小到500 * 500的反锯齿图像。如果你有一个可以呈现到内存而不是屏幕上的图形库,那么像6000 * 6000像素这样的大图像就可以缩小成高质量的结果,而且分辨率仍然很高,比如2000 * 2000。这看起来有点过分,但在标准的600dpi彩色打印机上,这将导致图片每边超过3英寸。
最后一种抗锯齿的方法是使用一个累积缓冲区来平均一些可能出现锯齿的图像,从而产生一个抗锯齿的结果。一个累积缓冲区只是一段内存被留出执行图像操作和存储。下面的c++代码片段说明了这个过程。

我们可以使用8张没有子像素的图像,而不是每像素有8个子像素的图像。反锯齿是通过在每张图像之间稍微转换相机的位置和焦点来实现的。平移量应在一个像素大小范围内,并垂直于投影方向。当然,相机的位置是在世界坐标中指定的,而不是像素,但公式7-13可以做到这一点。我们从偏移量中计算新的相机位置和焦点(即pnew和fnew),以避免在相机位置周围的变换矩阵的困难。

图7-29 3张焦距图像。第一张没有焦距,第二张聚焦在中心物体上,第三张聚焦在最远的物体上。
式中为像素坐标的偏移量,为世界坐标的偏移量,f为相机焦点,p为相机位置,变换矩阵分别从世界坐标变换到显示坐标,从显示坐标变换到世界坐标。
7.16相机技巧
在上一节中,我们看到了如何结合积累缓冲区和小相机平移来生成反锯齿图像。在本节中,我们将介绍其他一些感兴趣的相机技术。你可能已经注意到,在计算机生成的图像中,所有的演员都是聚焦的。使用真正的相机,你必须设置焦距来匹配你拍摄的物体的距离。任何比你的焦点深度更近或更远的东西都会出现失焦。这是因为真正的相机有一个镜头,可以让光通过一个有限的区域。我们介绍的相机模型有一个点透镜,所有的光都在同一点通过。(对比如图7 - 29所示)
我们可以通过渲染许多图像来模拟有限的相机镜头,每个图像的相机位置略有不同,但焦点相同。然后我们把这些图像加起来,取平均值。所得到的图像模拟了具有焦距的相机镜头。不同的相机位置是通过从您试图模拟的镜头中随机选择点来确定的。较大直径的透镜会产生更大的畸变,反之亦然。增加随机点的数量将提高结果的精度。通常需要10到30个样品。图7 - 29中的图像使用30个样本点创建。
真正的相机和电脑相机的另一个区别在于快门速度。我们的模型生成了一个单一时刻的图像;相比之下,照片捕捉的是相机打开快门时所看到的东西。快速移动的物体由于图像的变化而显得模糊

图7-30动态模糊。快速移动的物体被记录在胶片或录像带上时显得模糊。用计算机相机模拟运动模糊,多幅图像
(或子帧)可以累积和平均。这个数字是由21个子帧累积而成的。
在快门打开的一小段时间内,它们的位置。这种效果被称为运动模糊,也可以用我们的相机模型来模拟(图7 - 30)。我们不是渲染一个图像并显示它,而是渲染几个累积、平均并最终显示的子帧。这类似于我们刚才讨论的抗锯齿和焦深技术。在这两种技术中,镜头都在抖动,而演员在时间上保持固定。为了实现动态模糊,我们不抖动相机;我们在每个子帧之间增加场景的时间。移动的物体或相机运动将导致每个子帧之间的差异。产生的图像近似于在有限时间内拍摄移动物体的效果。
7.17鼠标交互
毫无疑问,能够交互式地查看一个对象有助于理解和识别它的重要特征。使用指向设备(例如鼠标或轨迹球)当然是控制这种移动的最常见方法。这本书附带的软件包含vtk RenderWindowInteractor对象,它将鼠标和键盘事件转换为对相机和演员的修改。例如,当用户按住鼠标左键时,vtkRenderWindowInteractor将摄像机旋转到当前指针位置。指针离窗口中心越远,相机旋转速度越快。
这些相互作用大多是直接的,但有一些与旋转相关的问题。当围绕一个物体旋转时,必须决定如何处理向上的矢量。我们可以让它在旋转时垂直于投影方向,也可以保持不变。这导致了两种不同类型的旋转。如果我们保持向上的视角向量与投影方向垂直,我们将围绕物体旋转,就像飞机绕地球飞行一样。如图7 - 31左侧所示。如果我们保持向上的矢量不变,我们的飞机将在南北两极开始向后飞行,如图7 - 31的右半部分所示。
恒定向上向量的优势在于,某些对象具有自然的上下感(例如,地形)。当我们围绕物体移动时,仰角和方位角操作保持一致。另一方面,有奇点,向上的矢量和投影的方向变得平行。在这些情况下,摄像机观看变换矩阵是未定义的。然后,我们必须修改向上视图向量或使用垂直的向上视图/方向的项目

图7-31使用正交向上矢量(左)和恒定向上矢量(右)旋转。
有什么方法可以处理这种情况。如果您正在处理的数据具有明确的上下定义,那么在旋转期间保持视图向上常数可能是有意义的;否则,保持它与投影方向正交是有意义的。
7.18 3D widget和用户交互
第3章介绍了图形交互技术(参见第68页的“介绍vtkRenderWindowInteractor”)。在可视化环境中,交互是提供数据探索和查询方法的系统的基本特征。类vtkRenderWindowInteractor和vtkInteractorStyle是VTK中用于捕获呈现窗口中特定于窗口系统的事件的核心构造,将它们转换为VTK事件,然后对该事件调用采取适当的操作。在第3章中,我们看到了如何使用这些类来操作摄像机和actor以交互方式生成所需的视图。然而,这种功能在与数据交互的能力方面相对有限。例如,用户通常希望交互式地控制流线起点的定位,控制剪辑平面的方向,或转换一个actor。虽然使用解释语言(参见第68页的“解释代码”)可以很好地提供这种交互,但在某些情况下,在放置对象时看到您正在做什么的能力是必不可少的。因此,很明显,如果可视化系统要成功地支持现实世界的应用程序,就需要各种各样的用户交互技术。
3D小部件是大多数计算机系统中普遍存在的2D小部件的逻辑扩展,提供与2D小部件类似的交互功能,只是它们在更丰富的3D空间中运行。3D小部件能够提供可视化系统所需的各种用户交互技术。然而,与2D小部件不同的是,3D小部件是一种相对较新的技术,因为它们的应用环境更丰富,所以对于什么样的小部件可以构成完整的功能集还没有共识。一些流行的3D小部件集,例如Open Inventor [Wernecke94], Brown University 3D小部件库[Zeleznik93], N S N S图7-31使用正交向上向量(左)和恒定向上向量(右)的旋转。7.18 3D小部件和用户交互253和犹他大学的SCIRUN 3D小部件[Purciful95]在他们的小部件工具箱中有明显不同的组件。
小部件集根据它们所处的图形环境的感知目的而有所不同3D小部件是VTK最近添加的(参见图7 - 32)。原则上,核心功能很简单:由vtkRenderWindow捕获的事件依次转换为VTK事件。已经在vtkRenderWindow中注册了自己的观察者接收到这些VTK事件,采取适当的操作,然后可以将事件传递给列表中的下一个观察者,或者中止对事件的进一步处理。(注:观察者可以根据他们希望接收事件的顺序进行优先排序。)
正是3D小部件的实现,即它们可以对事件做什么,使它们如此强大。如图7 - 32所示,小部件通常在场景中提供一个可以选择和操作的表示。例如,vtkLineWidget可用于定位流线种子点的rake,并使用粗线(管)和两个球形端点表示自身。小部件也可以直接操作底层类——vtkScalarBarWidget允许用户交互地调整vtkScalarBar的大小、方向(水平或垂直)和位置。小部件还提供额外的功能,例如管理内部隐式函数或转换矩阵(例如,vtkBoxWidget)。下面是目前在VTK中找到的小部件列表,以及对它们功能的简要描述。
•vtkScalarBarWidget -管理vtkScalarBar,包括定位,缩放和定向。
•vtkPointWidget -定位一个点x-y-z位置在3D空间。小部件产生一个多边形输出。
•vtkLineWidget -放置直线与指定的细分分辨率。小部件产生一个多边形输出。
•vtkPlaneWidget -定位有限平面。平面分辨率是可变的,小部件产生隐式函数和多边形输出。
•vtkImplicitPlaneWidget -定位一个无界平面。小部件生成隐式函数和多边形输出。多边形输出是通过用包围框裁剪平面来创建的。
•vtkBoxWidget -定位一个包围框。小部件生成一个隐式函数和一个转换矩阵。
•vtkImagePlaneWidget -在3D体积数据集中操作三个正交平面。探测平面以获得数据位置、像素值和窗口级别是可能的。
•vtkSphereWidget -操作一个可变分辨率的球体。这个小部件生成一个隐式函数,一个转换矩阵,并支持对焦点和位置的控制,以支持诸如vtkCamera和vtkLight之类的类。
•vtkSplineWidget -操作插值3D样条。小部件生成由一系列指定分辨率的线段表示的多边形数据。小部件还直接管理每个x-y-z坐标值的底层样条。
小部件设计的关键是谨慎地实现直观、简单的用户交互技术。例如,可以选择vtkLineWidget上的端点(表示为小球体)
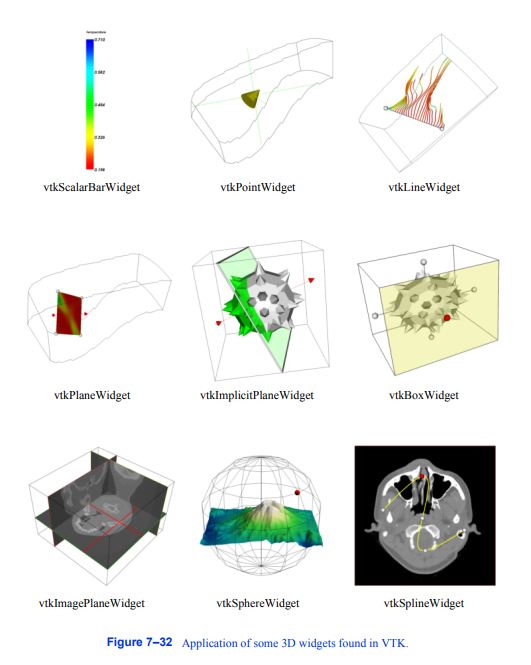
图7-32部分3D widget在VTK中的应用
被拖到一个新的位置。vtkLineWidget支持修改器“Shift”键来锁定端点沿坐标x-y-z轴的运动。初始运动方向用于确定用户沿着哪个轴移动端点。这种对细节的关注对于成功的小部件设计至关重要,并且将随着未来技术的发展而继续改变。
7.19把一切放在一起
本章涵盖了各种各样的主题。在本节中,我们将演示每个主题在一些简单问题上的应用。
纹理映射
图7 - 33显示了一个简单纹理映射示例的完整源代码。您将注意到大部分代码与我们在前面示例中使用的代码类似。这里的关键步骤是创建一个vtkTexture对象。该对象在其数据输入和图形库的纹理映射函数之间提供接口。vtkTexture实例与一个参与者相关联。多个参与者之间可以共享多个纹理实例。为了使纹理映射正常工作,纹理坐标必须由参与者的建模器定义。
关于vtkTexture对象有一个有趣的注意事项。该类的实例是具有Input实例变量的映射器,该变量在每次呈现期间都会更新。输入类型为vtkImageData数据集类型。因此,可以构建一个可视化管道来读取、处理和/或生成纹理映射。这包括使用对象vtkRendererSource,它将渲染器的图像转换为图像数据集。输入纹理映射可以是2D(像素图)或3D(体积)。
在使用纹理的时候有一些警告。一些渲染器只支持2D纹理,或者可能不支持alpha纹理。此外,许多渲染系统要求图像数据集的每个维度都是2的幂。在VTK中,两个纹理的非次幂被自动转换为两个纹理的次幂,代价是额外的计算。
体绘制
本例主要介绍体绘制。图7 - 34所示的源代码首先创建常见的对象。然后我们使用vtkStructuredPointsReader在体积数据集中读取高潜力铁蛋白。我们创建了一个vtkPiecewiseFunction对象来将体积数据集中的标量值映射到不透明度,创建了一个vtkColorTransferFunction对象来将标量值映射到颜色。这两个传递函数是从vtkVolumeProperty对象引用的。此外,我们使用vtkVolumeProperty的ShadeOn()方法为该卷启用阴影,并使用SetInterpolationTypeToLinear()方法请求三线性插值。因为我们使用的是光线投射方法,所以我们需要创建一个光线函数。在这个例子中,我们使用了一个vtkVolumeRayCastCompositeFunction对象。读取器的输出作为标量输入给vtkVolumeRayCastMapper, SetVolumeRayCastFunction()方法用于分配射线函数。vtkVolume对象非常类似于vtkActor,并且SetVolumeMapper()和SetVolumeProperty()方法的使用就像vtkActor的SetMapper()和SetProperty()方法一样。最后,我们将这个卷添加到渲染器中,调整相机,设置所需的图像更新速率并启动交互器。
为了在图7 - 34中产生最大强度的投影,我们只需将射线函数的类型更改为vtkVolumeRayCastMIPFunction。我们也可以得到一个曲面

图7-33纹理映射示例
(TPlane。tcl)。
图像使用vtkVolumeRayCastIsosurfaceFunction,其中IsoValue实例变量将被设置为定义表面。
红蓝立体
在我们的第一个例子中,我们将看到使用红蓝立体渲染。我们从图7 - 35所示的示例开始,它呈现了类似于狼牙棒的东西。然后,在图7 - 35中,我们通过在底部附近添加两行调用StereoRenderOn()和SetStereoType()方法来添加红-蓝立体渲染。一旦调用了这两个方法,进一步的渲染将在立体中完成。右上角的图片显示了结果图像的灰度版本。
动态模糊
在我们的第二个例子中,我们展示了如何使用可视化工具包模拟运动模糊。如图7 - 36所示,我们从前面的例子开始。然后我们删除控制立体渲染的两条线,并添加一些线来创建另一个杀手锏。我们将第一个杀手锏放置在渲染窗口的顶部,第二个杀手锏放置在底部。然后使用SetSubFrames()方法开始执行子帧积累。在这里,我们将进行21次渲染来生成最终的图像。为了使运动模糊明显,必须有东西在移动,所以我们设置了一个循环

图7-34高电位铁蛋白的体效图(SimpleRayCast。tcl)。

图7-35红蓝立体渲染示例(Mace3. exe)cxx)
在每个子框架之间旋转底部狼牙棒2度。它将在21个子帧上旋转
与初始位置的40度。重要的是要记住,在渲染所需数量的子帧之前,结果图像才会显示。

焦点深度
现在我们将改变前面的例子来说明焦点深度。首先,我们改变底部狼牙棒的位置,把它移得离我们更远。由于距离较远,它会显得较小,因此我们将其缩放为2倍,以保持合理的图像大小。然后我们删除渲染子帧的代码,而是设置焦距渲染的帧数。我们还将相机的焦点和焦点盘设置为适当的值。生成的图像和所需的源代码更改如图7 - 37所示。
vtkLineWidget
在VTK中有各种各样的3D小部件,它们都以类似的方式发挥作用。3D小部件是vtkInteractorObserver的一个子类,这意味着它们与vtkRenderWindow相关联,并观察渲染窗口()中的事件。(注意:vtkinteractorstyle -参见第68页的“介绍vtkRenderWindowInteractor”-也是vtkInteractorObserver的子类。交互器风格与3D小部件的不同之处在于它在场景中没有表示。)下面的例子以vtkLineWidget为例,展示了使用3D小部件的一般方法(图7 - 39)。首先实例化小部件,然后放置小部件。放置意味着小部件的定位、缩放和方向与它们所操作的对象保持一致。默认情况下,小部件是通过“keypress-i”事件启用的,但是可以修改启用小部件的特定事件。
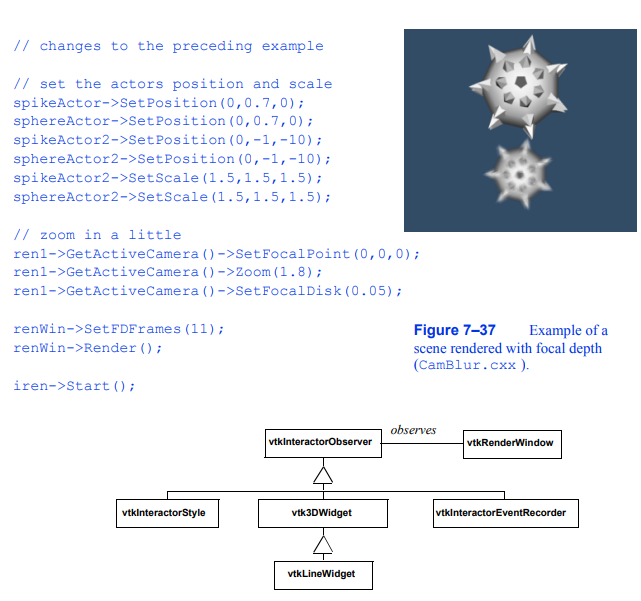
图7-38 3D小部件的部分类层次结构。每个3D小部件都观察一个特定的vtkRenderWindow,类似于vtkInteractorStyle。与用于操作相机的vtkInteractorStyle不同,3D小部件在场景中有一个可以直接操作的表示。多个vtkInteractorObserver可以在给定的时间观察一个vtkRenderWindow,因此像vtkInteractorEventRecorder这样的类可以记录一个事件并将它们传递给下一个观察vtkRenderWindow的vtkInteractorObserver。
小部件通过命令/观察者事件处理机制与应用程序进行接口(参见第63页的“事件和观察者”)。3D小部件调用几个事件,最重要的是StartInteractionEvent、InteractionEvent和EndInteractionEvent。这些事件通常分别在鼠标向下、鼠标移动和鼠标向上时调用。在这里所示的示例中,Tcl过程使用AddObserver()方法绑定到StartInteractionEvent和InteractionEvent,以便在操作小部件时生成流线。请注意,每次使用GetPolyData()方法调用InteractionEvent时,流线都会被一个多边形数据集作为种子。管道更新机制在下一次呈现时自动执行,因为流线的输入被修改了。

图7-39使用vtkLineWidget在燃烧室数据集中生成streamtubes。
StartInteractionEvent打开流线的可见性;InteractionEvent导致流线自身重新生成(LineWidget。tcl)。
7.20章节小结
Alpha不透明是一种模拟透明对象的图形方法。合成是将半透明样品按顺序混合的过程。Alpha合成要求数据正确排序。纹理映射是一种强大的技术,可以将额外的细节引入到图像中,而无需进行广泛的几何建模。将2D纹理映射应用到对象表面类似于粘贴图片。
纹理映射的位置是通过纹理坐标指定的。
体绘制是一种强大的渲染技术来查看不均匀物体的内部。大多数体绘制技术可以分为图像顺序和对象顺序,尽管有些是两者的组合,而另一些则不属于任何一类。对象顺序技术通常以从前到后或向后到前的顺序合成体素。像序技术通过像平面中的像素投射光线来对体积进行采样。其他方法可以同时遍历图像和体积,或者可以在频域中操作。图7-39使用vtkLineWidget在燃烧室数据集中生成streamtubesStartInteractionEvent打开流线的可见性;InteractionEvent导致流线自身重新生成(LineWidget。tcl)。262高级计算机图形学为了有效地可视化体积数据,分类和阴影是重要的考虑因素。感兴趣的区域可以用来减少图像中可见的数据量。由于体绘制算法的复杂性,考虑交互性的效率和方法是至关重要的。
立体渲染技术为左眼和右眼创建了两个独立的视图。这模拟了双目视差,使我们能够看到图像的深度。时间多路技术交替左眼和右眼视图在快速连续。时间并行技术同时显示两个图像。
光栅设备经常遭受混叠的影响。抗锯齿技术用于最小化锯齿的影响。这些技术创造了混合图像,软化了硬边的边界。
通过使用累积缓冲,我们可以创建有趣的效果,包括运动模糊和焦点模糊。在动态模糊中,我们随着演员的移动积累多个渲染。为了模拟焦距模糊,我们抖动相机位置并保持其焦点不变。
有效的可视化本质上是交互的。不同类型的数据不仅需要相机操作模型,而且交互、查询和修改数据的方法也是必不可少的。3D小部件是实现这一目标的重要贡献。它们通过易于操作的场景表示为数据提供直观的图形界面。3D小部件还生成补充信息,如隐式函数、输出多边形数据和转换矩阵,这些信息可能应用于场景中的对象。
7.21书目注释
关于体绘制和体可视化技术的概述可以在Kaufman的教程[Kaufman91]中找到。本章中讨论的许多体绘制技术也可以从研究机构获得源代码。剪切-翘曲算法在VolPack渲染库中提供,可以在http://wwwgraphics.stanford.edu/software/volpack/上获得。纽约州立大学石溪分校为非营利组织和政府组织提供了一个称为VolVis的交钥匙体积可视化系统。源代码和可执行版本可在http://www.cs.sunysb.edu/~volvis获得。此外,还有一个名为Vis5D的应用程序,可以将体积可视化技术应用于随时间变化的大气天气数据。Vis5D可从网站http:// vis5d.sourceforge.net获取。商业体绘制应用程序VolView是在The Visualization Toolkit基础上开发的,可从Kitware网站http:// www.kitware.com/products/volview.html获得30天的试用
7.22参考资料
[卡尔松,李志强,李志强,等。使用纹理映射硬件的加速体绘制和层析重建1994年体积可视化学术研讨会论文集。第91-98页,1994年10月。37
[Cignoni96]陈晓明,陈晓明,陈晓明,等。不规则体积数据的最优等值面提取1996年体积可视化学术研讨会论文集。第31-38页,IEEE计算机协会出版社,加州洛斯阿拉米托斯,1996年10月。
[李志强,李志强,等。体绘制。计算机图形学。22(4): 64-75 (Siggraph 1988)。
[霍奇斯]李志刚。教程:时间多路立体计算机图形学IEEE计算机图形学与应用。1992年3月。
[考夫曼91]李国强。体积可视化。IEEE计算机协会出版社,Los Alamitos, CA, 1991。
[考夫曼93]李国强,李国强。“卷图形。”IEEE计算机。26(7): 51-64, 1993年7月。
[Kelly94]李国强,李国强。CSG和透明度的硬件加速渲染计算机图形学(SIGGRAPH ' 94)。177 - 184页。
[Kikinis96]李志强,李志强,李志强,李志强,等。“用于手术计划、模型驱动分割和教学的数字大脑图谱。”IEEE可视化与计算机图形汇刊。1996年9月2(3)。
[刘志刚]刘志刚。传输理论在三维标量数据场可视化中的应用物理中的计算机。1994年7月/ 8月,第397-406页。
[文献文献]李志强,李志强。使用剪切-翘曲分解观看变换的快速体绘制。1994年SIGGRAPH学报。第451-458页,Addison-Wesley, Reading, MA, 1994。
[Laur91]李文华。分层飞溅:一种用于体绘制的渐进细化算法。在1991年的SIGGRAPH学报中。25:285 - 288, 1991。
[levoe88]李志强。从体积数据显示曲面计算机图形学与应用,8(3),pp. 29-37, 1988年5月。[Purciful95] J.T. Purciful。科学可视化和动画的三维小部件。硕士论文,计算机科学系,犹他大学,1995。
[雪莉90]李文杰。直接体绘制的多边形近似计算机图形学。24(5): 63 - 70年,1990年。
[2005]李国强,李国强。不规则网格的快速渲染。1996年体积可视化学术研讨会论文集。第15-22页,IEEE计算机协会出版社,Los Alamitos, CA, 1996年10月。264高级计算机图形学[j]。体积射线追踪的硬件加速方法在《可视化学报》95年。第27-34页,IEEE计算机协会出版社,Los Alamitos, CA, 1995年10月。
[Totsuka92]李志强。频域体绘制。计算机图形学(SIGGRAPH ' 93)。1993年8月,第271-278页。
[刘志强,李志强,等。发明家导师。Addison-Wesley, Reading MA,1994。
[韦斯特沃90]。“体绘制的占地面积评估”计算机图形学(SIGGRAPH ' 90)。24(4): 1990。
[王晓明,王晓明。直接体绘制的相干投影方法计算机图形学(SIGGRAPH ' 91)。25(4): 275 - 284年,1991年。
[j]李志强,李志强,李志强,等。不规则和多个网格的分层和可并行的直接体绘制。在1996年的《可视化学报》上。pp. 73ê80, IEEE计算机协会出版社,Los Alamitos, CA, 1996年10月。
[刘文杰,李文杰,李文杰,等。三维离散空间中的正态估计视觉计算机。第278-291页,1992。
[王晓明,张晓明。]“基于模板的卷查看。”在92年的《欧洲图形学报》上。第153-167页,1992年9月。
[蔡国强,黄宁,李志强,等。[Zeleznik93]“构建3D界面的交互式工具包。”计算机图形学(学报Siggraph ' 93)。27(4): 81 - 84。1993年7月。
[刘国强,刘国强,刘国强,等。使用3D距离变换加速光线投射《可视化与生物医学计算学报》,324-335页,1992年10月。
7.23运动
7.1在天文学中,通过保持相机的快门打开,可以拍摄出显示恒星在一段时间内运动的照片。如果不考虑地球的自转,这些照片显示了一个围绕一个共同点的圆弧漩涡。这种延时摄影本质上是在捕捉动态模糊。如果我们尝试使用本章描述的运动模糊技术来模拟这些图像,它们看起来会与照片不同。为什么会这样?你如何改变简单的运动模糊算法来纠正这个问题?
7.2在图7 - 25中,我们展示了两个视图平面和一个视图平面的立体渲染之间的区别。如果你正对着一个矩形(它的表面法线平行于你的直线- 7.23练习265),当使用两个平面的方程时,在一个视图平面上渲染会引入什么工件?
7.3在一些图形系统中,透明对象是使用一种称为屏蔽门透明的技术来渲染的。基本上,每个像素要么完全不透明,要么完全透明。任何介于两者之间的值都使用抖动逼近。因此,一个50%不透明的多边形只绘制一半像素就可以渲染。这引入了什么视觉工件?使用这种技术会出现什么混合问题?
7.4在本章中,我们将描述几种不同的反锯齿渲染技术。一种技术涉及渲染一个大图像,然后使用双线性插值将其缩小到所需的大小。另一种技术是使用相机的微小移动来渲染所需大小的多幅图像,然后将它们累积成最终图像。在使用表面表示呈现模型时,这两种技术将产生大致相同的结果。当用线框表示呈现模型时,会有显著的差异。为什么会这样?
7.5你需要创建一个卷数据集的小图像,包括在你的网页上。数据集包含体素,所需的图像大小为像素。您可以使用软件对象顺序方法将每个体素投射到图像上,或者使用软件射线投射方法为每个像素投射一条射线。假设创建了相同的图像,您将选择哪种方法,为什么?
7.6两个软件开发人员实现了体绘制方法。第一个开发人员使用软件射线投射方法,而第二个开发人员使用图形硬件纹理映射方法。灰度图像生成并显示在具有8位帧缓冲区(256级灰度)的工作站上。它们都使用相同的插值方法和相同的合成方案,但即使使用相同位置的相同数量的样本来生成图像,两种方法生成的图像也不同。为什么会这样?
7.7在一些医学数据集的分类中,标量值100 ~ 200代表皮肤,200 ~ 300代表肌肉,300 ~ 400代表骨骼。颜色转移函数将皮肤定义为棕褐色,肌肉定义为红色,骨骼定义为白色。如果我们插入标量值,然后进行分类,图像中会出现哪些分类伪影?
7.8图7 - 22所示的正常编码示例在递归深度为2的情况下产生了82个索引,这将需要7位存储空间。如果我们使用递归深度为3,有多少个下标?这代表了多少个唯一的向量方向?这需要多少位存储空间?7.9对于透视变换来说,编写对象顺序的前后投影算法比并行变换更难。解释为什么会这样,并绘制一个2D的体积图和显示截锥来说明问题。
本书为英文翻译而来,供学习vtk.js的人参考。

















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









