Anwen
目录
[TOC]
时间复杂度
时间复杂度是衡量算法好坏的重要指标之一。时间复杂度反映的是不确定性样本量的增长对于算法操作所需时间的影响程度,与算法操作是否涉及到样本量以及涉及了几次直接相关,如遍历数组时时间复杂度为数组长度n(对应时间复杂度为O(n)),而对数据的元操作(如加减乘除与或非等)、逻辑操作(如if判断)等都属于常数时间内的操作(对应时间复杂度O(1))。
在化简某算法时间复杂度表达式时需遵循以下规则:
- 对于同一样本量,可省去低阶次数项,仅保留高阶次数项,如O(n^2)+O(n)可化简为O(n^2),O(n)+O(1)可化简为O(n)
- 可省去样本量前的常量系数,如O(2n)可化简为O(n),O(8)可化简为O(1)
- 对于不同的不确定性样本量,不能按照上述两个规则进行化简,要根据实际样本量的大小分析表达式增量。如O(logm)+O(n^2)不能化简为O(n^2)或O(logm)。而要视m、n两者之间的差距来化简,比如m>>n时可以化简为O(logm),因为表达式增量是由样本量决定的。
额外空间复杂度
算法额外空间复杂度指的是对于输入样本,经过算法操作需要的额外空间。比如使用冒泡排序对一个数组排序,期间只需要一个临时变量temp,那么该算法的额外空间复杂度为O(1)。又如归并排序,在排序过程中需要创建一个与样本数组相同大小的辅助数组,尽管在排序过后该数组被销毁,但该算法的额外空间复杂度为O(n)。
经典例题——举一反三
找出B中不属于A的数
找出数组B中不属于A的数,数组A有序而数组B无序。假设数组A有n个数,数组B有m个数,写出算法并分析时间复杂度。
方法一:遍历
首先遍历B,将B中的每个数拿到到A中找,若找到则打印。对应算法如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | int A[] = {1, 2, 3, 4, 5};
int B[] = {1, 4, 2, 6, 5, 7};
for (int i = 0; i < 6; ++i) {
int temp = B[i];
bool flag = false;
for (int j = 0; j < 5; ++j) {
if (A[j] == temp) {
flag = true; //找到了
break;
}
}
if (!flag) { //没找到
printf("%d", temp);
}
}
|
不难看出上述算法的时间复杂度为O(m*n),因为将两个数组都遍历了一遍
由于数组A是有序的,在一个有序序列中查找一个元素可以使用二分法(也称折半法)。原理就是将查找的元素与序列的中位数进行比较,如果小于则去掉中位数及其之后的序列,如果大于则去掉中位数及其之前的序列,如果等于则找到了。如果不等于那么再将其与剩下的序列继续比较直到找到或剩下的序列为空为止。

利用二分法对应题解的代码如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | for (int i = 0; i < 6; ++i) { //B的长度为6
int temp = B[i];
//二分法查找
int left = 0,right = 5-1; //A的长度为5
int mid = (left + right) / 2;
while (left < right && A[mid] != temp) {
if (A[mid] > temp) {
right = mid - 1;
} else {
left = mid + 1;
}
mid = (left + right) / 2;
}
if (A[mid] != temp) {
printf("%d", temp);
}
}
|
for循环m次,while循环logn次(如果没有特别说明,log均以2为底),此算法的时间复杂度为O(mlogn)
方法三:排序+外排
第三种方法就是将数组B也排序,然后使用逐次比对的方式来查找A数组中是否含有B数组中的某元素。引入a、b两个指针分别指向数组A、B的首元素,比较指针指向的元素值,当ab时说明A中不存在该元素,打印该元素并跳过该元素的查找,向后移动b。直到a或b有一个到达数组末尾为止(若a先到达末尾,那么b和b之后的数都不属于A)

对应题解的代码如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | void fun3(int A[],int a_length,int B[],int b_length){
quickSort(B, 0, b_length - 1); //使用快速排序法对数组B排序->O(mlogm)
int* a = A,*b=B;
while (a <= A + a_length - 1 || b <= B + b_length - 1) {
if (*a == *b) {
b++;
continue;
}
if (*a > *b) {
printf("%d", *b);
b++;
} else {
a++;
}
}
if (a == A + a_length) { //a先到头
while (b < B + b_length) {
printf("%d", *b);
b++;
}
}
}
|
快速排序的代码如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | #include
#include
//交换两个int变量的值
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
//产生一个low~high之间的随机数
int randomInRange(int low, int high){
srand((int) time(0));
return (rand() % (high - low))+low;
}
//快速排序的核心算法,随机选择一个数,将比该数小的移至数组左边,比该数大的移至
//数组右边,最后返回该数的下标(移动完之后该数的下标可能与移动之前不一样)
int partition(int arr[],int start,int end){
if (arr == NULL || start < 0 || end <= 0 || start > end) {
return -1;
}
int index = randomInRange(start, end);//随机选择一个数
swap(arr[index], arr[end]);//将该数暂时放至末尾
int small = start - 1;
//遍历前n-1个数与该数比较并以该数为界限将前n-1个数
//分为两组,small指向小于该数的那一组的最后一个元素
for (index = start; index < end; index++) {
if (arr[index] < arr[end]) {
small++;
if (small != index) {
swap(arr[small], arr[index]);
}
}
}
//最后将该数放至数值较小的那一个组的中间
++small;
swap(arr[small], arr[end]);
return small;
}
void quickSort(int arr[],int start,int end) {
if (start == end) {
return;
}
int index = partition(arr, start, end);
if (index > start) {
quickSort(arr,start, index - 1);
}
if (index < end) {
quickSort(arr, index + 1, end);
}
}
|
此种方法的时间复杂度为:O(mlogm)(先对B排序)+O(m+n)(最坏的情况是指针a和b都到头)。
三种方法的比较
- O(m*n)
- O(mlogn)(以2为底)
- O(mlogm)+O(m+n)(以2为底)
易知算法2比1更优,因为增长率logn >n那么2更优,不难理解:数组B元素较多,那么对B的 排序肯定要花费较长时间,而这一步并不是题解所必需的,不如采用二分法;相反地,若m<
荷兰国旗问题
给定一个数组arr,和一个数num,请把小于num的数放在数组的左边,等于num的数放在数组的中间,大于num的数放在数组的右边。
要求额外空间复杂度O(1),时间复杂度O(N)
思路:利用两个指针L、R,将L指向首元素之前,将R指向尾元素之后。从头遍历序列,将当前遍历元素与num比较,若num,则将其与L的右一个元素交换位置并遍历下一个元素、右移L;若=num则直接遍历下一个元素;若>num则将其和R的左一个元素交换位置,并重新判断当前位置元素与num的关系。直到遍历的元素下标到为R-1为止。
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
void partition(int arr[],int startIndex,int endIndex,int num){
int L = startIndex - 1, R = endIndex + 1, i = startIndex;
while (i <= R - 1) {
if (arr[i] < num) {
swap(arr[i++], arr[++L]);
} else if (arr[i] > num) {
swap(arr[i], arr[--R]);
} else {
i++;
}
}
}
int main(){
int arr[] = {1,2, 1, 5, 4, 7, 2, 3, 9,1};
travles(arr, 8);
partition(arr, 0, 7, 2);
travles(arr, 8);
return 0;
}
|
L代表小于num的数的右界,R代表大于num的左界,partition的过程就是遍历元素、不断壮大L、R范围的过程。这里比较难理解的地方可能是为什么arr[i]num时却不左移R,这是因为对于当前元素arr[i],如果arr[i]num进行swap(arr[i],arr[R-1])之后对于当前元素的数据状况是不清楚的,因为R-1>=i,arr[R-1]还没遍历到。
矩阵打印问题
转圈打印方块矩阵
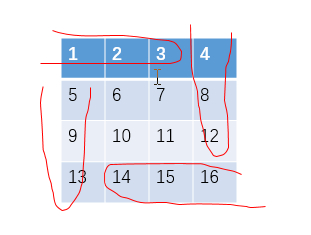
给定一个4阶矩阵如下:

打印结果如下(要求额外空间复杂度为O(1)):
复制代码
| 1 | 1 2 3 4 8 12 16 15 14 13 9 5 6 7 11 10
|
思路:这类问题需要将思维打开,从宏观的层面去找出问题存在的共性从而求解。如果你的思维局限在1是如何变到2的、4是怎么变到8的、11之后为什么时10、它们之间有什么关联,那么你就陷入死胡同了。
从宏观的层面找共性,其实转圈打印的过程就是不断顺时针打印外围元素的过程,只要给你一个左上角的点(如(0,0))和右下角的点(如(3,3)),你就能够打印出1 2 3 4 8 12 16 15 14 13 9 5;同样,给你(1,1)和(2,2),你就能打印出6 7 11 10。这个根据两点打印正方形上元素的过程可以抽取出来,整个问题也就迎刃而解了。
打印一个矩阵某个正方形上的点的逻辑如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | //
// Created by zaw on 2018/10/21.
//
#include
#define FACTORIAL 4
void printSquare(int leftUp[], int rigthDown[],int matrix[][FACTORIAL]){
int i = leftUp[0], j = leftUp[1];
while (j < rigthDown[1]) {
printf("%d ", matrix[i][j++]);
}
while (i < rigthDown[0]) {
printf("%d ", matrix[i++][j]);
}
while (j > leftUp[1]) {
printf("%d ", matrix[i][j--]);
}
while (i > leftUp[0]) {
printf("%d ", matrix[i--][j]);
}
}
void printMatrixCircled(int matrix[][FACTORIAL]){
int leftUp[] = {0, 0}, rightDown[] = {FACTORIAL-1,FACTORIAL-1};
while (leftUp[0] < rightDown[0] && leftUp[1] < rightDown[1]) {
printSquare(leftUp, rightDown, matrix);
++leftUp[0];
++leftUp[1];
--rightDown[0];
--rightDown[1];
}
}
int main(){
int matrix[4][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12},
{13, 14, 15, 16}
};
printMatrixCircled(matrix);//1 2 3 4 8 12 16 15 14 13 9 5 6 7 11 10
}
|
旋转方块矩阵
给定一个方块矩阵,请把该矩阵调整成顺时针旋转90°之后的样子,要求额外空间复杂度为O(1)。

思路:拿上图举例,首先选取矩阵四个角上的点1,3,9,7,按顺时针的方向1到3的位置(1->3)、3->9、9->7、7->1,这样对于旋转后的矩阵而言,这四个点已经调整好了。接下来只需调整2,6,8,4的位置,调整方法是一样的。只需对矩阵第一行的前n-1个点采用同样的方法进行调整、对矩阵第二行的前前n-3个点……,那么调整n阶矩阵就容易了。
这也是在宏观上观察数据变动的一般规律,找到以不变应万变的通解(给定一个点,确定矩阵上以该点为角的正方形,将该正方形旋转90°),整个问题就不攻自破了。

复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | //
// Created by zaw on 2018/10/21.
//
#include
#define FACTORIAL 4
void circleSquare(int leftUp[],int rightDown[],int matrix[][FACTORIAL]){
int p1[] = {leftUp[0], leftUp[1]};
int p2[] = {leftUp[0], rightDown[1]};
int p3[] = {rightDown[0], rightDown[1]};
int p4[] = {rightDown[0],leftUp[1]};
while (p1[1] < rightDown[1]) {
//swap
int tmp = matrix[p4[0]][p4[1]];
matrix[p4[0]][p4[1]] = matrix[p3[0]][p3[1]];
matrix[p3[0]][p3[1]] = matrix[p2[0]][p2[1]];
matrix[p2[0]][p2[1]] = matrix[p1[0]][p1[1]];
matrix[p1[0]][p1[1]] = tmp;
p1[1]++;
p2[0]++;
p3[1]--;
p4[0]--;
}
}
void circleMatrix(int matrix[][FACTORIAL]){
int leftUp[] = {0, 0}, rightDown[] = {FACTORIAL - 1, FACTORIAL - 1};
while (leftUp[0] < rightDown[0] && leftUp[1] < rightDown[1]) {
circleSquare(leftUp, rightDown, matrix);
leftUp[0]++;
leftUp[1]++;
--rightDown[0];
--rightDown[1];
}
}
void printMatrix(int matrix[][FACTORIAL]){
for (int i = 0; i < FACTORIAL; ++i) {
for (int j = 0; j < FACTORIAL; ++j) {
printf("%2d ", matrix[i][j]);
}
printf("\n");
}
}
int main(){
int matrix[FACTORIAL][FACTORIAL] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12},
{13, 14, 15, 16}
};
printMatrix(matrix);
circleMatrix(matrix);
printMatrix(matrix);
}
|
之字形打印矩阵

对如上矩阵的打印结果如下(要求额外空间复杂度为O(1)):
复制代码
| 1 | 1 2 7 13 8 3 4 9 14 15 10 5 6 11 16 17 12 18
|
此题也是需要从宏观上找出一个共性:给你两个,你能否将该两点连成的45°斜线上的点按给定的打印方向打印出来。拿上图举例,给出(2,0)、(0,2)和turnUp=true,应该打印出13,8,3。那么整个问题就变成了两点的走向问题了,开始时两点均为(0,0),然后一个点往下走,另一个点往右走(如1->7,1->2);当往下走的点是边界点时就往右走(如13->14),当往右走的点到边界时就往下走(如6->12)。每次两点走一步,并打印两点连线上的点。
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | //
// Created by zaw on 2018/10/22.
//
#include
const int rows = 3;
const int cols = 6;
void printLine(int leftDown[],int rightUp[], bool turnUp,int matrix[rows][cols]){
int i,j;
if (turnUp) {
i = leftDown[0], j = leftDown[1];
while (j <= rightUp[1]) {
printf("%d ", matrix[i--][j++]);
}
} else {
i = rightUp[0], j = rightUp[1];
while (i <= leftDown[0]) {
printf("%d ", matrix[i++][j--]);
}
}
}
void zigZagPrintMatrix(int matrix[rows][cols]){
if (matrix==NULL)
return;
int leftDown[] = {0, 0}, rightUp[] = {0, 0};
bool turnUp = true;
while (leftDown[1] <= cols - 1) {
printLine(leftDown, rightUp, turnUp, matrix);
turnUp = !turnUp;
if (leftDown[0] < rows - 1) {
leftDown[0]++;
} else {
leftDown[1]++;
}
if (rightUp[1] < cols - 1) {
++rightUp[1];
} else {
++rightUp[0];
}
}
}
int main(){
int matrix[rows][cols] = {
{1, 2, 3, 4, 5, 6},
{7, 8, 9, 10, 11, 12},
{13, 14, 15, 16, 17, 18}
};
zigZagPrintMatrix(matrix);//1 2 7 13 8 3 4 9 14 15 10 5 6 11 16 17 12 18
return 0;
}
|
在行和列都排好序的矩阵上找数
如图:

任何一列或一行上的数是有序的,实现一个函数,判断某个数是否存在于矩阵中。要求时间复杂度为O(M+N),额外空间复杂度为O(1)。
从矩阵右上角的点开始取点与该数比较,如果大于该数,那么说明这个点所在的列都不存在该数,将这个点左移;如果这个点上的数小于该数,那么说明这个点所在的行不存在该数,将这个点下移。直到找到与该数相等的点为止。最坏的情况是,该数只有一个且在矩阵左下角上,那么时间复杂度为O(M-1+N-1)=O(M+N)
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | //
// Created by zaw on 2018/10/22.
//
#include
const int rows = 4;
const int cols = 4;
bool findNumInSortedMatrix(int num,int matrix[rows][cols]){
int i = 0, j = cols - 1;
while (i <= rows - 1 && j <= cols - 1) {
if (matrix[i][j] > num) {
--j;
} else if (matrix[i][j] < num) {
++i;
} else {
return true;
}
}
return false;
}
int main(){
int matrix[rows][cols] = {
{1, 2, 3, 4},
{2, 4, 5, 8},
{3, 6, 7, 9},
{4, 8, 9, 10}
};
if (findNumInSortedMatrix(7, matrix)) {
printf("find!");
} else {
printf("not exist!");
}
return 0;
}
|
岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上、下、左、右四个位置相连,如果有一片1连在一起,这个部分叫做一个岛,求一个矩阵中有多少个岛?
比如矩阵:
就有3个岛。
分析:我们可以遍历矩阵中的每个位置,如果遇到1就将与其相连的一片1都感染成2,并自增岛数量。
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | public class IslandNum {
public static int getIslandNums(int matrix[][]){
int res = 0 ;
for(int i = 0 ; i < matrix.length ; i++){
for(int j = 0 ; j < matrix[i].length ; j++){
if(matrix[i][j] == 1){
res++;
infect(matrix , i , j);
}
}
}
return res;
}
public static void infect(int matrix[][], int i ,int j){
if(i < 0 || i >= matrix.length || j < 0 || j >= matrix[i].length || matrix[i][j] != 1){
return;
}
matrix[i][j] = 2;
infect(matrix , i-1 , j);
infect(matrix , i+1 , j);
infect(matrix , i , j-1);
infect(matrix , i , j+1);
}
public static void main(String[] args){
int matrix[][] = {
{1,0,0,1,0,1},
{0,1,1,0,0,0},
{1,0,0,0,1,1},
{1,1,1,1,1,1}
};
System.out.println(getIslandNums(matrix));
}
}
|
经典结构和算法
字符串
KMP算法是由一个问题而引发的:对于一个字符串str(长度为N)和另一个字符串match(长度为M),如果match是str的子串,请返回其在str第一次出现时的首字母下标,若match不是str的子串则返回-1。
最简单的方法是将str从头开始遍历并与match逐次比较,若碰到了不匹配字母则终止此次遍历转而从str的第二个字符开始遍历并与match逐次比较,直到某一次的遍历每个字符都与match匹配否则返回-1。易知此种做法的时间复杂度为O(N*M)。
KMP算法则给出求解该问题时间复杂度控制在O(N)的解法。
首先该算法需要对应match创建一个与match长度相同的辅助数组help[match.length],该数组元素表示match某个下标之前的子串的前后缀子串最大匹配长度。前缀子串表示一个串中以串首字符开头的不包含串尾字符的任意个连续字符,后缀子串则表示一个串中以串尾字符结尾的不包括串首字符的任意个连续字符。比如abcd的前缀子串可以是a、ab、abc,但不能是abcd,而abcd的后缀字串可以是d、cd、bcd,但不能是abcd。再来说一下help数组,对于char match[]="abc1abc2"来说,有help[7]=3,因为match[7]='2',因此match下标在7之前的子串abc1abc的前缀子串和后缀子串相同的情况下,前缀子串的最大长度为3(即前缀字串和后缀字串都取abc);又如match="aaaab",有help[4]=3(前缀子串和后缀子串最大匹配长度当两者为aaa时取得),相应的有help[3]=2、help[2]=1。
假设当要寻找的子串match的help数组找到之后(对于一个串的help数组的求法在介绍完KMP算法之后再详细说明)。就可以进行KMP算法求解此问题了。KMP算法的逻辑(结论)是,对于str的i~(i+k)部分(i、i+k均为str的合法下标)和match的0~k部分(k为match的合法下标),如果有str[i]=match[0]、str[i+1]=match[1]……str[i+k-1]=match[k-1],但str[i+k]!=[k],那么str的下标不用从i+k变为i+1重新比较,只需将子串str[0]~str[i+k-1]的最大匹配前缀子串的后一个字符cn重新与str[i+k]向后依次比较,后面如果又遇到了不匹配的字符重复此操作即可:

当遇到不匹配字符时,常规的做法是将str的遍历下标sIndex移到i+1的位置并将match的遍历下标mIndex移到0再依次比较,这种做法并没有利用上一轮的比较信息(对下一轮的比较没有任何优化)。而KMP算法则不是这样,当遇到不匹配的字符str[i+k]和match[k]时,str的遍历指针sIndex=i+k不用动,将match右滑并将其遍历指针mIndex打到子串match[0]~match[k-1]的最大匹配前缀子串的后一个下标n的位置。然后sIndex从i+k开始,mIndex从n开始,依次向后比较,若再遇到不匹配的数则重复此过程。
对应代码如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | void length(char* str){
if(str==NULL)
return -1;
int len=0;
while(*(str++)!='\0'){
len++;
}
return len;
}
int getIndexOf(char* str,char* m){
int slen = length(str) , mlen = length(m);
if(mlen > slen)
return -1;
int help[mlen];
getHelpArr(str,help);
int i=0,j=0; //sIndex,mIndex
while(i < slen && j < mlen){
if(str[i] == m[j]){
i++;
j++;
}else if(help[j] != -1){
j = help[j]; //mIndex -> cn's index
}else{ //the first char is not match,move the sIndex
i++;
}
}
return j == mlen ? i - mlen : -1;
}
|
可以发现KMP算法中str的遍历指针并没有回溯这个动作(只向后移动),当完成匹配时sIndex的移动次数小于N,否则sIndex移动到串尾也会终止循环,所以while对应的匹配过程的时间复杂度为O(N)(if(help[j] != -1){ j = help[j] }的执行次数只会是常数次,因此可以忽略)。
下面只要解决如何求解一个串的help数组,此问题就解决了。help数组要从前到后求解,直接求help[n]是很难有所头绪的。当串match长度mlen=1时,规定help[0]=-1。当mlen=2时,去掉match[1]之后只剩下match[0],最大匹配子串长度为0(因为前缀子串不能包含串尾字符,后缀子串不能包含串首字符),即help[1]=0。当mlen>2时,help[n](n>=2)都可以推算出来:

如上图所示,如果我们知道了help[n-1],那么help[n]的求解有两种情况:如果match[cn]=match[n-1],那么由a区域与b区域(a、b为子串match[0~n-2]的最大匹配前缀子串和后缀字串)相同可知help[n]=help[n-1]+1;如果match[cn]!=match[n-1],那么求a区域中下一个能和b区域后缀子串中匹配的较大的一个,即a区域的最大匹配前缀字串c区域,将match[n-1]和c区域的后一个位置(cn')上的字符比较,如果相等则help[n]等于c区域的长度+1,而c区域的长度就是help[cn](help数组的定义如此);如果不等则将cn打到cn'的位置继续和match[n-1]比较,直到cn被打到0为止(即help[cn]=-1为止),那么此时help[n]=0。
对应代码如下:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | int* getHelpArr(char* s,int help[]){
if(s==NULL)
return NULL;
int slen = length(s);
help[0]=-1;
help[1]=0;
int index = 2;//help数组从第三个元素开始的元素值需要依次推算
int cn = 0; //推算help[2]时,help[1]=0,即s[1]之前的字符组成的串中不存在最大匹配前后子串,那么cn作为最大匹配前缀子串的后一个下标自然就是0了
while(index < slen){
if(s[index-1] == s[cn]){ //if match[n-1] == match[cn]
help[index] = help[index-1] + 1;
index++;
cn++;
}else if(help[cn] == -1){ //cn reach 0
help[index]=0;
index++;
cn++;
}else{
cn = help[cn]; //set cn to cn' and continue calculate help[index]
}
}
return help;
}
|
那么这个求解help数组的过程的时间复杂度如何计算呢?仔细观察克制while循环中仅涉及到index和cn这两个变量的变化:
| 第一个if分支 | 第二个if分支 | 第三个if分支 |
|---|
| index | 增大 | 增大 | 不变 |
| index-cn | 不变 | 不变 | 增大 |
可以发现while循环执行一次不是index增大就是index-cn增大,而index < slen、index - cn < slen,即index最多自增M(match串的长度)次 ,index-cn最多增加M次,如此while最多执行M+M次,即时间复杂为O(2M)=O(M)。
综上所述,使用KMP求解此问题的时间复杂度为O(M)(求解match的help数组的时间复杂度)+O(N)(匹配的时间复杂度)=O(N)(因为N > M)。
KMP算法的应用
-
判断一个二叉树是否是另一棵二叉树的子树(即某棵树的结构和数据状态和另一棵二叉树的子树样)。
思路:如果这棵树的序列化串是另一棵树的序列化串的子串,那么前者必定是后者的子树。
前缀树(字典树)
前缀树的介绍
前缀树是一种存储字符串的高效容器,基于此结构的操作有:
设计思路:该结构的重点实现在于存储。前缀树以字符为存储单位,将其存储在结点之间的树枝上而非结点上,如插入字符串abc之后前缀树如下:

每次插入串都要从头结点开始,遍历串中的字符依次向下“铺路”,如上图中的abc3条路。对于每个结点而言,它可以向下铺a~z26条不同的路,假如来到某个结点后,它要向下铺的路(取决于遍历到哪个字符来了)被之前插入串的过程铺过了那么就可以直接走这条路去往下一个结点,否则就要先铺路再去往下一个结点。如再插入串abde和bcd的前缀树将如下所示:

根据前缀树的search和prefixNumber两个操作,我们还需要在每次铺路后记录以下每个结点经过的次数(across),以及每次插入操作每个结点作为终点结点的次数(end)。
前缀树的实现
前缀树的实现示例:
复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 | public class TrieTree {
public static class TrieNode {
public int across;
public int end;
public TrieNode[] paths;
public TrieNode() {
super();
across = 0;
end = 0;
paths = new TrieNode[26];
}
}
private TrieNode root;
public TrieTree() {
super();
root = new TrieNode();
}
//向树中插入一个字符串
public void insert(String str) {
if (str == null || str.length() == 0) {
return;
}
char chs[] = str.toCharArray();
TrieNode cur = root;
for (char ch : chs) {
int index = ch - 'a';
if (cur.paths[index] == null) {
cur.paths[index] = new TrieNode();
}
cur = cur.paths[index];
cur.across++;
}
cur.end++;
}
//查询某个字符串插入的次数
public int search(String str) {
if (str == null || str.length() == 0) {
return 0;
}
char chs[] = str.toCharArray();
TrieNode cur = root;
for (char ch : chs) {
int index = ch - 'a';
if (cur.paths[index] == null) {
return 0;
}else{
cur = cur.paths[index];
}
}
return cur.end;
}
//删除一次插入过的某个字符串
public void delete(String str) {
if (search(str) > 0) {
char chs[] = str.toCharArray();
TrieNode cur = root;
for (char ch : chs) {
int index = ch - 'a';
if (--cur.paths[index].across == 0) {
cur.paths[index] = null;
return;
}
cur = cur.paths[index];
}
cur.end--;
}
}
//查询所有插入的字符串中,以prefix为前缀的有多少个
public int prefixNumber(String prefix) {
if (prefix == null || prefix.length() == 0) {
return 0;
}
char chs[] = prefix.toCharArray();
TrieNode cur = root;
for (char ch : chs) {
int index = ch - 'a';
if (cur.paths[index] == null) {
return 0;
}else{
cur = cur.paths[index];
}
}
return cur.across;
}
public static void main(String[] args) {
TrieTree tree = new TrieTree();
tree.insert("abc");
tree.insert("abde");
tree.insert("bcd");
System.out.println(tree.search("abc")); //1
System.out.println(tree.prefixNumber("ab")); //2
}
}
|
前缀树的相关问题
一个字符串类型的数组arr1,另一个字符串类型的数组arr2:
- arr2中有哪些字符,是arr1中出现的?请打印
- arr2中有哪些字符,是作为arr1中某个字符串前缀出现的?请打印
- arr2中有哪些字符,是作为arr1中某个字符串前缀出现的?请打印arr2中出现次数最大的前缀。
数组
冒泡排序的核心是从头遍历序列。以升序排列为例:将第一个元素和第二个元素比较,若前者大于后者,则交换两者的位置,再将第二个元素与第三个元素比较,若前者大于后者则交换两者位置,以此类推直到倒数第二个元素与最后一个元素比较,若前者大于后者,则交换两者位置。这样一轮比较下来将会把序列中最大的元素移至序列末尾,这样就安排好了最大数的位置,接下来只需对剩下的(n-1)个元素,重复上述操作即可。

复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
void bubbleSort(int arr[], int length) {
if(arr==NULL || length<=1){
return;
}
for (int i = length-1; i > 0; i--) { //只需比较(length-1)轮
for (int j = 0; j < i; ++j) {
if (arr[j] > arr[j + 1]) {
swap(&arr[j], &arr[j + 1]);
}
}
}
}
|
该算法的时间复杂度为n+(n-1)+...+1,很明显是一个等差数列,由(首项+末项)*项数/2求其和为(n+1)n/2,可知时间复杂度为O(n^2)
以升序排序为例:找到最小数的下标minIndex,将其与第一个数交换,接着对子序列(1-n)重复该操作,直到子序列只含一个元素为止。(即选出最小的数放到第一个位置,该数安排好了,再对剩下的数选出最小的放到第二个位置,以此类推)

复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | void selectionSort(int arr[], int length) {
for (int i = 0; i < length-1; ++i) { //要进行n-1次选择,选出n-1个数分别放在前n-1个位置上
if(arr==NULL || length<=1){
return;
}
int minIndex = i; //记录较小数的下标
for (int j = i+1; j < length; ++j) {
if (arr[minIndex] > arr[j]) {
minIndex = j;
}
}
if (minIndex != i) {
swap(&arr[minIndex],&arr[i]);
}
}
}
|
同样,不难得出该算法的时间复杂度(big o)为O(n^2)(n-1+n-2+n-3+…+1)
插入排序的过程可以联想到打扑克时揭一张牌然后将其到手中有序纸牌的合适位置上。比如我现在手上的牌是7、8、9、J、Q、K,这时揭了一张10,我需要将其依次与K、Q、J、9、8、7比较,当比到9时发现大于9,于是将其插入到9之后。对于一个无序序列,可以将其当做一摞待揭的牌,首先将首元素揭起来,因为揭之前手上无牌,因此此次揭牌无需比较,此后每揭一次牌都需要进行上述的插牌过程,当揭完之后,手上的握牌顺序就对应着该序列的有序形式。

复制代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
void insertionSort(int arr[], int length){
if(arr==NULL || length<=1){
return;
}
for (int i = 1; i < length; ++i) { //第一张牌无需插入,直接入手,后续揭牌需比较然后插入,因此从第二个元素开始遍历(插牌)
//将新揭的牌与手上的逐次比较,若小于则交换,否则停止,比较完了还没遇到更小的也停止
for (int j = i - 1; j >= 0 || arr[j] <= arr[j + 1]; j--) {
if (arr[j] > arr[j + 1]) {
swap(&arr[j], &arr[j + 1]);
}
}
}
}
|
插入排序的big o该如何计算?可以发现如果序列有序,那么该算法的big o为O(n),因为只是遍历了一次序列(这时最好情况);如果序列降序排列,那么该算法的big o为O(n^2)(每次插入前的比较交换加起来要:1+2+…+n-1)(最坏情况)。一般应用场景中都是按算法的最坏情况来考量算法的效率的,因为你做出来的应用要能够承受最坏情况。即该算法的big o为O(n^2)
























 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









