







RealBasicVSR 小课堂继续开课了,在上一期我们解读了真实视频超分的文章 RealBasicVSR,今天我们将手把手带大家一起使用 MMEditing 训练 RealBasicVSR。这一次我们会重点关注数据处理,希望大家看完这一期的内容后能更了解 RealBasicVSR 的训练方式和 MMEditing 的数据处理流程。
OpenMMLab:不容错过!作者亲自解读 CVPR 2022 RealBasicVSR13 赞同 · 0 评论文章正在上传…重新上传取消
RealBasicVSR 训练方式
让我们来先了解一下 RealBasicVSR 是如何训练的。 RealBasicVSR 是通过大量生成退化(例如Gaussian blur, Poisson noise, JPEG compression)的不同组合用作监督训练。通过不同退化的组合,RealBasicVSR 在一定程度上可以泛化到真实场景当中。 RealBasicVSR 使用的是 Real-ESRGAN 的二阶退化模型,下图是 Real-ESRGAN 原文中的图解: GitHub - open-mmlab/mmgeneration: MMGeneration is a powerful toolkit for generative models, based on PyTorch and MMCV.让我们来先了解一下 RealBasicVSR 是如何训练的。 RealBasicVSR 是通过大量生成退化(例如Gaussian blur, Poisson noise, JPEG compression)的不同组合用作监督训练。通过不同退化的组合,RealBasicVSR 在一定程度上可以泛化到真实场景当中。 RealBasicVSR 使用的是 Real-ESRGAN 的二阶退化模型,下图是 Real-ESRGAN 原文中的图解:
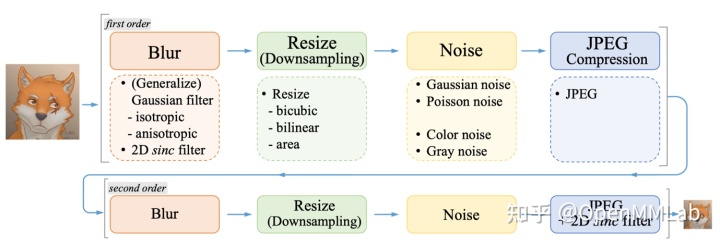
上图的二阶退化模型仅使用了 Blur, resize, noise 等等生成退化。因此,我们可以在训练中很容易获得相应的退化,在作用到高清图片中得到低清图片。 RealBasicVSR 的退化大致跟上图一样。唯一不同的是为了针对视频退化,我们在 JPEG 压缩后加上视频压缩。
定义 Model 和 Backbone
我们要先在配置文件定义 Model 和 Backbone,如下:
# model settings
model = dict(
type='RealBasicVSR',
generator=dict(
type='RealBasicVSRNet',
mid_channels=64,
num_propagation_blocks=20,
num_cleaning_blocks=20,
dynamic_refine_thres=255, # change to 1.5 for test
spynet_pretrained='https://download.openmmlab.com/mmediting/restorers/'
'basicvsr/spynet_20210409-c6c1bd09.pth',
is_fix_cleaning=False,
is_sequential_cleaning=False),
pixel_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean'),
cleaning_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean'),
is_use_sharpened_gt_in_pixel=True,
is_use_ema=True,
) 要留意的是,RealBasicVSR 需要先训练一个没有 adversarial loss 和 perceptual loss 的版本。接着使用训练好的模型初始化,加上两个损失 finetune,具体参数可以参考:https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/real_basicvsr/realbasicvsr_c64b20_1x30x8_lr5e-5_150k_reds.py。
定义数据处理流程
早期的超分辨率模型假设退化是固定的(例如 bicubic 下采样),因为不需要考虑泛他性的问题,我们只需要对于高清图片作出对应的退化得到低清图片然后保存,再在训练期间直接读取高清和低清的图片对。
但是使用二阶退化模型时,为了提高泛化性,退化的参数是随机选取的。因此,我们不能先生成图片对再直接读取。所以,我们要对数据处理作出修改:只读取高清图片,在 再加上随机退化得到低清图片。我们再来看看配置文件。从 52 行到 195 行都是我们的随机退化,我们接下来看看不同退化的设置。
RandomBlur
dict(
type='RandomBlur',
params=dict(
kernel_size=[7, 9, 11, 13, 15, 17, 19, 21],
kernel_list=[
'iso', 'aniso', 'generalized_iso', 'generalized_aniso',
'plateau_iso', 'plateau_aniso', 'sinc'
],
kernel_prob=[0.405, 0.225, 0.108, 0.027, 0.108, 0.027, 0.1],
sigma_x=[0.2, 3],
sigma_y=[0.2, 3],
rotate_angle=[-3.1416, 3.1416],
beta_gaussian=[0.5, 4],
beta_plateau=[1, 2],
sigma_x_step=0.02,
sigma_y_step=0.02,
rotate_angle_step=0.31416,
beta_gaussian_step=0.05,
beta_plateau_step=0.1,
omega_step=0.0628),
keys=['lq'],
), 首先我们会对图片加上模糊。 MMEditing 支持不同的模糊,例如 isotropic gaussian, anisotropic gaussian 等等。在使用的时候我们可以在 kernel_list 标明想使用的 kernel。另外,我们需要设置不同模糊的参数,例如 kernel_size 和各个模糊被选取的概率等等。参数的详细解释可以参考:https://github.com/open-mmlab/mmediting/blob/master/mmedit/datasets/pipelines/random_degradations.py。
值得注意的是, RealBasicVSR 提出了 stochastic degradation scheme。大概意思就是每一帧之间的退化参数都会有区别。所以我们在上述代码中可以看到 xxx_step 的设置,而 xxx_step 就是定义参数区别的大小。以 sigma_x_step 作为例子,如果现在的 sigma_x 是 0.5, 在 sigma_x_step 是 0.02 的情况下, sigma_x 在下一帧就会在 0.48 和 0.52 之间随机选取。
RandomResize
dict(
type='RandomResize',
params=dict(
resize_mode_prob=[0.2, 0.7, 0.1], # up, down, keep
resize_scale=[0.15, 1.5],
resize_opt=['bilinear', 'area', 'bicubic'],
resize_prob=[1 / 3.0, 1 / 3.0, 1 / 3.0],
resize_step=0.015,
is_size_even=True),
keys=['lq'],
), 接着就是随机更改图片大小。上述代码中看到的 resize_mode_prob 就是图片被上采样、下采样,和保持大小的概率。以 resize_scale=[0.15, 1.5] 为例子,上述代码中的设定就是一个图片会有 0.2 的概率上采样到 1x-1.5x 的大小, 0.7 的概率下采样的 0.15x-1x 的大小,和有 0.1 的概率维持现有的大小。值得注意的是,这里的 scale 是随机选取的。接着 resize_opt 就是使用什么 resize 的操作。现在 MMEditing 支持 cv2 里的 “bilinear”, “area”, 和 “bicubic”。而 resize_step 的意思和 Blur 的 xxx_step 意思一样,在一定范围内改变下一帧的 resize_scale 。我们还提供了 is_size_even 的参数,因为在作用视频压缩时,图片的大小要求是偶数。如果需要使用视频压缩时,我们需要把 is_size_even 置为 True。
RandomNoise
dict(
type='RandomNoise',
params=dict(
noise_type=['gaussian', 'poisson'],
noise_prob=[0.5, 0.5],
gaussian_sigma=[1, 30],
gaussian_gray_noise_prob=0.4,
poisson_scale=[0.05, 3],
poisson_gray_noise_prob=0.4,
gaussian_sigma_step=0.1,
poisson_scale_step=0.005),
keys=['lq'],
), 然后就是加上噪声。 MMEditing 现在支持 Gaussian 和 Poisson 两种噪声。参数的设置和之前大同小异。
RandomJPEGCompression
dict(
type='RandomJPEGCompression',
params=dict(quality=[30, 95], quality_step=3),
keys=['lq'],
),
RandomVideoCompression
dict(
type='RandomVideoCompression',
params=dict(
codec=['libx264', 'h264', 'mpeg4'],
codec_prob=[1 / 3., 1 / 3., 1 / 3.],
bitrate=[1e4, 1e5]),
keys=['lq'],
), 除了上面的图像退化外,我们在训练 RealBasicVSR 时也加上了视频压缩。 MMEditing 提供了 libx264,h264,和 mpeg4 的压缩,用户只需要注明 bit rate 就可以。
DegradationsWithShuffle
dict(
type='DegradationsWithShuffle',
degradations=[
dict(
type='RandomVideoCompression',
params=dict(
codec=['libx264', 'h264', 'mpeg4'],
codec_prob=[1 / 3., 1 / 3., 1 / 3.],
bitrate=[1e4, 1e5]),
keys=['lq'],
),
[
dict(
type='RandomResize',
params=dict(
target_size=(64, 64),
resize_opt=['bilinear', 'area', 'bicubic'],
resize_prob=[1 / 3., 1 / 3., 1 / 3.]),
),
dict(
type='RandomBlur',
params=dict(
prob=0.8,
kernel_size=[7, 9, 11, 13, 15, 17, 19, 21],
kernel_list=['sinc'],
kernel_prob=[1],
omega=[3.1416 / 3, 3.1416],
omega_step=0.0628),
),
]
],
keys=['lq'],
), 最后要介绍的是随机改变退化顺序的操作。在BSRGAN 这个工作中,退化的顺序就是随机组合,从而提高退化的多样性。 MMEditing 当然也支持这个操作。我们只需要使用 DegradationsWithShuffle ,里面的 degradations 参数就是你希望使用的退化,与个别的退化定义是一样的。在有一些情况中,你可能想保留个别退化的顺序,这时候你只需要把对应的退化放在一个 list 里就可以。例如上述代码中的 RandomResize 和 RandomBlur,因为它们在一个 list 里面,他们的顺序是保持不变的,即是永远都是先 resize 然后 blur。
定义训练和测试配置
data = dict(
workers_per_gpu=10,
train_dataloader=dict(
samples_per_gpu=2, drop_last=True, persistent_workers=False),
val_dataloader=dict(samples_per_gpu=1, persistent_workers=False),
test_dataloader=dict(samples_per_gpu=1, workers_per_gpu=1),
# train
train=dict(
type='RepeatDataset',
times=150,
dataset=dict(
type=train_dataset_type,
lq_folder='data/REDS/train_sharp_sub',
gt_folder='data/REDS/train_sharp_sub',
num_input_frames=15,
pipeline=train_pipeline,
scale=4,
test_mode=False)),
# val
val=dict(
type=val_dataset_type,
lq_folder='data/UDM10/BIx4',
gt_folder='data/UDM10/GT',
pipeline=val_pipeline,
scale=4,
test_mode=True),
# test
test=dict(
type=val_dataset_type,
lq_folder='data/VideoLQ',
gt_folder='data/VideoLQ',
pipeline=test_pipeline,
scale=4,
test_mode=True),
) # optimizer
optimizers = dict(generator=dict(type='Adam', lr=1e-4, betas=(0.9, 0.99)))
# learning policy
total_iters = 300000
lr_config = dict(policy='Step', by_epoch=False, step=[400000], gamma=1)
checkpoint_config = dict(interval=5000, save_optimizer=True, by_epoch=False)
# remove gpu_collect=True in non distributed training
evaluation = dict(interval=5000, save_image=False, gpu_collect=True)
log_config = dict(
interval=100,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
dict(type='TensorboardLoggerHook'),
])
visual_config = None
# custom hook
custom_hooks = [
dict(
type='ExponentialMovingAverageHook',
module_keys=('generator_ema', ),
interval=1,
interp_cfg=dict(momentum=0.999),
)
] 最后就是定义训练和测试时的 batch size,数据路径,优化器等等的配置。在 custom_hooks 里我们看到 ExponentialMovingAverageHook,这是对于 RealBasicVSR 的 weights 做一个 moving average,这个设计可以让表现稳定一点,大家可以留意一下。
训练过程
当把数据准备好后,我们就可以开始训练和测试。训练的时候只需要输入
./tools/dist_train.sh configs/restorers/real_basicvsr/realbasicvsr_wogan_c64b20_2x30x8_lr1e-4_300k_reds.py 8
训练完毕后可以用相同指令加上 adversarial loss 和 perceptual loss 训练:
./tools/dist_train.sh configs/restorers/real_basicvsr/realbasicvsr_c64b20_1x30x8_lr5e-5_150k_reds.py 8
要留意的是需要在第二阶段的配置文件中的 load_from 更改成第一阶段训练的模型路径。详细的训练教学可以参考:
Inference with pre-trained modelsmmediting.readthedocs.io/en/latest/quick_run.html#train-a-model
结语
MMEditing 提供了最前沿的真实图像和视频超分训练模式。我们的模块化设计也可以让大家方便的增加或减少各种退化。当你需要新的退化时,只需要写出对应的代码和修改配置文入件,不用重新写一个新的 dataloader。欢迎大家来试试,享受一下高清的快感。

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









