







linux常用工具:

1.正则:正则表达式是记录文本规则的代码。 在线正则表达式测试

2.管道符“|”,用于连接两个命令间的输出与输入,管道符“|”左边的命令的输出会作为管道符“|”右边命令的输入。

echo "hello world" | grep hello

3.grep,sed,awk为三剑客,对文本进行处理。
1).grep 根据用户指定的模式(pattern)对目标文本进行过滤,显示被匹配到的行。
-v 显示不被pattern匹配的行---》grep -nv root test.txt:文件中不包含root的行数
-i 忽略字符大小写
-n 显示匹配的行号------》grep -n root test.txt:查找文件中包含root的行数

-c 统计匹配的行数
-r 递归搜索
-o 仅显示匹配到的字符串
-E 使用grep -E,相当于egrep,在使用正则匹配时用到此参数:grep -E "w{3}" test.sh
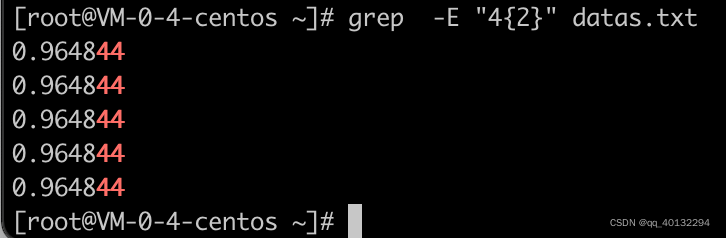
查找以R开始,以\结尾的行

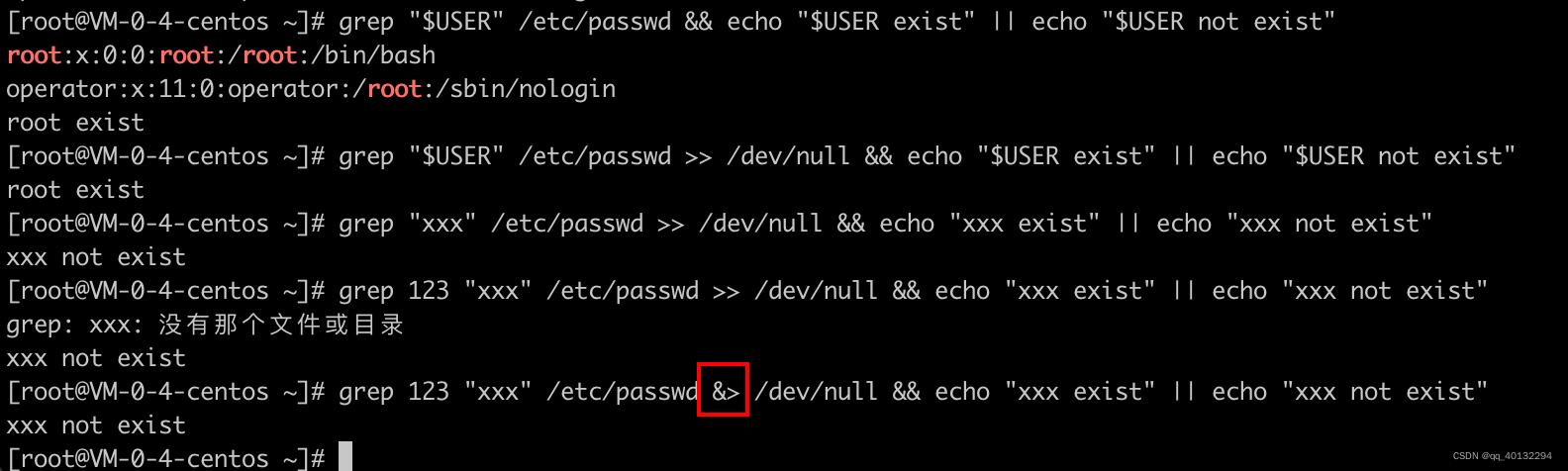
判断当前用户在文件中是否存在,存在就打印exist,不存在打印 not exist
 /dev/null :linux中的垃圾箱位置
/dev/null :linux中的垃圾箱位置
将未报错的输出扔进垃圾箱:>> /dev/null

不管报错与否都扔进垃圾箱:&> /dev/null
2).sed 流编辑器,对文件逐行处理
2种形式: sed opcf
1. sed [OPTION] “pattern command" file
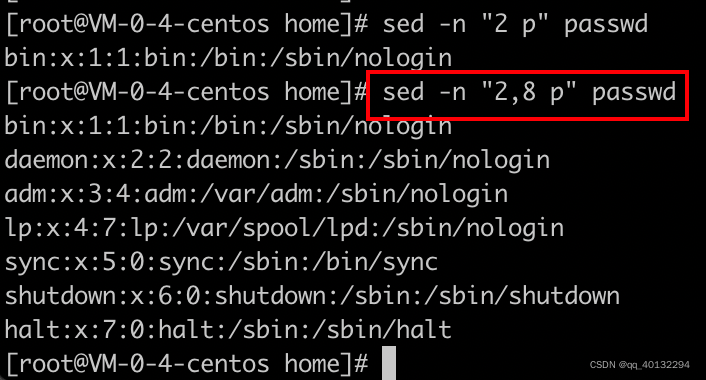
如: sed -n "2 p" passwd
OPTION:
-n 只打印模式匹配的行
-f 加载存放“动作”的文件
-r 支持拓展正则
-i 直接修改文件(真正修改生效的)
pattern:
5 只处理第5行
5,10 只处理第5行到第10行
/parttern/ 只处理能匹配pattern的行
/parttern1/,/pattern2/ 只处理能匹配pattern1行到pattern2行的行
command(增删改查):
新增
a 在匹配行后新增 sed -n '4a i love you' passwd
在第四行后面新增一行i love you;

i 在匹配行前新增 sed -n '4i I love you' passwd
在第四行前面插入一行I love you;
r 外部文件读入,行后新增
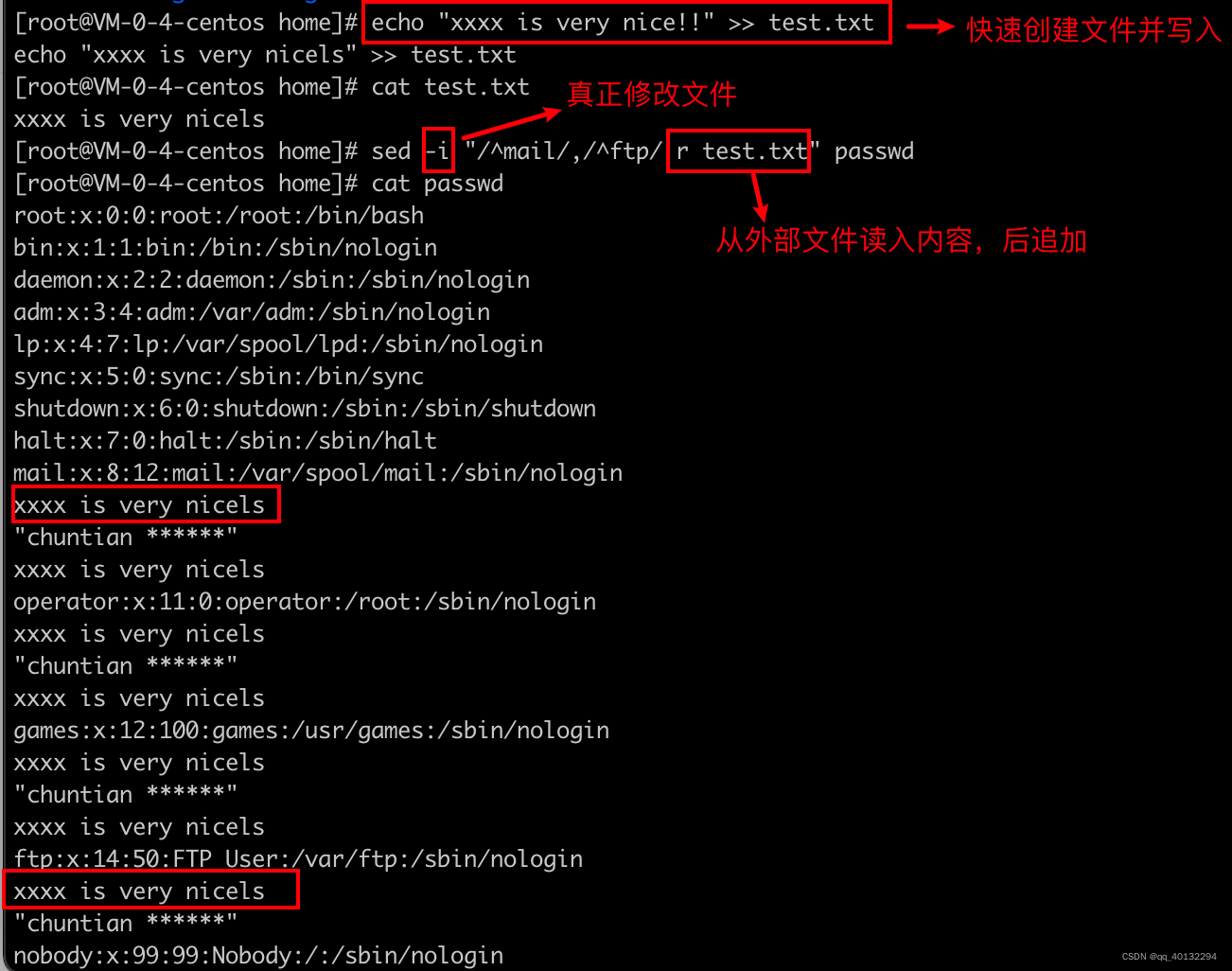
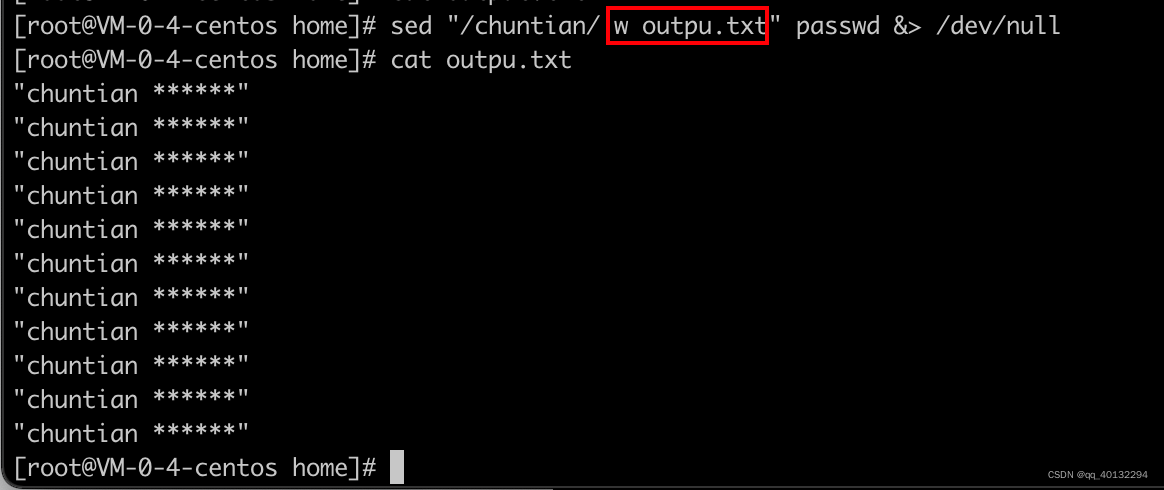
w 匹配行写入外部文件
删除
d sed -n '2,5d' passwd 将第2~5行删除;
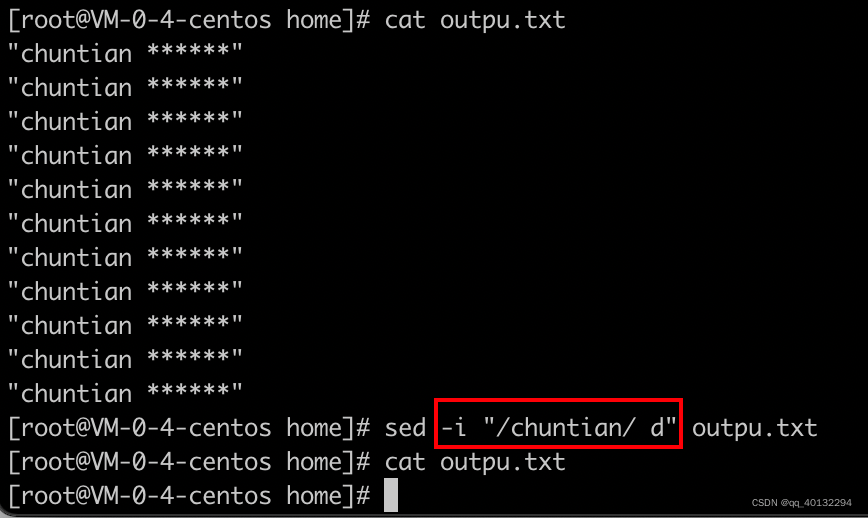
修改
c 整行替换 sed -n '2,5c i love you' 将第2至第5行的数据以i love you替换;
s 词替换 sed -n 's/old_word/new_word/g' passwd
将全局的old_word替换为new_word.
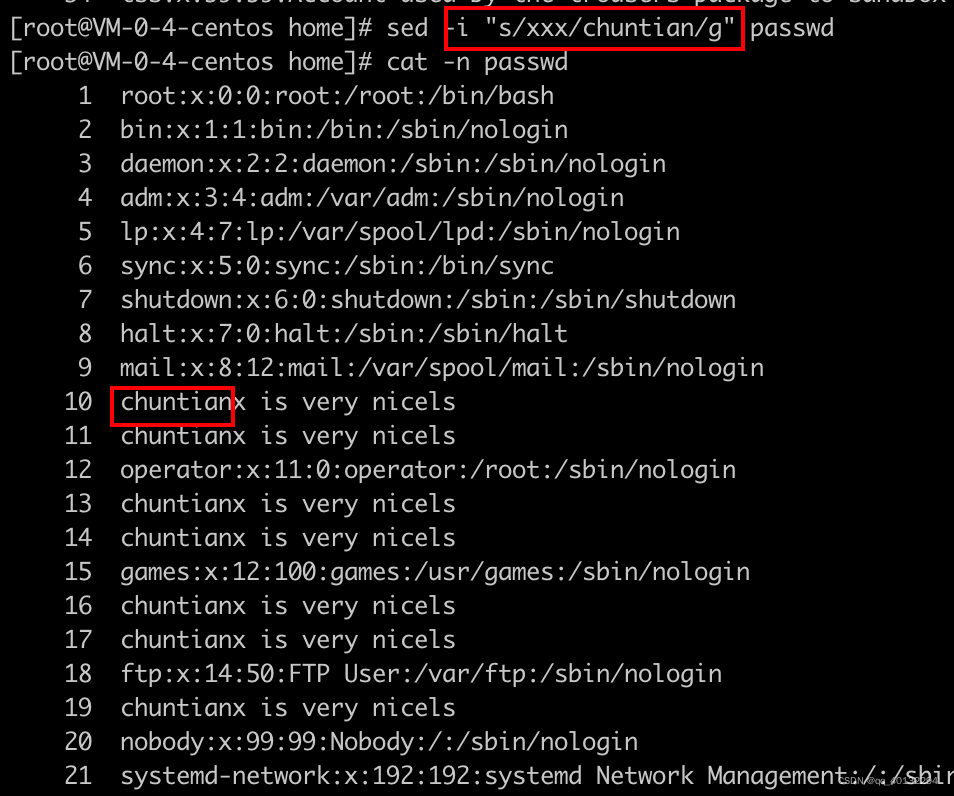
sed -n 's/old/new/' 只修改匹配行中第一个old为new
sed -n 's/old/new/ig. 忽略大小写全部替换
查询
p 打印 sed -n '/root/ p' passwd
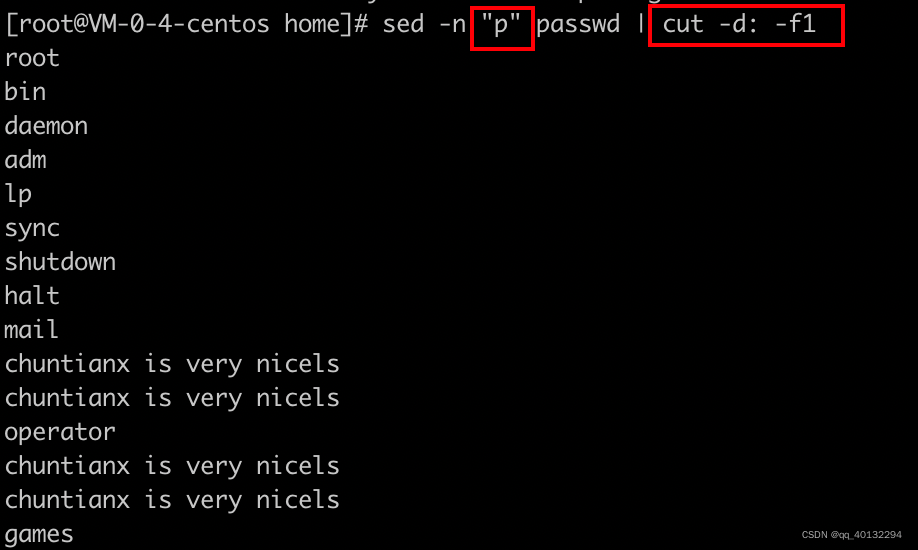
示例:
sed -n "2 p" passwd:对匹配的行做打印操作

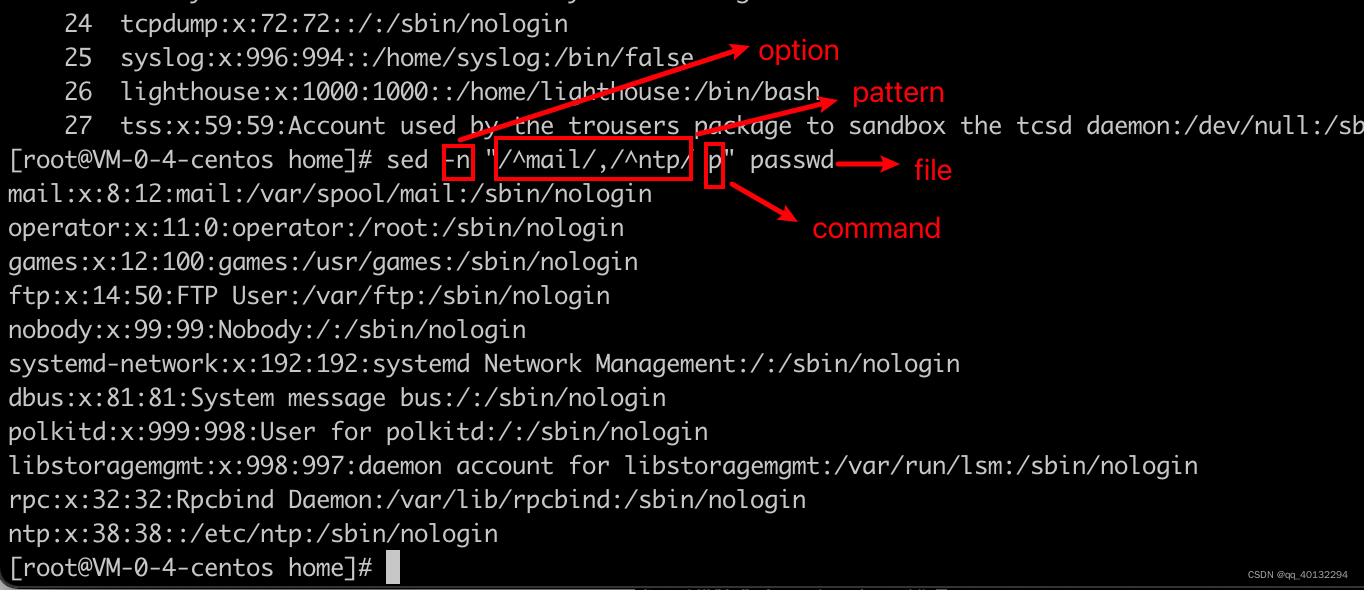
匹配含有daemon的行: sed -n "/daemon/ p" passwd ---->/xxxword/ 单词用//包裹
 匹配打印mail开头到ntp开头的行:sed -n "/^mail/,/^ntp/ p" passwd
匹配打印mail开头到ntp开头的行:sed -n "/^mail/,/^ntp/ p" passwd
2. some command | sed sed [OPTION] “pattern command" file
sed -h 帮助文档 向下翻:j
向上翻:k
下一个关键字:n
上一个关键字:N
sed -i 's/old_word/new_word/g' test.txt 以修改文件内容的形式将
文件内全局的old_word替换为new_word.


a:新增 sed -e '4a i love you' 在第四行后面新增一行i love you;
c.取代 sed -e '2,5c i love you' 将第2至第5行的数据以i love you替换;
d.删除 sed -e '2,5d' 将第2~5行删除;
i:插入修改 sed -e '4i I love you' 在第四行前面插入一行I love you;
p:打印 sed -n '/root/p'
s:取代 sed -e 's/old_word/new_word/g' 将全局的old_word替换为new_word.
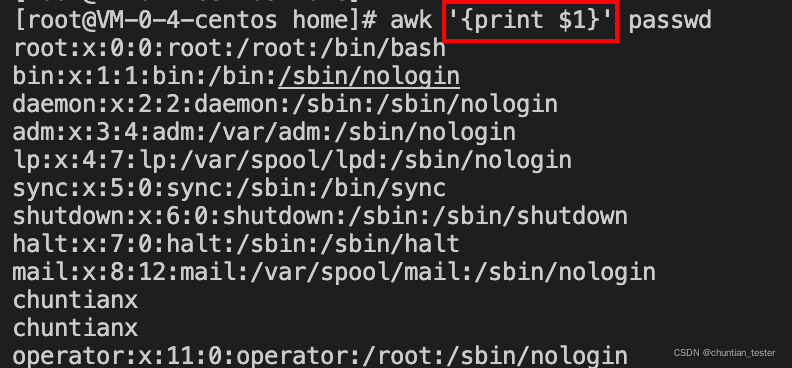
3).awk :文本处理工具,处理数据并生成结果报告,对列进行处理。
把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行后续处理

2种形式: awk opcf
awk 'BEGIN{} pattern{commands} END{}' file
包裹pattern的必须是单引号‘ ’
some command | grep [option] [pattern]
awk 'pattern {action}' test.txt
pattern 正则表达式
action 对匹配到的内容需要执行的命令(默认为输出每行内容)
test.txt awk浏览的文件名
BEGIN 处理文本前要执行的操作
END 处理文本后要执行的操作
内置变量:
$0 整行内容
$1~$n 当前行的第1~n个字段
NF(Number Field) 当前行字段数
NR(Number Row) 当前行行号,从1开始
FS(Field Separator) /-F 输入字段分割符,默认为空格/tab键
RS(Row Separator) 输入行分割符,默认为回车符
OFS(Output Field Separator). 输出字段分割符,默认为空格
ORS(Output Field Separator). 输出行分割符,默认为回车符
awk -F: '/root/ {print $7}' /etc/passwd
1.awk 按行处理/etc/passwd文件中的每行数据;
2.将读取出的每行数据按“:”分割成域;
3.将每行经分割后的所有数据匹配正则/root/,匹配包含root的行;
4.将匹配到的行执行print $7操作,即打印第7域(列),得出最后数据。

awk -F: 'NR==2{print $0}' /etc/passwd
1.awk 按行读取passwd文件中所有数据;
2.读取的数据按“:”分割为域;
3.匹配NR==2,第二行数据,并打印整行所有数据print $0.

awk -F: 'BEGIN{print "i love you"} {print $6,$7} END{print "do you love me?"}' /etc/passwd
BEGIN 处理文本前要执行的操作
END 处理文本后要执行的操作

根据pid查看某进程所占用内存%MEM百分比

awk 操作passwd文件:
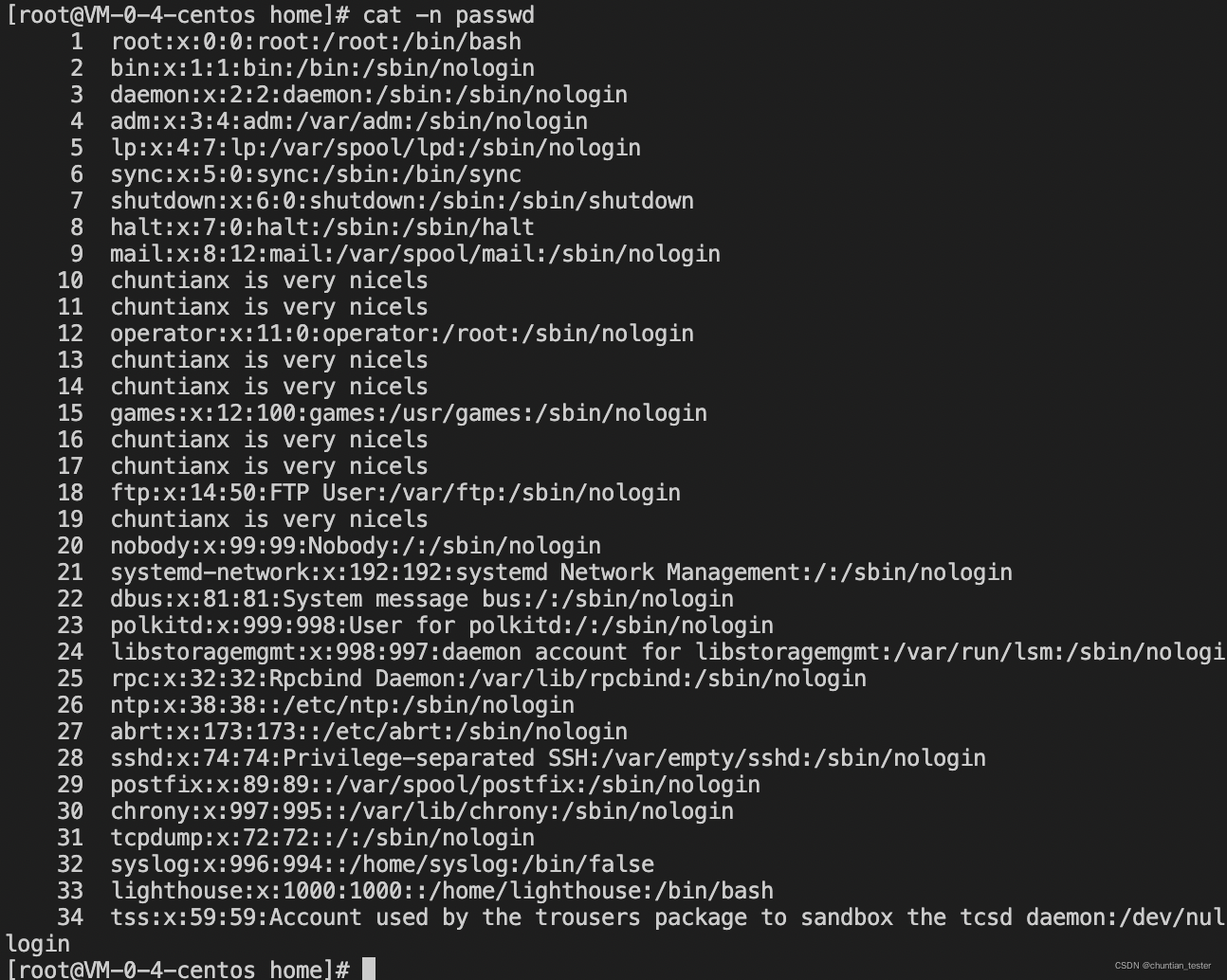
$0 整行内容
awk 查看文件内容 awk '{print $0}' passwd
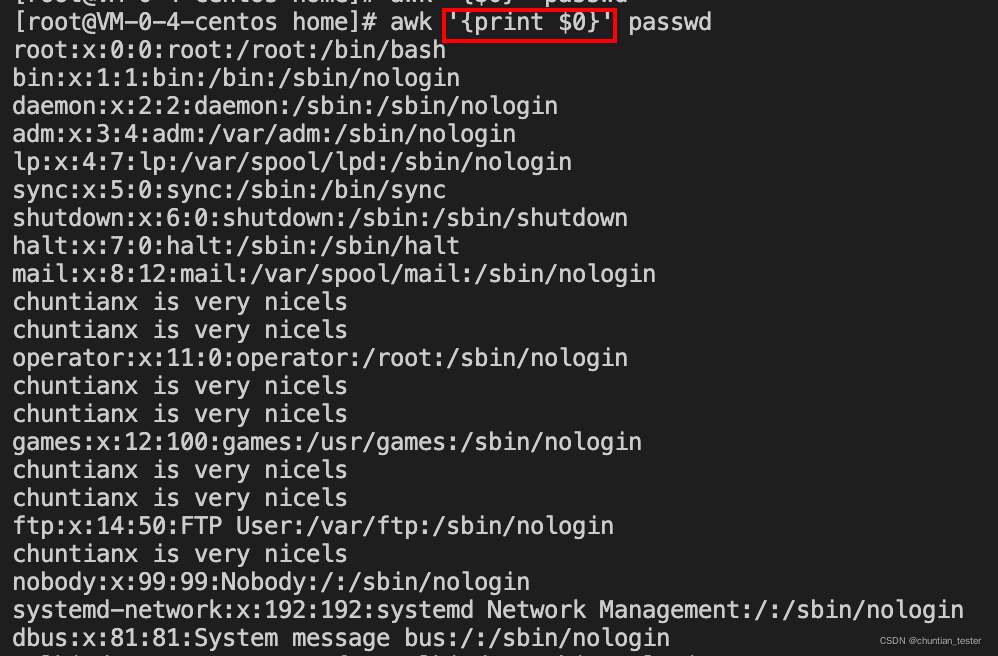
$1~$n 当前行的第1~n个字段
NF(Number Field) 当前行字段数
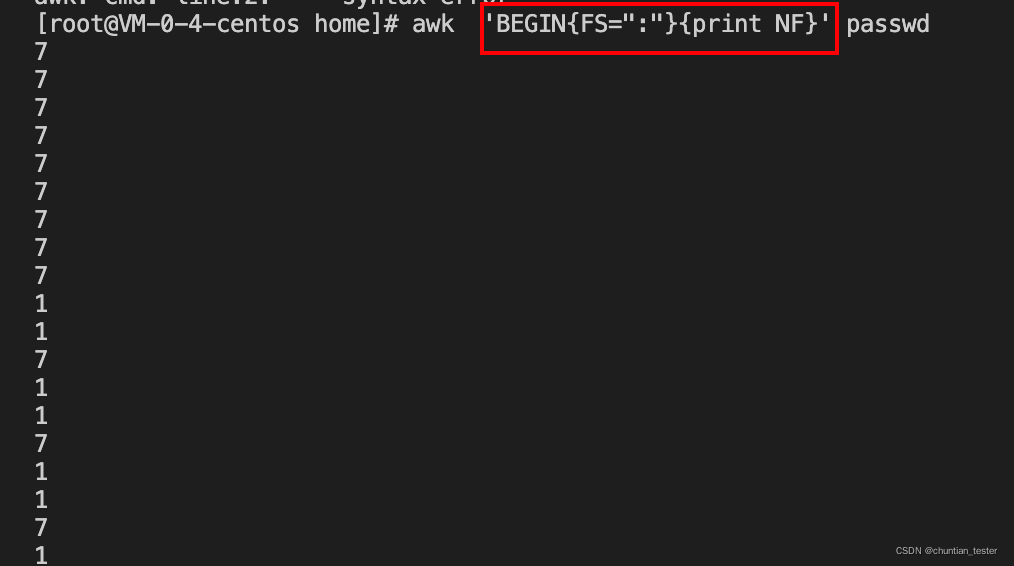
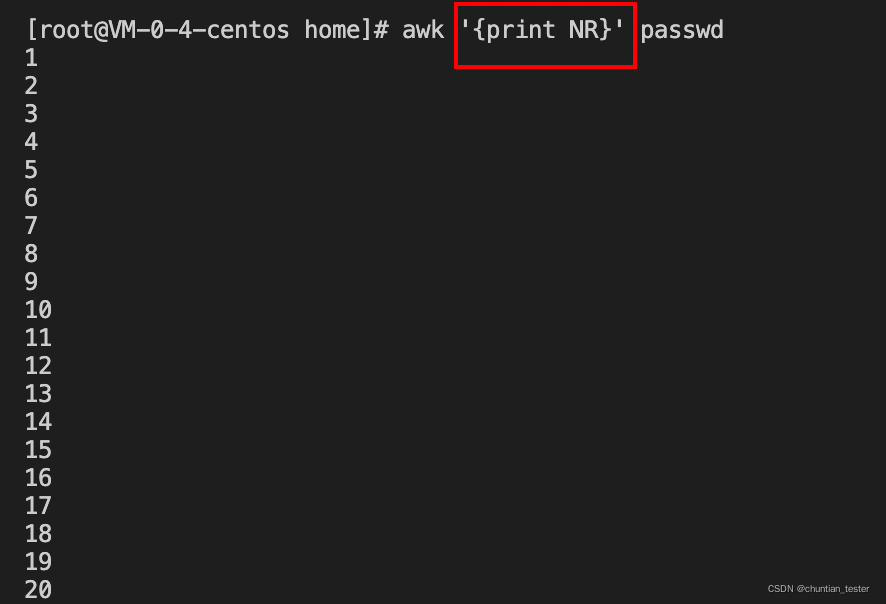
NR(Number Row) 当前行行号,从1开始
FS(Field Separator) 输入字段分割符,默认为空格/tab键

利用NF取出最后一列数据

打印第1个字段和最后一个字段
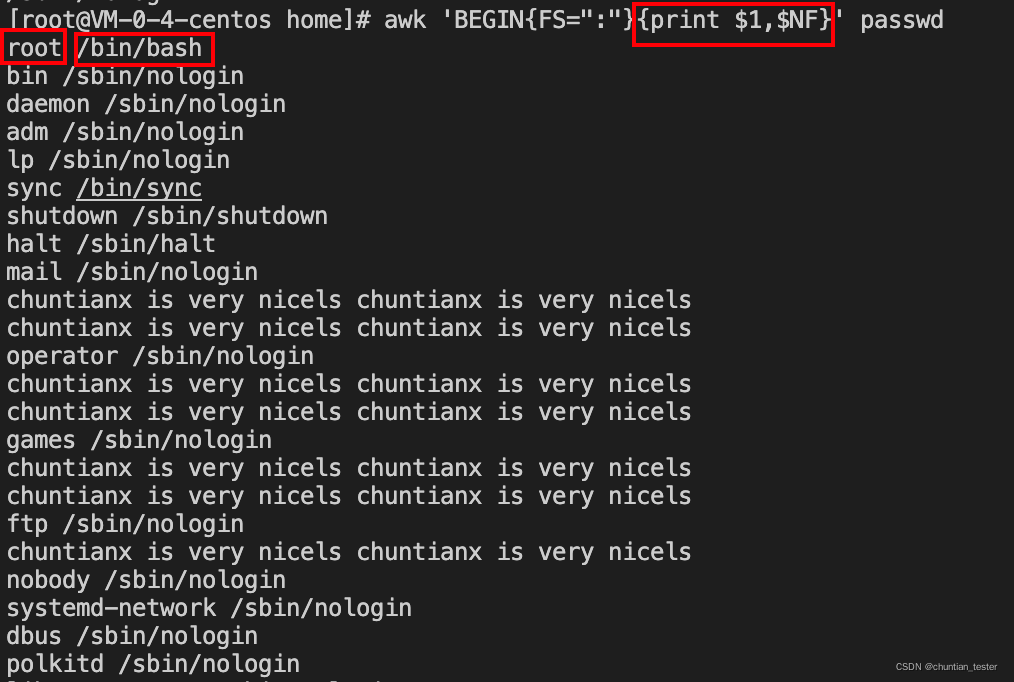
RS(Row Separator) 输入行分割符,默认为回车符
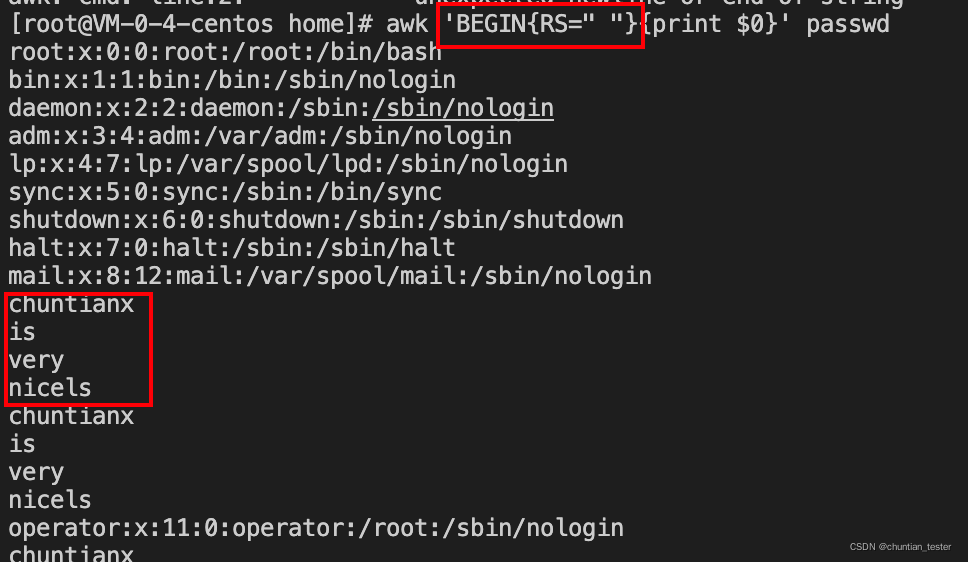
OFS(Output Field Separator). 输出字段分割符,默认为空格
ORS(Output Field Separator). 输出行分割符,默认为回车符
格式化输出:printf 会将空格和回车键都去除
格式符: 含义
%s 字符串
%d 十进制数字
%f 浮点数
修饰符 含义
+ 右对齐
- 左对齐

格式化:\n换行
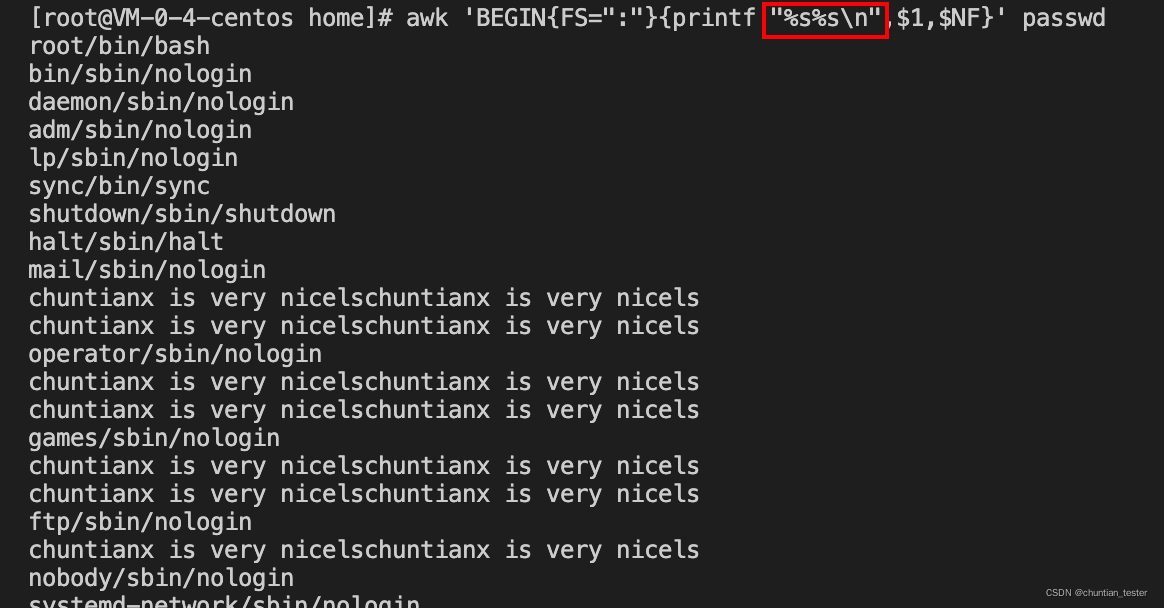
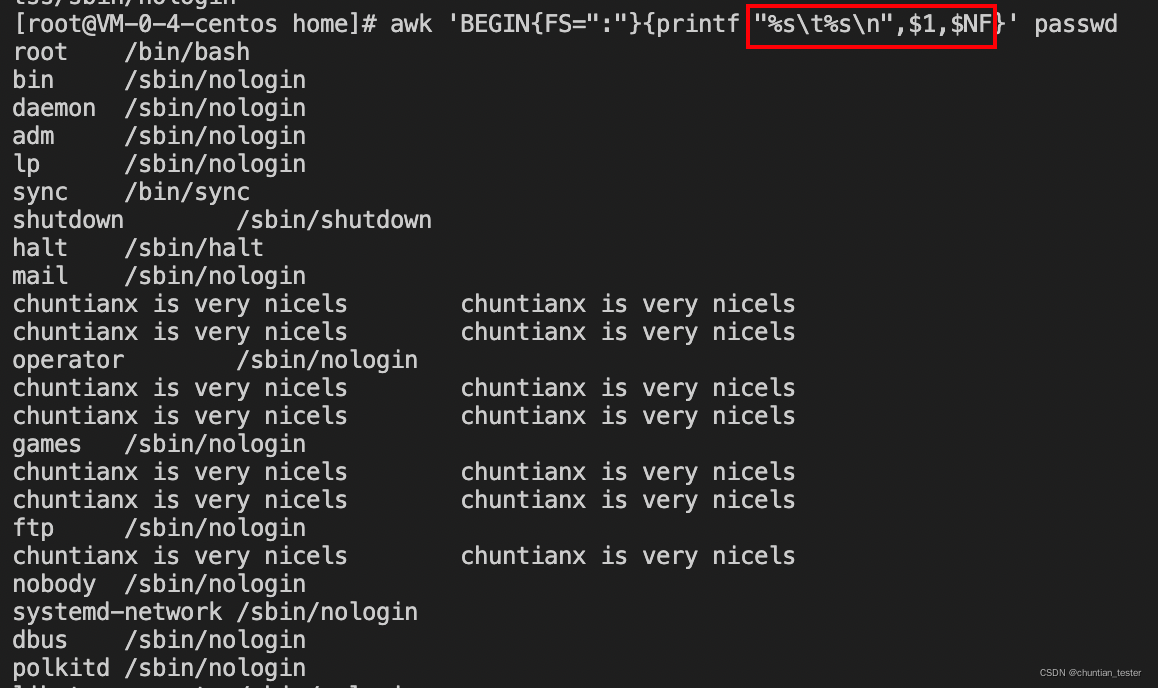
/t 指标符
%40s 占40个字符,默认右对齐,未占用的用空格代替
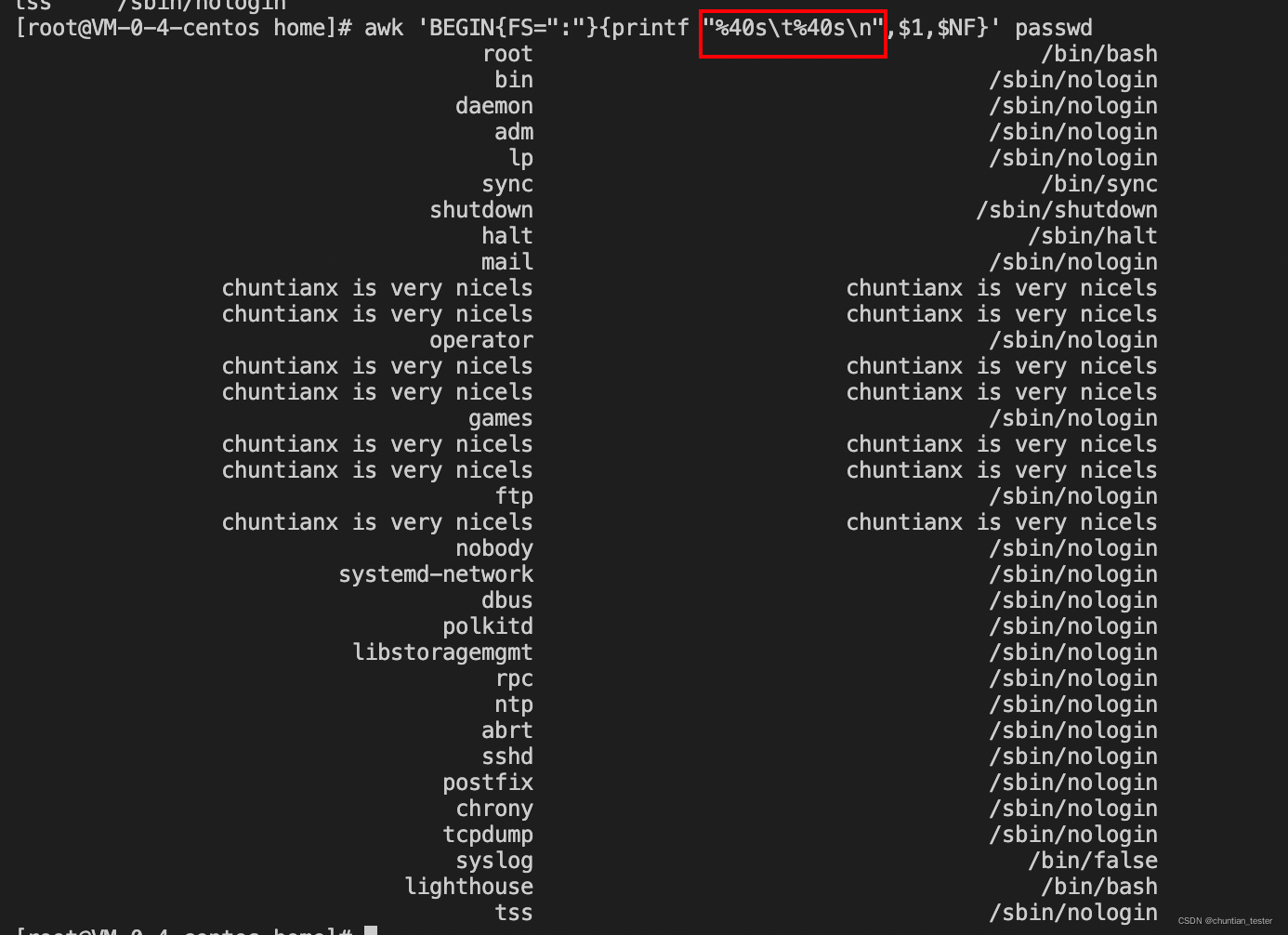
左对齐
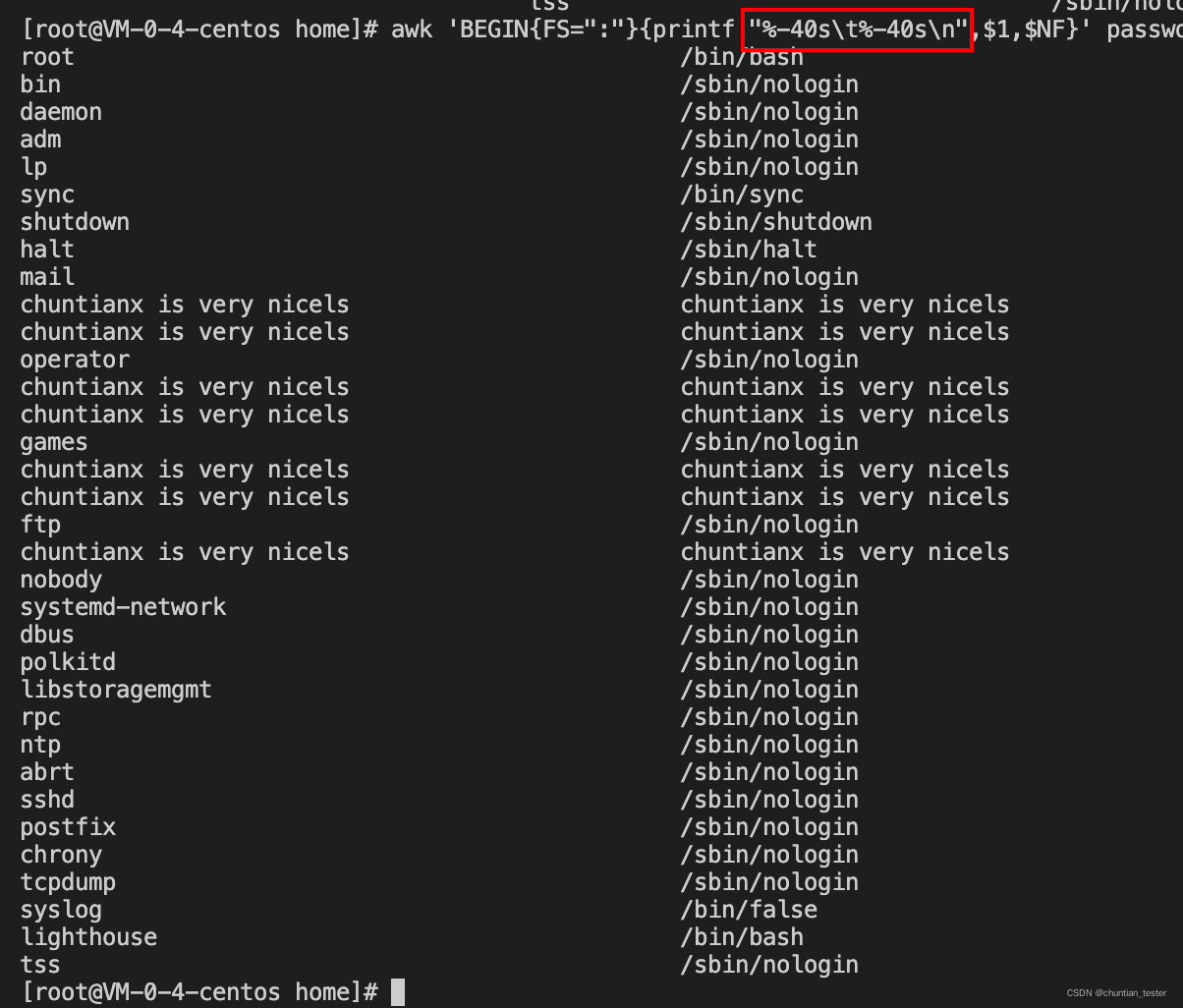
打印包含“chuntian"的行的第1列和最后1列数据
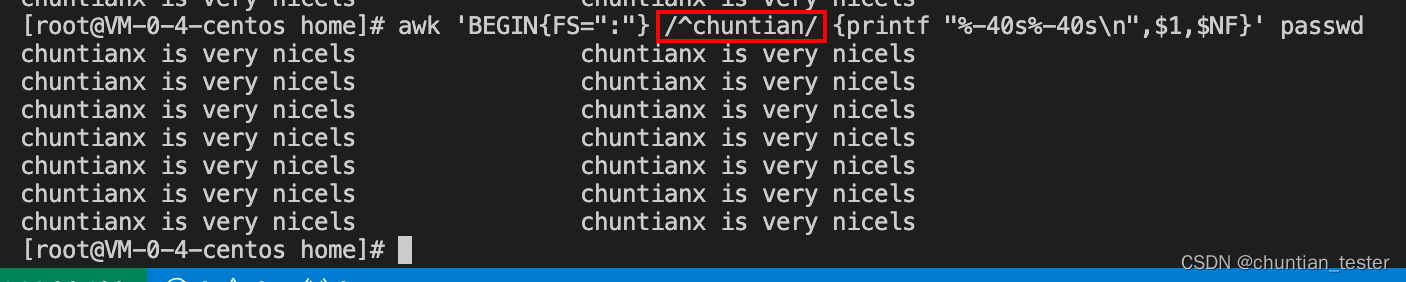
打印mail 到 games的行

需求:取出第6列中含bin的行

使用正则匹配包含/bin的行
 使用正则匹配第6列包含/bin的行
使用正则匹配第6列包含/bin的行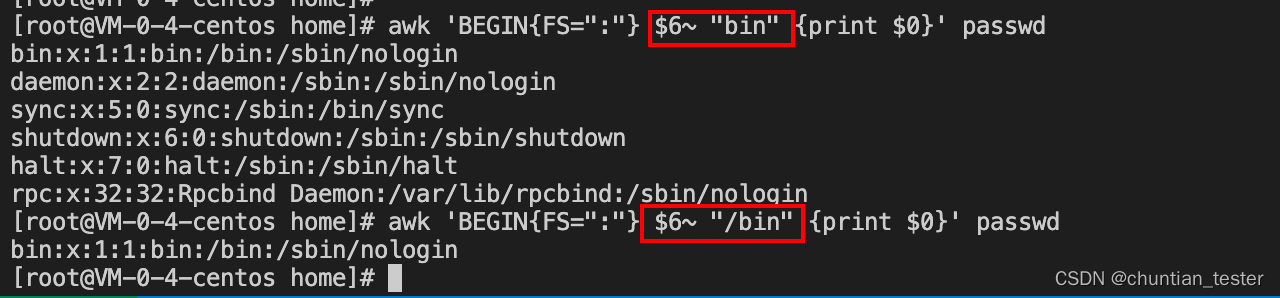
匹配行后打印总共有几行

AWK 语法:
将awk命令写入文件,通过文件载入命令
vim test.awk. 建议按照此格式写,不然可能报错。
BEGIN{
FS=":"
printf "%-20s\t%-20s\n","User","Status"
}
{
if ($6 ~ "bin")
{
count++
printf "%-20s\t%-20s\n",$1,$NF
}
}
END{
printf "%-20s\t%-20s\n","Total:",count
}效果:
通过awk -f 参数加载命令文件。

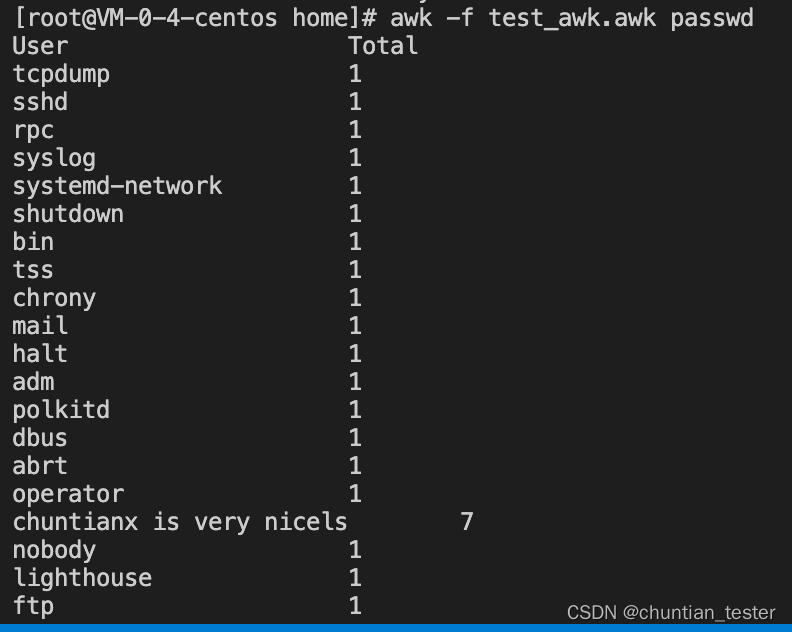
awk 语法2:
统计每个用户的 数量
BEGIN{
FS=":"
printf "%-20s\t%-20s\n","User","Total"
}
{
USER[$1] += 1
}
END{
for (u in USER)
printf "%-20s\t%-20s\n",u,USER[u]
}
效果:
统计日志中每位用户成功数和失败数
BEGIN{
FS=":"
printf "%-20s\t%-20s\t%-20s\n","User","Success","Fail"
}
{
if ($5 == "pass")
{
SUCCESS[$4] += 1
} else
{
FAIL[$4] += 1
}
USER[$1] += 1
}
END{
for (u in USER)
{
ALL_SUCCESS += SUCCESS[u]
ALL_FAIL += FAIL[u]
printf "%-20s\t%-20s\t%-20s\n",u,SUCCESS[u],FAIL[u]
}
printf "%-20s\t%-20s\t%-20s\n","Total",ALL_SUCCESS],ALL_FAIL
}
效果:


















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











