







① jieba.analyse.extract_tags 提取关键字:
第一个参数:待提取关键词的文本
第二个参数:返回关键词的数量,重要性从高到低排序
第三个参数:是否同时返回每个关键词的权重
第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
print("***案例1***"*3)
txt='那些你很冒险的梦,我陪你去疯,折纸飞机碰到雨天终究会坠落,伤人的话我直说,因为你会懂,冒险不冒险你不清楚,折纸飞机也不会回来,做梦的人睡不醒!'
Key=jieba.analyse.extract_tags(txt,topK=3)
print(Key)
#-----------------------------------------------------------------------------------
print("***案例2***"*3)
# 字符串前面加u表示使用unicode编码
import jieba.analyse
content = u'《小丑》全球票房已经超过十亿美元,成为全球首部达到这个成绩的R级电影。而其自身出色的投资回报率也让其成为史上盈利数最高的“超英漫改”作品。而在几个月前,它更加夺目的一项荣耀则是首部获得威尼斯电影节最高荣誉奖的“主流”“超英漫改”作品。'
# 第一个参数:待提取关键词的文本
# 第二个参数:返回关键词的数量,重要性从高到低排序
# 第三个参数:是否同时返回每个关键词的权重
# 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
keywords = jieba.analyse.extract_tags(content, topK=5, withWeight=True, allowPOS=())
print(keywords)
输出结果:
key:

keywords:
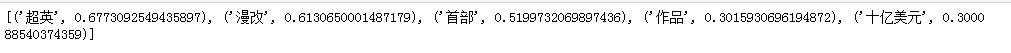
② jieba.analyse.textrank 提取关键字:
# 同样是四个参数,但allowPOS默认为('ns', 'n', 'vn', 'v')
# 即仅提取地名、名词、动名词、动词
keywords = jieba.analyse.textrank(content, topK=5, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))
# 访问提取结果
keywords
keywords:仅仅输出地名、名词、动名词、动词


















 2363
2363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









