








基本思想
俗话说“物以类聚、人以群分”,拿看电影这个例子来说,如果你喜欢《蝙蝠侠》、《碟中谍》、《星际穿越》、《源代码》等电影,另外有个人也都喜欢这些电影,而且他还喜欢《钢铁侠》,则很有可能你也喜欢《钢铁侠》这部电影。
所以说,当一个用户 A 需要个性化推荐时,可以先找到和他兴趣相似的用户群体 G,然后把 G 喜欢的、并且 A 没有听说过的物品推荐给 A,这就是基于用户的系统过滤算法。
原理
根据上述基本原理,我们可以将基于用户的协同过滤推荐算法拆分为两个步骤:
- 找到与目标用户兴趣相似的用户集合
- 找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户
1、发现兴趣相似的用户
通常用 Jaccard 公式或者余弦相似度计算两个用户之间的相似度。设 N(u) 为用户 u 喜欢的物品集合,N(v) 为用户 v 喜欢的物品集合,那么 u 和 v 的相似度是多少呢:
Jaccard 公式:

余弦相似度:

假设目前共有4个用户: A、B、C、D;共有5个物品:a、b、c、d、e。用户与物品的关系(用户喜欢物品)如下图所示:

如何一下子计算所有用户之间的相似度呢?为计算方便,通常首先需要建立“物品—用户”的倒排表,如下图所示:
然后对于每个物品,喜欢他的用户,两两之间相同物品加1。例如喜欢物品 a 的用户有 A 和 B,那么在矩阵中他们两两加1。如下图所示:
计算用户两两之间的相似度,上面的矩阵仅仅代表的是公式的分子部分。以余弦相似度为例,对上图进行进一步计算:
到此,计算用户相似度就大功告成,可以很直观的找到与目标用户兴趣较相似的用户。


2、推荐物品
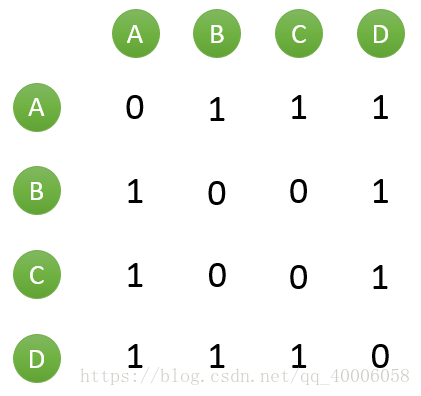
首先需要从矩阵中找出与目标用户 u 最相似的 K 个用户,用集合 S(u, K) 表示,将 S 中用户喜欢的物品全部提取出来,并去除 u 已经喜欢的物品。对于每个候选物品 i ,用户 u 对它感兴趣的程度用如下公式计算:
其中 rvi 表示用户 v 对 i 的喜欢程度,因为使用的是单一行为的隐反馈数据,在本例中 rvi 都是为 1,在一些需要用户给予评分的推荐系统中,则要代入用户评分。
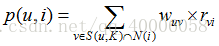
举个例子,假设我们要给 A 推荐物品,选取 K = 3 个相似用户,相似用户则是:B、C、D,那么他们喜欢过并且 A 没有喜欢过的物品有:c、e,那么分别计算 p(A, c) 和 p(A, e):
看样子用户 A 对 c 和 e 的喜欢程度可能是一样的,在真实的推荐系统中,只要按得分排序,取前几个物品就可以了。
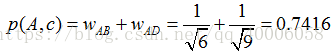
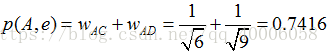
python代码
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 24 17:07:29 2018
@author: Administrator
"""
import random
import math
class UserBasedCF:
def __init__(self,datafile = None):
self.datafile = datafile
self.readData()
self.splitData(3,47)
def readData(self,datafile = None):
"""
read the data from the data file which is a data set
"""
self.datafile = datafile or self.datafile
self.data = []
for line in open(self.datafile):
userid,itemid,record,_ = line.split()
self.data.append((userid,itemid,int(record)))
def splitData(self,k,seed,data=None,M = 8):
"""
split the data set
testdata is a test data set
traindata is a train set
test data set : train data set = 1:M-1
"""
self.testdata = {}
self.traindata = {}
data = data or self.data
random.seed(seed)
for user,item, record in self.data:
if random.randint(0,M) == k:
self.testdata.setdefault(user,{})
self.testdata[user][item] = record
else:
self.traindata.setdefault(user,{})
self.traindata[user][item] = record
def userSimilarity(self,train = None):
"""
One method of getting user similarity matrix
"""
train = train or self.traindata
self.userSim = dict()
for u in train.keys():
for v in train.keys():
if u == v:
continue
self.userSim.setdefault(u,{})
self.userSim[u][v] = len(set(train[u].keys()) & set(train[v].keys()))
self.userSim[u][v] /=math.sqrt(len(train[u]) * len(train[v]) *1.0)
def userSimilarityBest(self,train = None):
"""
the other method of getting user similarity which is better than above
you can get the method on page 46
In this experiment,we use this method
"""
train = train or self.traindata
self.userSimBest = dict()
item_users = dict()
for u,item in train.items():
for i in item.keys():
item_users.setdefault(i,set())
item_users[i].add(u)
user_item_count = dict()
count = dict()
for item,users in item_users.items():
for u in users:
user_item_count.setdefault(u,0)
user_item_count[u] += 1
for v in users:
if u == v:continue
count.setdefault(u,{})
count[u].setdefault(v,0)
count[u][v] += 1
for u ,related_users in count.items():
self.userSimBest.setdefault(u,dict())
for v, cuv in related_users.items():
self.userSimBest[u][v] = cuv / math.sqrt(user_item_count[u] * user_item_count[v] * 1.0)
def recommend(self,user,train = None,k = 8,nitem = 40):
train = train or self.traindata
rank = dict()
interacted_items = train.get(user,{})
for v ,wuv in sorted(self.userSimBest[user].items(),key = lambda x : x[1],reverse = True)[0:k]:
for i , rvi in train[v].items():
if i in interacted_items:
continue
rank.setdefault(i,0)
rank[i] += wuv * rvi
return dict(sorted(rank.items(),key = lambda x :x[1],reverse = True)[0:nitem])
def recallAndPrecision(self,train = None,test = None,k = 8,nitem = 10):
"""
Get the recall and precision, the method you want to know is listed
in the page 43
"""
train = train or self.traindata
test = test or self.testdata
hit = 0
recall = 0
precision = 0
for user in train.keys():
tu = test.get(user,{})
rank = self.recommend(user, train = train,k = k,nitem = nitem)
for item,_ in rank.items():
if item in tu:
hit += 1
recall += len(tu)
precision += nitem
return (hit / (recall * 1.0),hit / (precision * 1.0))
def coverage(self,train = None,test = None,k = 8,nitem = 10):
train = train or self.traindata
test = test or self.testdata
recommend_items = set()
all_items = set()
for user in train.keys():
for item in train[user].keys():
all_items.add(item)
rank = self.recommend(user, train, k = k, nitem = nitem)
for item,_ in rank.items():
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
def popularity(self,train = None,test = None,k = 8,nitem = 10):
"""
Get the popularity
the algorithm on page 44
"""
train = train or self.traindata
test = test or self.testdata
item_popularity = dict()
for user ,items in train.items():
for item in items.keys():
item_popularity.setdefault(item,0)
item_popularity[item] += 1
ret = 0
n = 0
for user in train.keys():
rank = self.recommend(user, train, k = k, nitem = nitem)
for item ,_ in rank.items():
ret += math.log(1+item_popularity[item])
n += 1
return ret / (n * 1.0)
def testRecommend():
ubcf = UserBasedCF('data.txt')
ubcf.readData()
ubcf.splitData(4,100)
ubcf.userSimilarity()
user = "345"
rank = ubcf.recommend(user,k = 3)
for i,rvi in rank.items():
items = ubcf.testdata.get(user,{})
record = items.get(i,0)
print ("%5s: %.4f--%.4f" %(i,rvi,record))
def testUserBasedCF():
cf = UserBasedCF('data.txt')
cf.userSimilarityBest()
print ("%3s%20s%20s%20s%20s" % ('K',"recall",'precision','coverage','popularity'))
for k in [5,10,20,40,80,160]:
recall,precision = cf.recallAndPrecision( k = k)
coverage = cf.coverage(k = k)
popularity = cf.popularity(k = k)
print ("%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k,recall * 100,precision * 100,coverage * 100,popularity))
if __name__ == "__main__":
testUserBasedCF()
data
1 111 2.5
1 222 3.5
1 333 3.0
1 444 3.5
1 555 2.5
1 666 3.0
2 111 3.0
2 222 3.5
2 333 1.5
2 444 5.0
2 666 3.0
2 555 3.5
3 111 2.5
3 222 3.0
3 444 3.5
3 666 4.0
4 222 3.5
4 333 3.0
4 666 4.5
4 444 4.0
4 555 2.5
5 111 3.0
5 222 4.0
5 333 2.0
5 444 3.0
5 666 3.0
5 555 2.0
6 111 3.0
6 222 4.0
6 666 3.0
6 444 5.0
6 555 3.5
7 222 4.5
7 555 1.0
7 444 4.0
另一份代码(手撸过的)
def read_data(filename):
"""
从文件中读取数据
"""
data = []
for line in open(filename):
userid, itemid, record = line.split()
data.append([userid, itemid, float(record)])
print('data:', data)
return data
import random
def split_data(M, K, seed, data):
"""
M:将数据集分为多少分
K:[0,M]之间的随机整数
seed:种子,随意
data:待划分数据集
"""
traindata = {}
testdata = {}
random.seed(seed)
for user, item, record in data:
if random.randint(0, M) == K:
testdata.setdefault(user, {})
testdata[user][item] = record
else:
traindata.setdefault(user, {})
traindata[user][item] = record
return traindata, testdata
import math
def UserSimilarity_1(train):
"""
计算用户之间的相似度
"""
W = {}
for u in train.keys():
for v in train.keys():
if u == v: continue
W.setdefault(u, {})
W[u][v] = len(set(train[u].keys()) & set(train[v].keys()))
W[u][v] /= math.sqrt(len(train[u]) * len(train[v] * 1.0))
return W
def UserSimilarity_2(train):
"""
建立物品用户倒排表
"""
item_users = {}
for u, items in train.items():
for i in items.keys():
if i not in item_users: item_users.setdefault(i, set())
item_users[i].add(u)
"""
建立稀疏矩阵C[u][v]
"""
C = {}
N = {}
for item, users in item_users.items():
for u in users:
N.setdefault(u, 0)
N[u] += 1
for v in users:
if u == v: continue
C.setdefault(u, {})
C[u].setdefault(v, 0)
C[u][v] += 1
print('N:', N)
print('C:', C)
"""
计算相似度矩阵
"""
W = {}
for u, related_users in C.items():
W.setdefault(u, {})
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
print('W:', W)
return W
from operator import itemgetter
def recommend(user, train, W, k, nitem):
"""
user:给user推荐物品
train:训练集
W:相似度矩阵
k:推荐k个相似用户
nitem:推荐nitem个物品
"""
rank = {}
interacted_items = train[user].keys()
for v, wuv in sorted(W[user].items(), key = itemgetter(1), reverse = True)[0:k]:
for i, rvi in train[v].items():
if i in interacted_items: continue
rank.setdefault(i, 0)
rank[i] += wuv * rvi
print('rank', dict(sorted(rank.items(), key = itemgetter(1), reverse = True)[0:nitem]))
return dict(sorted(rank.items(), key = itemgetter(1), reverse = True)[0:nitem])
def recall_and_precision(train, test, k, nitem):
"""
召回率和精度
"""
hit = 0
recall = 0
precision = 0
for user in train.keys():
tu = test[user]
rank = recommend(user, train, k, nitem)
for item, pui in rank.items():
if item in tu: hit += 1
recall += len(tu)
precision += nitem
return (hit / (recall * 1.0)), (hit / (precision * 1.0))
def coverage(train, test, k, nitem):
"""
覆盖率
"""
recommend_items = set()
all_items = set()
for user in train.keys():
for item in train[user].keys():
all_items.add(item)
rank = recommend(user, train, k, nitem)
for item in rank.keys():
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
def popularity(train, test, k, nitem):
"""
新颖度
"""
item_popularity = {}
for user, items in train.items():
for item in items.keys():
if item not in item_popularity: item_popularity.setdefault(item, 0)
item_popularity[item] += 1
ret = 0
n = 0
for user in train.keys():
rank = recommend(user, train, k, nitem)
for item in rank.keys():
ret += math.log(1 + item_popularity[item])
n += 1
ret /= n * 1.0
return ret
if __name__=='__main__':
data = read_data('data.txt')
print('\n')
train, test = split_data(8, 2, 1, data)
print('\n')
W = UserSimilarity_2(train)
print('\n')
rank = recommend('6', train, W, 3, 5)
('data:', [['1', '111', 2.5], ['1', '222', 3.5], ['1', '333', 3.0], ['1', '444', 3.5], ['1', '555', 2.5], ['1', '666', 3.0], ['2', '111', 3.0], ['2', '222', 3.5], ['2', '333', 1.5], ['2', '444', 5.0], ['2', '666', 3.0], ['2', '555', 3.5], ['3', '111', 2.5], ['3', '222', 3.0], ['3', '444', 3.5], ['3', '666', 4.0], ['4', '222', 3.5], ['4', '333', 3.0], ['4', '666', 4.5], ['4', '444', 4.0], ['4', '555', 2.5], ['5', '111', 3.0], ['5', '222', 4.0], ['5', '333', 2.0], ['5', '444', 3.0], ['5', '666', 3.0], ['5', '555', 2.0], ['6', '111', 3.0], ['6', '222', 4.0], ['6', '666', 3.0], ['6', '444', 5.0], ['6', '555', 3.5], ['7', '222', 4.5], ['7', '555', 1.0], ['7', '444', 4.0]])
('N:', {'1': 5, '3': 4, '2': 6, '5': 6, '4': 4, '7': 2, '6': 3})
('C:', {'1': {'3': 3, '2': 5, '5': 5, '4': 3, '7': 2, '6': 3}, '3': {'1': 3, '2': 4, '5': 4, '4': 2, '7': 1, '6': 3}, '2': {'1': 5, '3': 4, '5': 6, '4': 4, '7': 2, '6': 3}, '5': {'1': 5, '3': 4, '2': 6, '4': 4, '7': 2, '6': 3}, '4': {'1': 3, '3': 2, '2': 4, '5': 4, '7': 1, '6': 1}, '7': {'1': 2, '3': 1, '2': 2, '5': 2, '4': 1, '6': 1}, '6': {'1': 3, '3': 3, '2': 3, '5': 3, '4': 1, '7': 1}})
('W:', {'1': {'3': 0.6708203932499369, '2': 0.9128709291752769, '5': 0.9128709291752769, '4': 0.6708203932499369, '7': 0.6324555320336759, '6': 0.7745966692414834}, '3': {'1': 0.6708203932499369, '2': 0.8164965809277261, '5': 0.8164965809277261, '4': 0.5, '7': 0.35355339059327373, '6': 0.8660254037844387}, '2': {'1': 0.9128709291752769, '3': 0.8164965809277261, '5': 1.0, '4': 0.8164965809277261, '7': 0.5773502691896258, '6': 0.7071067811865476}, '5': {'1': 0.9128709291752769, '3': 0.8164965809277261, '2': 1.0, '4': 0.8164965809277261, '7': 0.5773502691896258, '6': 0.7071067811865476}, '4': {'1': 0.6708203932499369, '3': 0.5, '2': 0.8164965809277261, '5': 0.8164965809277261, '7': 0.35355339059327373, '6': 0.2886751345948129}, '7': {'1': 0.6324555320336759, '3': 0.35355339059327373, '2': 0.5773502691896258, '5': 0.5773502691896258, '4': 0.35355339059327373, '6': 0.4082482904638631}, '6': {'1': 0.7745966692414834, '3': 0.8660254037844387, '2': 0.7071067811865476, '5': 0.7071067811865476, '4': 0.2886751345948129, '7': 0.4082482904638631}})
('rank', {'555': 4.411365407256625, '333': 3.3844501795042716, '444': 6.566622819178273})














 1577
1577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









