









1 论文原文


2 理解
2.1 本文目的
通过AutoEncoder模型来预测用户-物品矩阵(评分矩阵M x N.)中缺失的评分值。
2.2 模型
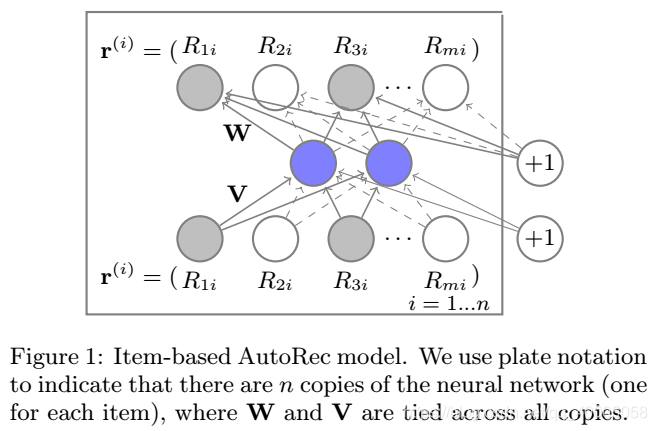
1、模型输入
item-based:每个item用各个user对它的打分作为其向量描述(user-based:每个user用该user对各个item的打分作为输入)。
2、模型输出
将模型对input重建后的新向量里对应位置的值认为是预测值
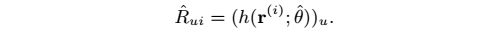
3、模型优化目标
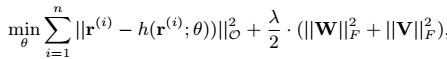
后一项为防止过拟合加入的正则项。需要注意的是第一项里在计算loss只在观测到的数据上计算。未观测到的missing value在初始时赋一个默认值,比如1-5分的打分体系里统一给3(文中实验部分用红色框标出)。
2.3 实验结果
通过对比各个模型的实验结果:
(1)item-based AutoRec胜出user-based AutoRec,比传统的FM类方法都要更好。(这可能是由于每个项目评分的平均数量是高于每个用户的输入评分数;用户评分数量的高方差导致基于用户的方法的预测不可靠)。
(2)sigmoid好于RELU。
(3)随着hidden 层节点数增加,RMSE越来越小。

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









