







 本文介绍如何使用Python的pandas库处理和分析地铁线路断面客流数据,通过数据清洗、字段提取及循环导出,实现单方向及双方向断面流量统计。
本文介绍如何使用Python的pandas库处理和分析地铁线路断面客流数据,通过数据清洗、字段提取及循环导出,实现单方向及双方向断面流量统计。
查看数据

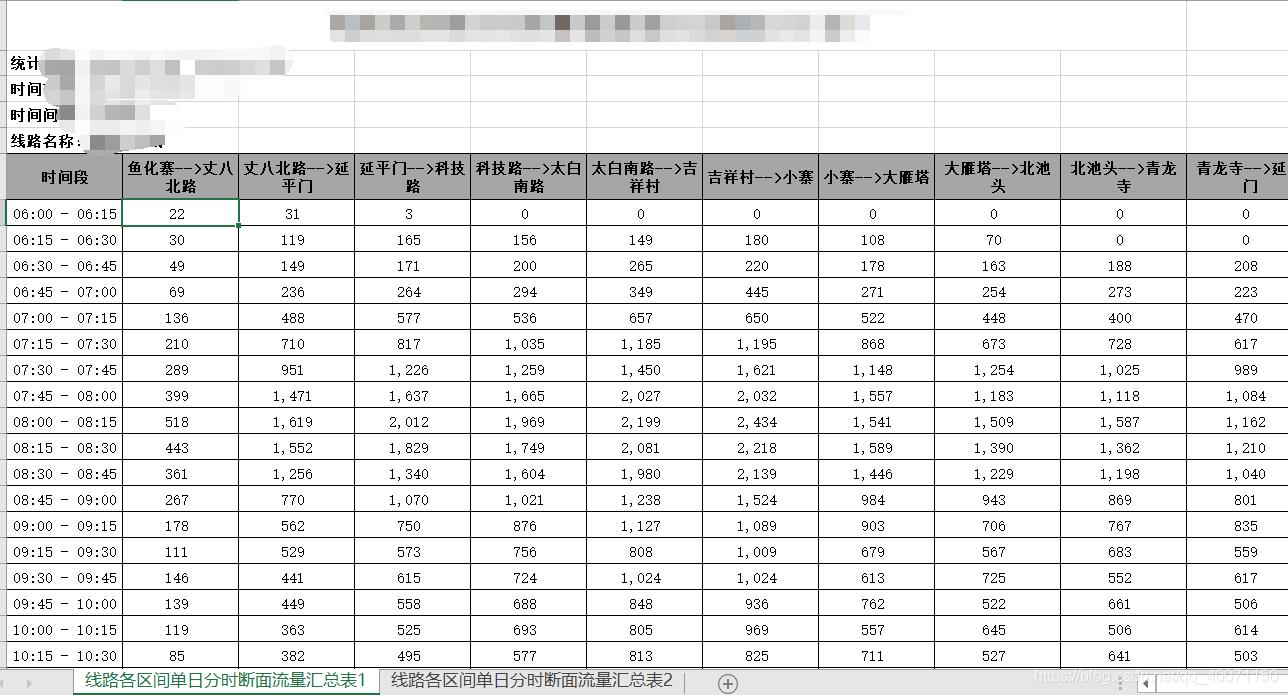
分析需求
- 使用pandas查看数据构成
- 生成目标数据的dataframe格式
- 做好目标数据的定位
- 将列名提取生成列表,循环读取
- 将文件夹和文件合并为列表做内循环
直接上代码
import pandas as pd
import numpy as np
import os
## 读取数据
df = pd.read_excel(r"D:\pythonProject\3号线断面客流数据\20161220线路各区间某日分时断面流量汇总表.xlsx",
sheet_name='线路各区间单日分时断面流量汇总表1',header=5,index_col=0)
# df = pd.read_excel(r"D:\pythonProject\3号线断面客流数据\20161220线路各区间某日分时断面流量汇总表.xlsx",
# sheet_name='线路各区间单日分时断面流量汇总表1')#第一次查看数据使用
df.head()
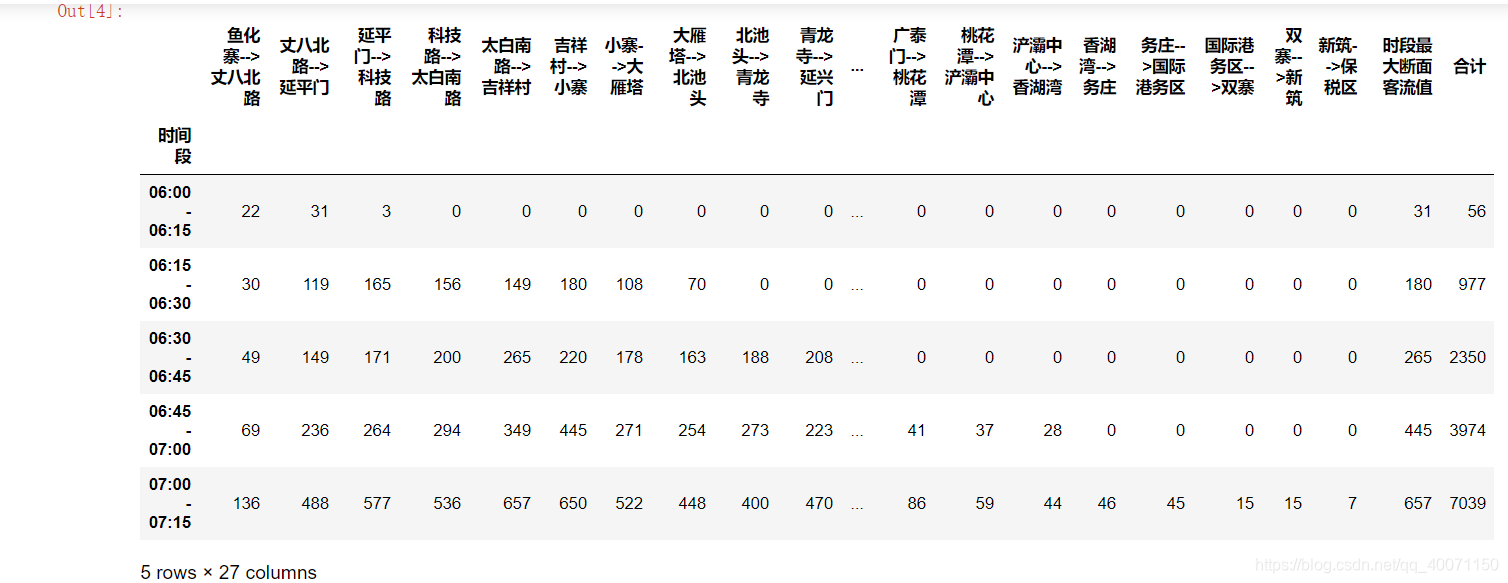
#去除不需要的列字段
df=df.drop(['时段最大断面客流值','合计'],axis=1)
# 做一个测列名称转换打印测试
sample_list = df.columns.tolist()
# sample_list.remove('时间段')
for sample_num in sample_list:
sample_num = sample_num.replace('-->','-')
print (sample_num)

接下来做一个循环遍历字段并以字段为文件名导出的小循环体
sample_list = df.columns.tolist()
# sample_list.remove('时间段')
for sample_num in sample_list:
sample_df = df.loc[:,[sample_num]]
sample_num = sample_num.replace('-->','-')
save_name = str(sample_num) + ".xlsx"
sample_df.to_excel(os.path.join(r"D:/pythonProject/3号线断面客流数据/dataup", save_name), sheet_name='Sheet1' ,index=True)
小循环体执行成功,说明单文件多字段列可以生成文件,接下来有多种做法,可供参考。
本文只使用了先循环字段再循环数据表后合成;
dir = r"D:\pythonProject\3号线断面客流数据"
all_file_list=os.listdir(dir)
sample_list = df.columns.tolist()
# sample_list.remove('时间段')
for sample_num in sample_list:
all_data = pd.DataFrame()
for file in all_file_list:
if file.endswith('xlsx'):
df2 = pd.read_excel(os.path.join(dir,file),sheet_name='线路各区间单日分时断面流量汇总表1',header=5,index_col=0)
# df =df.drop(['时段最大断面客流值','合计'],axis=1)
# if file ==all_file_list[0]:
# sample_df =df2.loc[:,[sample_num]]
# all_data = sample_df
# else:
sample_df =df2.loc[:,[sample_num]]
all_data = pd.concat([all_data, sample_df],axis=1)
sample_num = sample_num.replace('-->','-')
save_name = str(sample_num) + ".xlsx"
all_data.to_excel(os.path.join(r"D:/pythonProject/3号线断面客流数据/data上行", save_name), sheet_name='Sheet1' ,index=True)
执行以上程序,即可完成单方向的断面流量统计,如图
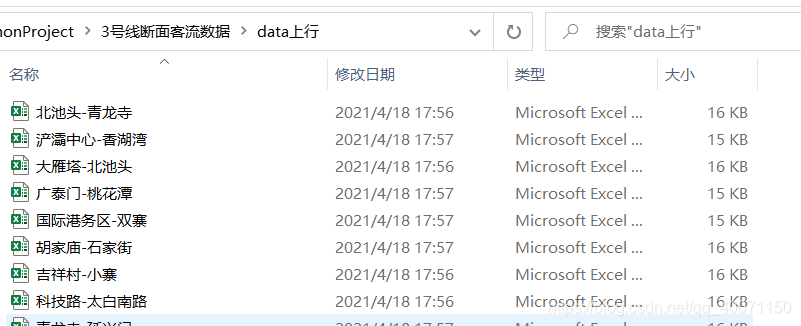
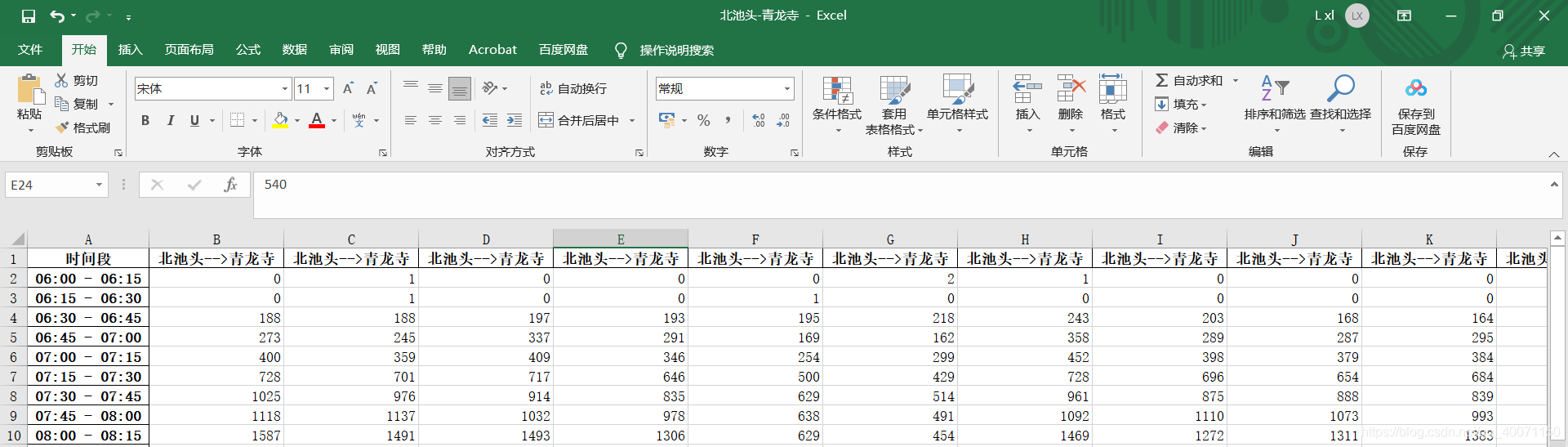
下行断面可同理按照步骤生成
df3 = pd.read_excel(r"D:\pythonProject\3号线断面客流数据\20161220线路各区间某日分时断面流量汇总表.xlsx",
sheet_name='线路各区间单日分时断面流量汇总表2',header=5,index_col=0)
df3=df3.drop(['时段最大断面客流值','合计'],axis=1)
dir = r"D:\pythonProject\3号线断面客流数据"
all_file_list=os.listdir(dir)
sample_list = df3.columns.tolist()
for sample_num in sample_list:
all_data = pd.DataFrame()
for file in all_file_list:
if file.endswith('xlsx'):
df4 = pd.read_excel(os.path.join(dir,file),sheet_name='线路各区间单日分时断面流量汇总表2',header=5,index_col=0)
sample_df =df4.loc[:,[sample_num]]
all_data = pd.concat([all_data, sample_df],axis=1)
sample_num = sample_num.replace('-->','-')
save_name = str(sample_num) + ".xlsx"
all_data.to_excel(os.path.join(r"D:/pythonProject/3号线断面客流数据/data下行", save_name), sheet_name='Sheet1' ,index=True)
至此,15行代码解决一个大工程,宣布完工(当然个人技术较菜,做了很多‘有意义’的尝试,踩了很多坑,另附博文说明有价值的尝试)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









