









![]()
许多web开发工程师对于HTTP协议等相关的知识并没有系统的学习过,讲起这一块内容的时候总是模糊不清,对于返回的状态码可能只清楚:401、404、500…?但其实不论是前端、还是后端,牢固的掌握HTTP知识是非常必要的。在面试时,HTTP这部分的内容也是面试官必问的内容。
所以为了让自己以后能在web开发这条路上走的更加顺畅,我也专门拿出几小时来恶补一波了HTTP知识,写一篇学习笔记记录下。
本文内容是基于Jokcy老师的教学视频:HTTP协议原理+实践 Web开发工程师必学 学习Web开发必备技能 夯实基础进行学习的,
下载链接请戳这篇文章的底部→HTTP协议原理+实践 Web开发工程师必学
希望大家有能力的情况下还是多支持正版,去慕课网购买课程观看,这样以后以后才有更多更优秀的视频出现。
HTTP协议基础
1. 五层网络模型
-
应用层
物理层主要作用是定义物理设备如何传输数据
-
传输层
数据链路层在通信的实体间建立数据链路连接
-
网络层
网络层为数据在节点之间传输创建逻辑链路
-
数据链路层
向用户提供可靠的端到端(End-to-End)服务、传输层向高层屏蔽了下层数据通信的细节
-
物理层
为应用软件提供了很多服务、构建于TCP之上、屏蔽网络传输相关细节
2. HTTP协议的发展历史
-
HTTP/0.9
- 只有一个
Get命令 - 没有
Header等描述数据的信息 - 服务器发送完毕,就关闭
TCP连接
- 只有一个
-
HTTP/1.0
- 增加了很多命令
- 增加了
status code和header - 多字符集支持、多部分发送、权限、缓存等
-
HTTP/1.1
- 持久连接
pipeline- 增加host和其他一些命令
-
HTTP2
- 所有数据以二进制传输
- 同一个连接里面发送多个请求不再需要按照顺序来
- 头信息压缩以及推送等提高效率的功能
3. HTTP的三次握手
三次握手主要是为了规避这些网络传输延迟而导致服务器开销浪费的问题。
4. URI、URL、URN
-
URI(Uniform Resource Identifier)/统一资源标识符,用来唯一标识互联网上的信息资源,包括了URL和URN
-
URL(Uniform Resource Locator)/统一资源定位器
-
URN(永久统一资源定位符),在资源移动后还能被找到,目前还没有非常成熟的使用方案
5. 报文格式
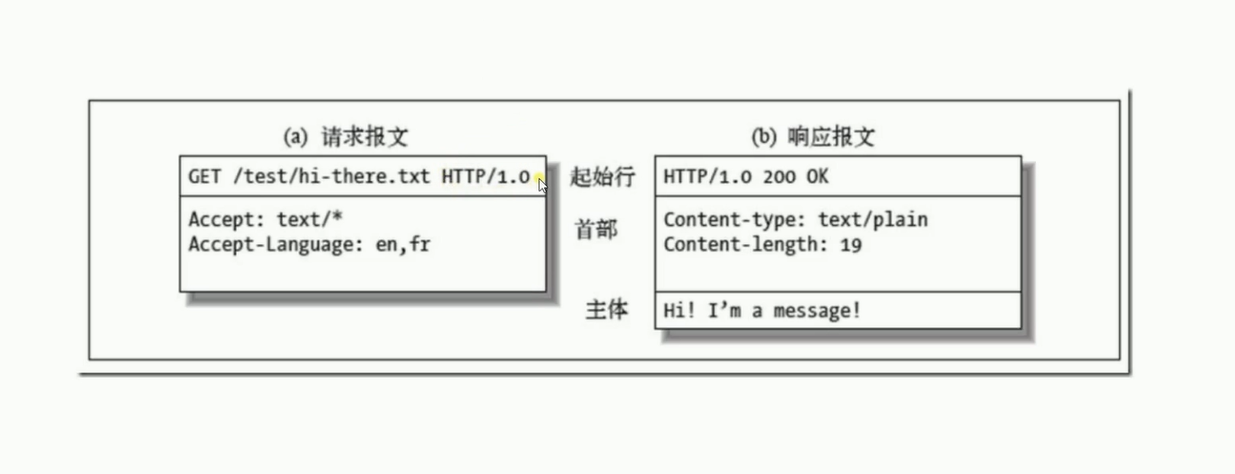
报文主要分为起始行、首部、主体。
- 起始行
在请求报文中,起始行包含了HTTP的Method、路由地址和HTTP协议版本,在响应报文中则是HTTP协议版本和Status Code。
- 首部
后续详细讲
- 主体
HTTP请求中返回的内容。
-
HTTP方法
-
用来定义对资源的操作
-
常用有GET、POST等
-
从定义上讲有各自的语义
-
-
HTTP CODE
-
定义服务器对请求的处理结果
-
各个区间的CODE有各自的语义,如100-199之间代表这个操作需要持续的进行,200-299之间代表操作是成功的,300-399之间代表重定向,400-499之间代表发送的请求有问题,500-599之间代表服务器出现了错误。
-
好的HTTP服务可以通过CODE判断结果
-
-
实现一个最简单的http服务(nodejs)
新建一个server.js
const http = require('http')
http.createServer(function (request, response) {
console.log('request come', request.url)
response.end('123')
}).listen('2333')
console.log('server listening on 2333')
然后在当前目录的命令行输入node server.js运行,打开localhost:2333查看。
HTTP各种特性总览
1.CORS跨域请求的限制与解决
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制。
所谓同源是指,域名,协议,端口均相同,不明白没关系,举个栗子:
http://www.123.com/index.html 调用 http://www.123.com/server.php (非跨域)
http://www.123.com/index.html 调用 http://www.456.com/server.php (主域名不同:123/456,跨域)
http://abc.123.com/index.html 调用 http://def.123.com/server.php (子域名不同:abc/def,跨域)
http://www.123.com:8080/index.html 调用 http://www.123.com:8081/server.php (端口不同:8080/8081,跨域)
http://www.123.com/index.html 调用 https://www.123.com/server.php (协议不同:http/https,跨域)
请注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域。
那么该如何解决跨域问题呢
- JSONP
使用方式
<script src="需要请求的地址">
</script>
但是要注意JSONP只支持GET请求,不支持POST请求。
- 添加请求头
还是用Node环境进行测试,在当前目录下有server.js,server2.js,index.html。
贴上server.js(请求方)的代码
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
const html = fs.readFileSync('index.html', 'utf8')
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(html)
}).listen('2333')
console.log('server listening on 2333')
server2.js(响应方)代码
const http = require('http')
http.createServer(function (request, response) {
console.log('request come', request.url)
response.writeHead(200, {
'Access-Control-Allow-Origin': '*'
})
response.end('123')
}).listen('2334')
console.log('server listening on 2334')
index.html的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
</body>
<script>
var xhr = new XMLHttpRequest()
xhr.open('GET', 'http://127.0.0.1:2334/')
xhr.send()
</script>
</html>
新建两个终端分别运行node server.js,node server2.js,打开localhost:2333,可以看到,我们当前从不同端口请求时,是属于跨域请求的,但是并没有跨域的报错,原因是因为我们在响应方里添加了请求头'Access-Control-Allow-Origin': '*',如果去掉了这个请求头的话,则会报错。
- 代理:
例如 www.123.com/index.html需要调用www.456.com/server.php,可以写一个接口www.123.com/server.php,由这个接口在后端去调用www.456.com/server.php并拿到返回值,然后再返回给index.html,这就是一个代理的模式。相当于绕过了浏览器端,自然就不存在跨域问题。
2. CORS跨域限制以及预请求验证
首先要说一下CORS跨域的限制,CORS允许的方法只有:
-
GET
-
HEAD
-
POST`
CORS允许的Content-Type只有:
-
text/plain
-
multipart/form-data
-
application/x-www-form-urlencoded`
其他限制:请求头限制、XMLHttpRequestUpload对象均没有注册任何事件监听器、请求中没有使用ReadableStream对象
假如我们使用fetch预请求,并需要带一个自定义的请求头如:X-Test-Cors,那么必须要在服务端中定义好Access-Control-Allow-Headers: X-Test-Cors,否则则会报错。
同理,如果我们需要使用其他自定义的方法的话,我们同样需要在服务端中定义Access-Control-Allow-Methods: Post, Put, Delete, xxxxxxx
3. Cache-Control
- 可缓存性
- public
代表http请求经过的任何地方(代理服务器等等)都可以进行缓存。
- private
代表只有发起请求的浏览器才可以进行缓存
- no-cache
任何节点都不可以进行缓存
- 到期
-
缓存到期时间:
max-age = <seconds>(秒) -
代理服务器使用:
s-maxage = <seconds>(秒) -
指示客户机可以接收超出max-age时间的响应消息,max-stale在请求设置中有效,在响应设置中无效:`max-stale =
- 重新验证
- must-revalidate
如果过期,则必须更新
- proxy-revalidate
和must-revalidate差不多,是给缓存服务器使用的。
- 其他
- no-store
no-cache从字面意义上很容易误解为不缓存,但是no-cache代表不缓存过期的资源,缓存会向服务器进行有效处理确认之后处理资源,更确切的说,no-cache应该是:do-not-serve-from-cache-without-revalidation
而no-store才是真正的不进行缓存。
使用no-cache的目的就是为了防止从缓存中获取过期的资源。
- no-transform
如果第三方网站不希望页面转码,可在页面中添加此协议,当用户进入时,会直接跳转至原网页。
具体实践:
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
if (request.url === '/') {
const html = fs.readFileSync('index.html', 'utf8')
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(html)
} else if (request.url === '/script.js') {
response.writeHead(200, {
'Content-Type': 'application/javascript',
'Cache-Control': 'max-age=200'
})
response.end('console.log("script loaded")')
}
}).listen('2333')
console.log('server listening on 2333')
加入了Cache-Control': 'max-age=200'之后,浏览器(客户端)即可对静态资源进行缓存,效果如下图所示。
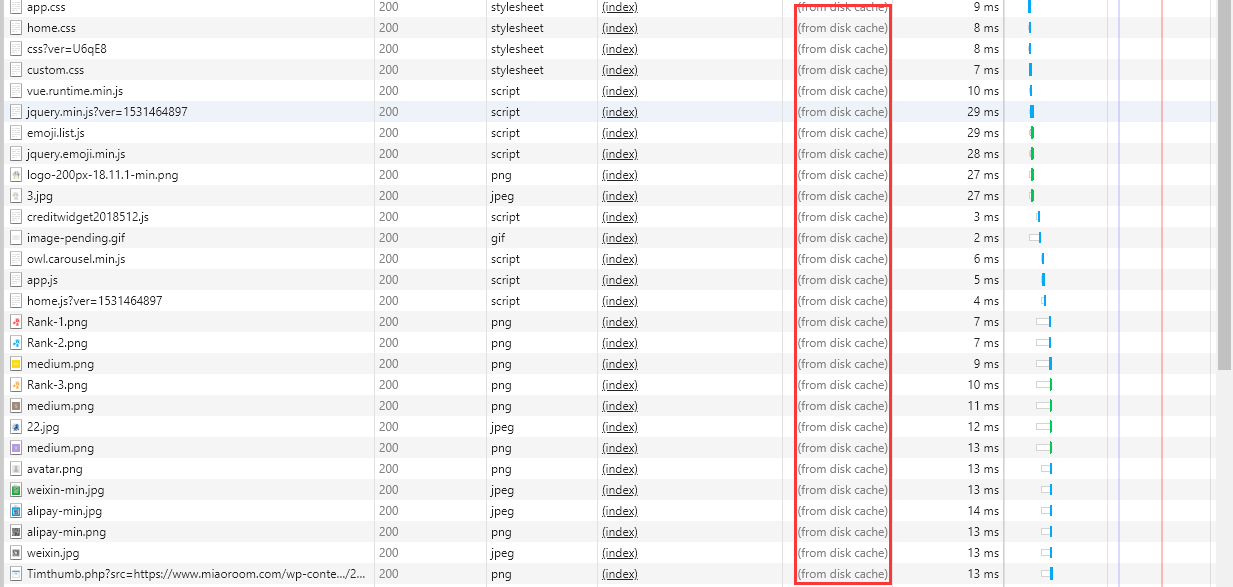
可以看到,通过缓存读取的资源,加载时间基本在几十ms内,这就是缓存带来的作用,合理运用缓存对加快网站二次打开速度的作用是巨大的。
4. 缓存验证Last-Modified和Etag
浏览器请求逻辑图?
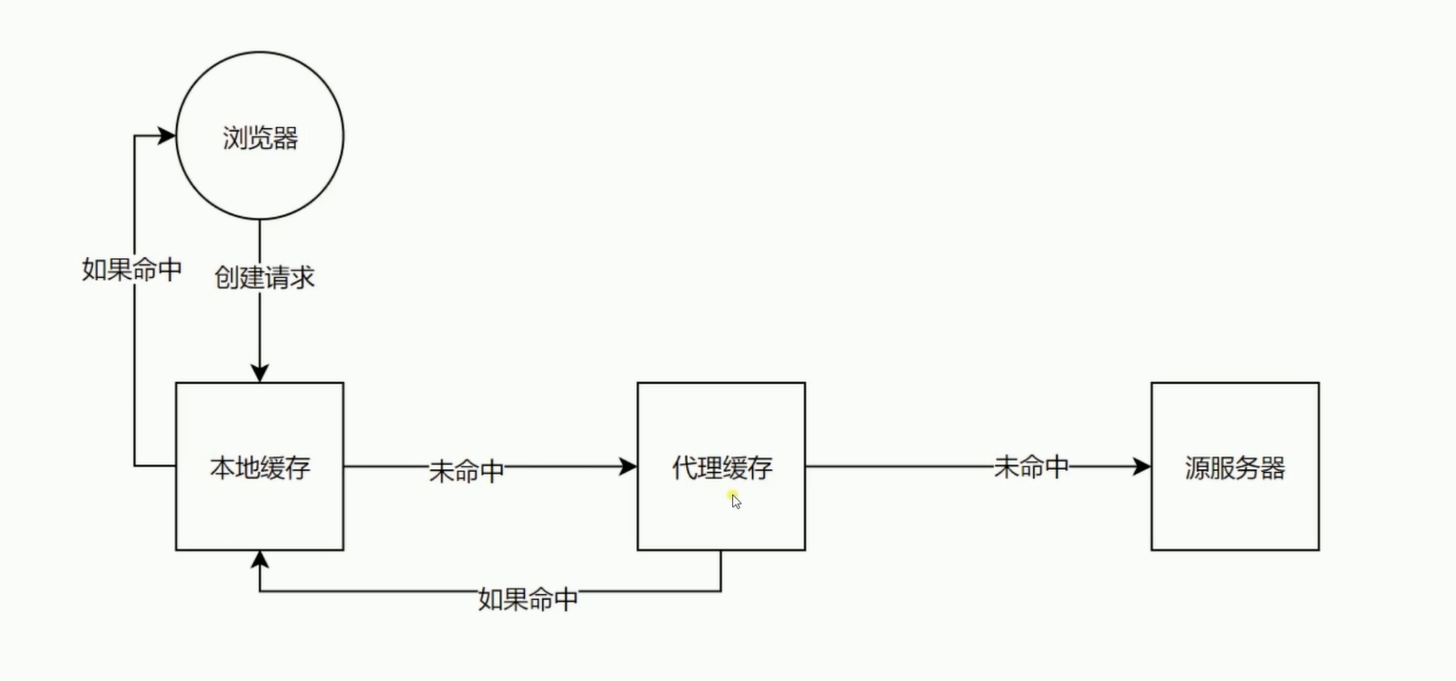
- Last-Modified
-
上次修改的时间
-
配合If-Modified-Since或者If-Unmodified-Since使用
-
对比上次修改时间以验证资源是否需要更新
- Etag
-
数据签名
-
配合If-Match或者If-Non-Match使用
-
对比资源的签名判断是否使用缓存
5. cookie和session
- Cookie
-
通过Set-Cookie设置
-
下次请求会自动带上
-
键值对,可以设置多个
- Cookie属性
-
max-age和expires设置过期时间
-
Secure只在https的时候发送
-
HttpOnly无法通过document.cookie访问
测试cookie返回的方式:
首先新建文件夹,然后新建server.js、index.html。
server.js的内容
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
if (request.url === '/') {
const html = fs.readFileSync('index.html', 'utf8')
response.writeHead(200, {
'Content-Type': 'text/html',
'Set-Cookie': 'id=123'
})
response.end(html)
}
}).listen('2333')
console.log('server listening on 2333')
index.html的内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<div>Content</div>
</body>
<script>
console.log(document.cookie);
</script>
</html>
我们通过在请求头中加入'Set-Cookie': 'id=123',来将Cookie写入到浏览器,随后我们在index.html中使用console.log(document.cookie);来打印当前的cookie。?
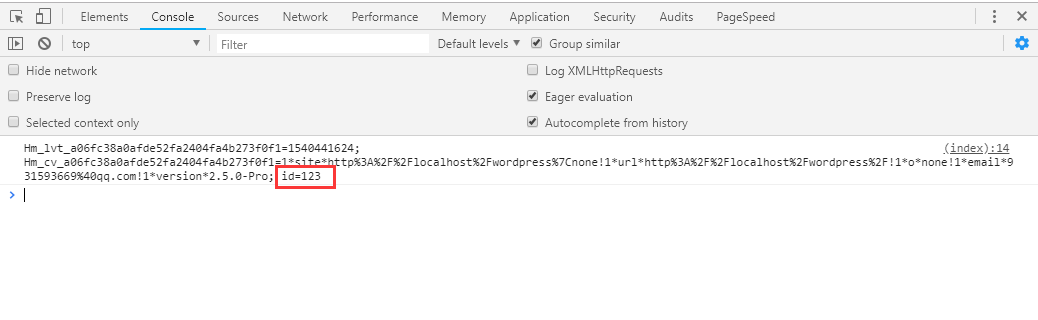
我们也可以在chrome开发者工具中的Application中可以查找到当前的cookie。?
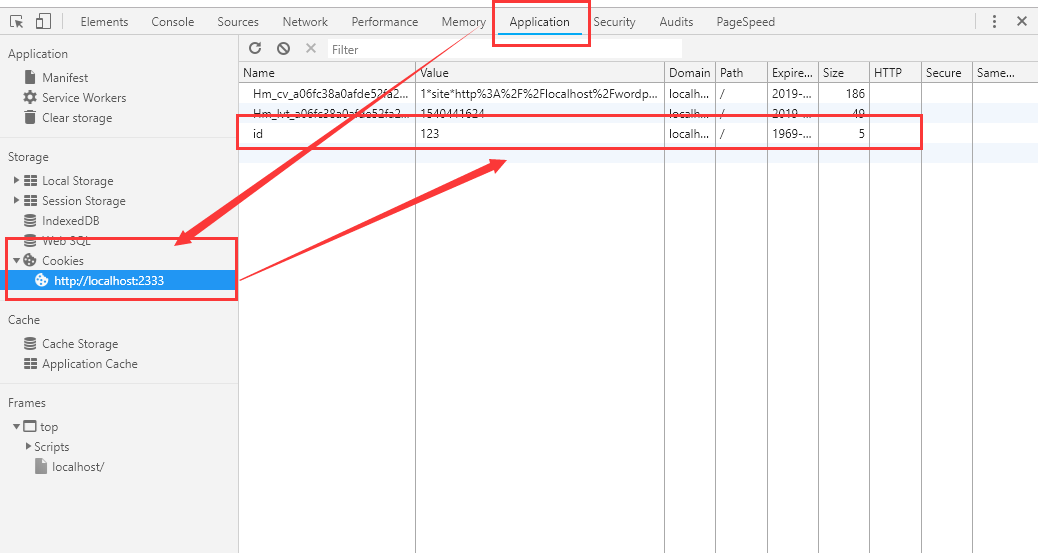
通过数组的形式可以一次性写入多个Cookie:'Set-Cookie': ['id=123','pwd=abc']
设置Cookie过期时间:'Set-Cookie': ['id=123; max-age=2','pwd=abc']
- Cookie !== Session,Cookie可以是Session的一种实现方式,但是Cookie和Session不是一一对应的,Session有许多别的实现。
6. HTTP长连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
那么,长连接的优劣是什么?
由上可以看出,长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可 以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
接下来在node环境中测试下chrome长连接的并发数限制
我们新建一个文件夹,里面新建三个文件,分别是:server.js、index.html、logo.png
server.js:
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
const html = fs.readFileSync('index.html', 'utf8')
const img = fs.readFileSync('./logo.png')
if (request.url === '/') {
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(html)
} else {
response.writeHead(200, {
'Content-Type': 'image/png'
})
response.end(img)
}
}).listen('2333')
console.log('server listening on 2333')
index.html的内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<img src="logo.png" alt="" srcset="">
<img src="logo2.png" alt="" srcset="">
<img src="logo3.png" alt="" srcset="">
<img src="logo4.png" alt="" srcset="">
<img src="logo5.png" alt="" srcset="">
<img src="logo6.png" alt="" srcset="">
<img src="logo7.png" alt="" srcset="">
</body>
<script>
</script>
</html>
一张百度的Logo
logo.png:
![]()
我们打开localhost:2333,打开chrome的network可以发现,由于并发数的限制,最后一张图片得等前面的6个连接执行完毕,才能加载,因此有了很长的waterfull时间。
数据协商
客户端请求时会声明希望拿到的数据格式和限制,服务端根据请求头返回不同的数据
1. Accept
- Accept
声明想要的数据类型,[主类型]/[子类型] ,如text/html,image/jpg
- Accept-Encoding
声明进行传输的编码方式,主要是数据压缩的算法,如gzip, deflate, br
- Accept-Lanuage
声明希望返回信息的语言,如zh-CN,zh;q=0.9(q表权重,0~1)
- User-Agent
声明浏览器和操作系统的相关信息
2. Content
- Content-Type
声明返回的数据格式,如’X-Content-Type-Options’:‘nosniff’,可阻止浏览器自行猜测返回数据类型而引发的安全问题。
不同的文件后缀对应不同的Content-Type,详见:HTTP Content-Type 对照表
- Content-Encoding
声明返回的编码方式,即数据压缩
- Content-Lanuage
声明返回的语言
这里先实践下在请求头中声明Content-Type和Content-Encoding。
先上代码,server.js:
const http = require('http')
const fs = require('fs')
const zlib = require('zlib')
http.createServer(function (request, response) {
console.log('request come', request.url)
const html = fs.readFileSync('index.html')
response.writeHead(200, {
'Content-Type': 'text/html',
'Content-Encoding': 'gzip' //声明以gzip的方式传输
})
response.end(zlib.gzipSync(html))
// response.end(html)
}).listen('2333')
console.log('server listening on 2333')
上述代码在请求头重声明了Content-Type和Content-Encoding,那么Content-Type我们肯定很好理解,他告诉了浏览器我们文本的格式是什么。
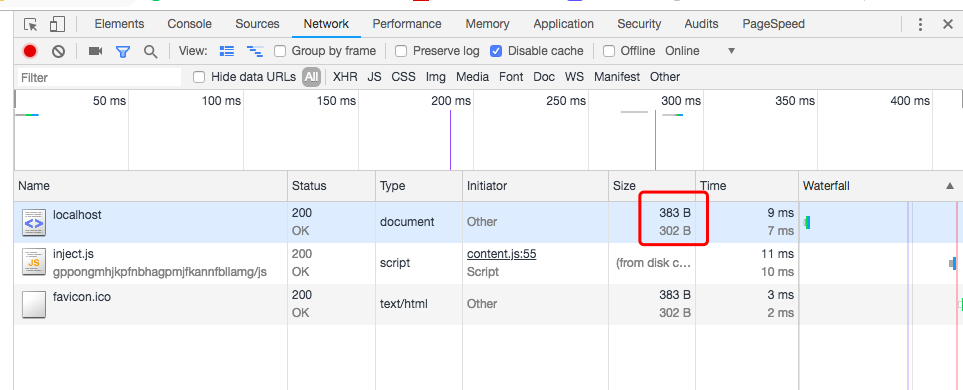
staticblob.jpg](https://i.loli.net/2018/11/26/5bfbee1971b4a.jpg)
接下来我们先看下在运行node server.js启动之后,Network的截图。红框中上面的数字是文件在传输过程中加上HTTP传输信息后的体积,下面的数字则是body中内容的体积。那么在Content-Type声明gzip压缩方式,开启gzip压缩后,传输时的体积会比body的体积更小,从而加快传输的速度。
redirect
重定向。
通过 url 访问某个路径请求资源时,发现资源不在 url 所指定的位置,这时服务器要告诉浏览器,新的资源地址,浏览器再重新请求新的 url,从而拿到资源。
若服务器指定了某个资源的地址,现在需要更换地址,不应该立刻废弃掉 url,如果废弃掉可能直接返回 404,这时应该告诉客户端新的资源地址。
node server.js启动,发现url路径自动带了/new。
//server.js
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
if (request.url === '/') {
response.writeHead(302, {
'Location': '/new'
})
response.end()
} else if (request.url === '/new') {
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(`<div>this is new Content</div>`)
}
}).listen('2333')
console.log('server listening on 2333')
可以看到根据定义的302临时重定向,页面自动的加载到了/new路由下的内容。
但如果我们需要永久重定向,把status code 改成301即可。
Redirect 301 和 302 的区别:
-
302 临时跳转,每次请求仍然需要经过服务端指定跳转地址
-
301 永久跳转
302的情况
每次访问 locahost:8888,都要经过服务端跳转,服务端通过 console.log 可以看到 / → /new 两次请求。
const http = require('http')
http.createServer(function (request, response) {
console.log('request come', request.url)
if (request.url === '/') {
response.writeHead(302, {
'Location': '/new'
})
response.end()
}
if (request.url === '/new') {
response.writeHead(200, {
'Content-Type': 'text/html',
})
response.end('<div>this is content</div>')
}
}).listen(8888)
console.log('server listening on 8888')
301 的情况
访问 locahost:8888,第一次经过服务端跳转,服务端通过 console.log 可以看到 / /new 两次请求;第二次 服务端 console.log 只显示 /new ,没有再次经过服务器指定新的 Location。
response.writeHead(301, {
'Location': '/new'
})
注意:使用 301 要慎重,一旦使用,服务端更改路由设置,用户如果不清理浏览器缓存,就会一直重定向。
设置了 301,locahost 会从缓存中读取,并且这个缓存会保留到浏览器,当我们访问 8888 都会进行跳转。此时,就算服务端改变设置也是没有用的,浏览器还是会从缓存中读取。
Content-Security-Policy
Content-Security-Policy 的作用:
-
使用白名单的方式告诉客户端(浏览器)允许加载和不允许加载的资源。
-
向服务器举报这种强贴牛皮鲜广告的行为,以便做出更加针对性的措施予以绝杀。
限制方式:
-
default-src 限制全局
-
指定资源类型
更详细的文档请移步MDN的:内容安全策略( CSP )
个人博客
更多编程、美术设计、实用素材、工具软件尽在我的个人博客喵容 - 和你一起描绘生活,欢迎光临喵容!:https://www.miaoroom.com















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}