







第三章 多表查询
本章目录
/****** SSMS 的 SelectTopNRows 命令的脚本 ******/
SELECT TOP (1000) [EMPNO]
,[ENAME]
,[JOB]
,[MGR]
,[HIREDATE]
,[SAL]
,[COMM]
,[DEPTNO]
FROM [Text_02].[dbo].[emp]
--叠加两个行集
--union all 合并多个表的行,重复项一并纳入
select ename as ename_and_dname,deptno from emp
where deptno = 10
union all
select '----------',null from t1
union all
select dname, deptno from dept
--滤除重复项,则用union
select deptno from emp
union
select deptno from dept
--union等同于union all+distinct
select distinct deptno from
( select deptno from emp
union all
select deptno from dept) x
--合并相关行
--显示部门编号为10的全部员工的名字及其部门所在地
select e.ename, d.loc, e.deptno from emp e, dept d
where e.deptno = d.deptno
and e.deptno=10
--使用join子句实现上面的功能
select e.ename, d.loc from emp e
inner join dept d on (e.deptno = d.deptno)
where e.deptno = 10
--查找两个表中相同的行
--step1--创建视图
create view V as
select ename,job,sal from emp
where job='CLERK'
select * from V
--step2--把多个表中所有必要的列都连接起来
select e.empno, e.ename, e.job, e.sal, e.deptno from emp e, V
where e.ename=v.ename
and e.job=v.job
and e.sal=v.sal
--用jion实现step2--把多个表中所有必要的列都连接起来
select e.empno, e.ename, e.job, e.sal, e.deptno from emp e join V
on ( e.ename=v.ename
and e.job=v.job
and e.sal=v.sal )
--查找只存在于一个表中的数据
--使用子查询得到emp表中所有的deptno,并将该结果传入外层查询
--外层查询检索dept表,找出没有出现在子查询结果中的deptno值
select deptno from dept
where deptno not in (select deptno from emp)
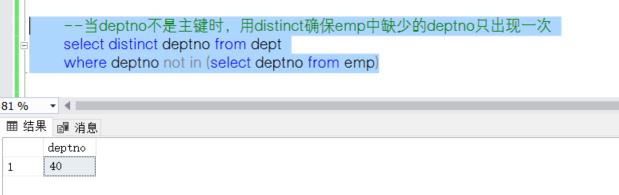
--当deptno不是主键时,用distinct确保emp中缺少的deptno只出现一次
select distinct deptno from dept
where deptno not in (select deptno from emp)
--in和not in本质上是or运算
select deptno from dept
where deptno in (10,50,null)
select deptno from dept
where (deptno=10 or deptno=50 or deptno = null )
--in和not in本质上是or运算
select deptno from dept
where deptno not in (10,50,null)
select deptno from dept
where not (deptno=10 or deptno=50 or deptno = null )
/**********************************************************笔记区******************************************
join=inner join 将满足条件的A、B两表都列出来, 没有匹配到则不显示
A left join B 从A表中返回所有的行,即使B表中没有匹配的项, A--匹配->B
A right join B 从B表中返回所有的行,即使A表中没有匹配的项, A<-匹配--B
full join 以上两个查询结果合并即列出没有匹配的项
*********************************************************************************************************/
--从一个表中检索与另一个表不相关的行
select d.* from dept d
left outer join emp e on (d.deptno=e.deptno)
where e.deptno is null
-- d<-匹配--e
select e.ename, e.deptno as emp_deptno , d.* from dept d --从d表中返回所有的行,即使e表中没有匹配的项,e表放左边
left join emp e on (d.deptno=e.deptno) --order by 1
-- d--匹配->e
select e.ename, e.deptno as emp_deptno , d.* from dept d --从e表中返回所有的行,即使d表中没有匹配的项,e表放左边
right join emp e on (d.deptno=e.deptno) --order by 1
--新增连接查询而不影响其他连接查询
select e.ename, d.loc ,eb.received from
emp e join dept d on (e.deptno=d.deptno)
left join emp_bonus eb on (e.empno=eb.empno)
order by 2
--确定两个表是否有相同的数据
--step 1创建拿来比较的视图
create view V as
select * from emp where deptno !=10
union all
select * from emp where ename='word' --union all 会使得名叫word的那一行重复
select * from V
--step 2 列出视图V1与emp不同之处、重复的也找出来
--找出存在于内嵌视图e(外查询)中而不存在于内嵌视图v(内查询)的数据
select * from (select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e --记录每一行数据出现的次数并作为单独一列显示
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e --内嵌视图e
--group by多字段分组,所有字段都相同视为一组
--视图e是将emp表中的相同行去掉,并用cnt记录重复次数,
where not exists --not exists:子查询查询到有结果则返回false,没有查询到结果返回true
--
( select null from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
union all
--找出存在于视图e中而不存在于视图e的数据
select * from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
--视图v是将 前一个的视图v 中的相同行去掉,并用cnt记录重复次数,
where not exists (
select null from
(select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
/**********************************************************笔记区*************************************
如果select null 查询出表中有需要的数据时,EXISTS的表达是为TRUE的。
当select null 查询一个表中不存在的结果时,EXISTS的表达为FALSE
select null 与 EXISTS 配合使用时,作为EXISTS的子条件去查询,
SELECT * FROM TABLE WHERE EXISTS(SELECT NULL FROM TABLE1 where ....)
如果select null 可以查询到满足where条件的数据,那么则会把TABLE里的数据全部返回,
否则就返回空数据集。
select null 与NOT EXISTS 配合使用时,作为NOT EXISTS的子条件去查询,
SELECT * FROM TABLE WHERE NOT EXISTS(SELECT NULL FROM TABLE1 where ....)
如果select null 可以查询到满足where条件的数据,那么则不会把TABLE的数据进行返回,
如果select null 查询不到满足where条件的数据,就会把TABLE的所有数据进行返回。与EXISTS使用方法相反。
EXISTS内部有一个子查询语句(SELECT … FROM…)
将外查询表的每一行,代入内查询作为检验,
如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,
否则不能作为结果。
**********************************************************************************************/
--重要段落分解
--在本例中null可以换成1,整个程序段返回结果一致,
--不一致在于下面两个段落建立的视图v返回的值分别是null和1。
--两者结果都非空,故not exist 判定都为false,即筛去相同的行。
select null from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
select 1 from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
--使用select 1 from代替 select null from,结果运行一致
select * from (select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e
where not exists
( select 1 from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
union all
select * from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
where not exists (
select 1 from
(select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
--step 2扩展
--列出视图V1与emp均只出现一次且相同的数据行(在视图e和视图v中会先进行计数,计数不同则判定为不同行)
--not exists-->exists union all--> union
select * from (select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e
where exists
( select 1 from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
union
select * from (select v.empno, v.ename, v.job, v.mgr, v.hiredate,
v.sal, v.comm,v.deptno, count(*) as cnt from v
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) v
where exists (
select 1 from
(select e.empno, e.ename, e.job, e.mgr, e.hiredate,
e.sal, e.comm,e.deptno, count(*) as cnt from emp e
group by empno,ename, job, mgr, hiredate, sal, comm, deptno) e
where v.empno=e.empno
and v.ename=e.ename
and v.job=e.job
and v.mgr=e.mgr
and v.hiredate=e.hiredate
and v.sal=e.sal
and v.cnt=e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
--识别并消除笛卡尔积
--错误案例(存笛卡尔积)
select e.ename, d.loc from emp e, dept d
where e.deptno=10
--正确的查询,在多表查询中添加恰当的条件
select e.ename, d.loc from emp e, dept d
where e.deptno=10 and d.deptno=e.deptno
/*****************************此例报错,暂不考虑********************************************************
--组合使用连接查询与聚合函数
--执行一个聚合操作,但查询语句涉及多个表,必须确保表之间的连接查询不会干扰聚合操作
--计算部门编号为10的员工的工资总额以及奖金总和
--有部门员工多次获得奖金
--在emp表和enp_bonus表连接之后在执行聚合函数sum,得到的结果是错误的
select * from emp_bonus
--TYPE=1 奖金为工资的10%
--TYPE=2 奖金为工资的20%
--TYPE=3 奖金为工资的30%
select e.empno ,e.ename , sum (distinct e.sal ) over
(partition by e.deptno) as total_sal, e.deptno, --partition by 按…分组
sum( e.sal*case
when eb.type=1 then .1
when eb.type=2 then .2
else .3 end ) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb
where e.empno=eb.empno and e.deptno=10
select distinct deptno ,total_sal, total_bonus from
(
select e.empno, e.ename,
sum( distinct e.sal) over
(partition by e.deptno) as total_sal, e.deptno,
sum( e.sal*case
when eb.type=1 then .1
when eb.type=2 then .2
else .3 end) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb
where e.empno=eb.empno and e.deptno=10 ) x
***********************************************************************************************************/
----组合使用外连接查询与聚合函数
--查询出部门编号为10的员工的工资总额和
select * from emp_bonus1
--TYPE=1 奖金为工资的10%
--TYPE=2 奖金为工资的20%
--TYPE=3 奖金为工资的30%
/* EMPNO RECEIVED TYPE
7934 2005-03-17 00:00:00 1
7934 2005-02-15 00:00:00 2
*/
--编号7934的员工有type分别为1和2的两次奖金,
select deptno ,
sum( distinct sal ) as total_sal ,
sum( bonus) as total_bonus
from (
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type is null then 0
when eb.type=1 then .1
when eb.type=2 then .2
else .3 end as bonus
from emp e left outer join emp_bonus1 eb --左外连接:就是把左边表的数据全部取出来,
on (e.empno=eb.empno) --而右边表的数据有相等的,显示出来,如果没有,显示NULL
where e.deptno =10 ) y
group by deptno
--从多个表中返回缺失值
--找到存在于dept表而不存在于emp表的数据-----即没有员工的部门
--使用全外连接 full outer join
--step1 插入新数据,插入时使用表里的数据
insert into emp (empno,ename,job,mgr,hiredate,sal,comm,deptno)
select 1111,'YODA','JEDI',null,hiredate,sal,comm,null from emp where ename ='KING'
--select * from emp
--DELETE FROM emp WHERE ename='YODA'
select d.deptno, d.dname, e.ename
from dept d right outer join emp e
on (d.deptno=e.deptno)
--step2 使用全外连接列出所有没匹配的项
select d.deptno ,d.dname, e.ename
from dept d full outer join emp e
--from dept d left outer join emp e
-- from dept d right outer join emp e
on (d.deptno=e.deptno)
--全外连接查询其实就是合并两个表的外连接查询的结果集
select d.deptno ,d.dname, e.ename
from dept d right outer join emp e
on (d.deptno=e.deptno)
union
select d.deptno ,d.dname, e.ename
from dept d left outer join emp e
on (d.deptno=e.deptno)
--在运算和比较中使用null
--null不等于任何值,甚至不能与其自身进行比较
--找出emp表中有业务提成(comm)比员工word低的所有员工
select ename , comm, coalesce(comm,0) from emp
where coalesce(comm,0) < (select comm from emp where ename ='WORD')
叠加两个行集



合并两个相关行


查找两个表中相同的行



查找只存在于一个表中的数据



从一个表中检索与另一个表不相关的行




新增连接查询而不影响其他连接查询

新增后

确定两个表是否有相同的数据





在本例中null可以换成1,整个程序段返回结果一致



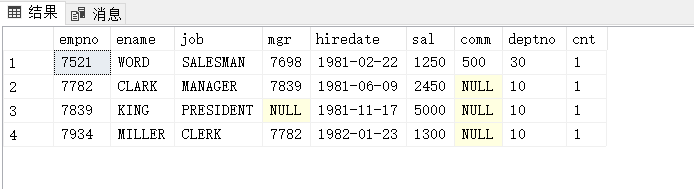
列出视图V1与emp均只出现一次且相同的数据行(在视图e和视图v中会先进行计数,计数不同则判定为不同行)



识别并消除笛卡尔积


组合使用外连接查询与聚合函数


从多个表中返回缺失值



在运算和比较中使用null,则需要使用coalesce(comm,0)函数
















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









