







模型序列化器:
有时候我们根据模型类的字段一个个去定义序列化器类中的字段,可能模型类有百个字段,这样一个个定义就显得非常繁琐,所以我们可以使用drf中自带的模型序列化器,即serializers.ModelSerializer:
1.serializers.ModelSerializer为我们根据模型类自动生成序列化器类
2.serializers.ModelSerializer为我们自动提供了create()方法和update()方法.
1.定义模型序列化器
# projects/serializers.py
class PorjectModelSerializer(serializers.ModelSerializer):
"""
1。模型序列化器,不继承serializers.Serializer,继承serializers.ModelSerializer,
2。必须定义内部类Meta
Meta内部指定model属性,表示需要模型序列化器需要序列化的具体模型类
fields:指定需要序列化的模型类中的具体字段
fields="__all__":代表模型中的所有字段都序列化对应生成
fields=(字段1,字段2,字段3,):自定义需要指定的字段生成
exclude:指定模型类中不需要序列化的字段
exclude=(字段1,字段2,字段3,):这些字段不需要自动生成
"""
class Meta:
model = Projects
fields = "__all__"2.指定模型序列化器需要操作的模型类
# projects/models.py
class Projects(BaseModel):
"""
max_length:必传参数
verbose_name:在渲染表单的时候,下面会有一个中文的描述信息:项目名称;
在后台管理站点也会把当前字段加上一个描述
help_text:在api接口文档中会作为中文描述信息
unique=True: 代表给一个字段设置唯一约束,默认为False
default:指定默认值
TextField():支持长文本
blank=True:允许传空字符串,DRF进行反序列化输入时才有效
null = Tru:允许为null,DRF进行反序列化输入时才有效
DateTimeField指定auto_now_add=True,在创建一条记录时会自动创建时间作为该字段的值,后续更新不会改变该值
DateTimeField指定auto_now=True,在更新一条记录时,会自动将更新记录的时间作为该字段的值
"""
full_name = models.CharField(max_length=50,
verbose_name='项目名称',
help_text='项目名称',
unique=False)
leader = models.CharField(max_length=10,
verbose_name='项目负责人',
help_text='项目负责人')
# default=xxx指定默认值
is_execute = models.BooleanField(verbose_name='是否启动项目',
help_text='是否启动项目',
default=False)
# TextField()支持长文本
# blank=True,允许传空字符串
# null = True,允许为null
desc = models.TextField(verbose_name='项目描述信息',
help_text='项目描述信息',
blank=True, default='')
# 修改模型类元信息
class Meta:
# # 是否被管理
# managed = True
# db_table:指定表名
db_table = 'tb_projects'
def __str__(self):
# print打印对象时可以默认返回的东西
return f'Projects({self.full_name})'3.terminal中执行命令
3.1 python manage.py shell
3.2 from projects.serializers import PorjectModelSerializer
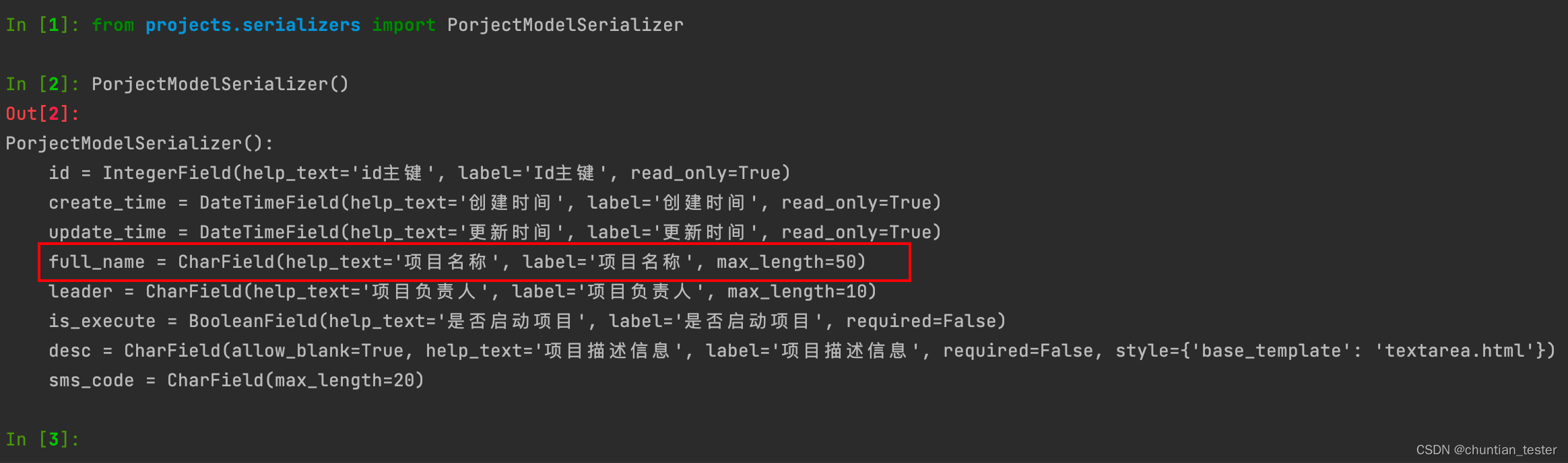
3.3 PorjectModelSerializer()
4.效果:

5.定义模型序列化器类总结:
5.1 继承serializers.ModelSerializer类或其子类
5.2 需要在Meta内部类中指定model,fields类属性参数
5.2.1 model指定模型类(需要生成序列化器的模型类)
5.2.2 fields指定模型类中哪些字段需要被生成序列化器字段
5.3 会给id主键,有指定auto_now_add或者auto_now参数的DateTimeField字段,自动添加
read_only=True
5.4 有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验
(UniqueValidator)
5.5 有设置default=True的模型字段,会自动添加required=False
5.6 有设置null=True的模型字段,会自动添加allow_null=True
5.7 有设置blank=True的模型字段,会自动添加allow_blank=True
6.字段修改
有时候,我们通过模型序列化器生成的序列化器中的字段并不能完全满足我们对序列化与反序列化操作的要求,我们可以自己修改不满足要求的字段.
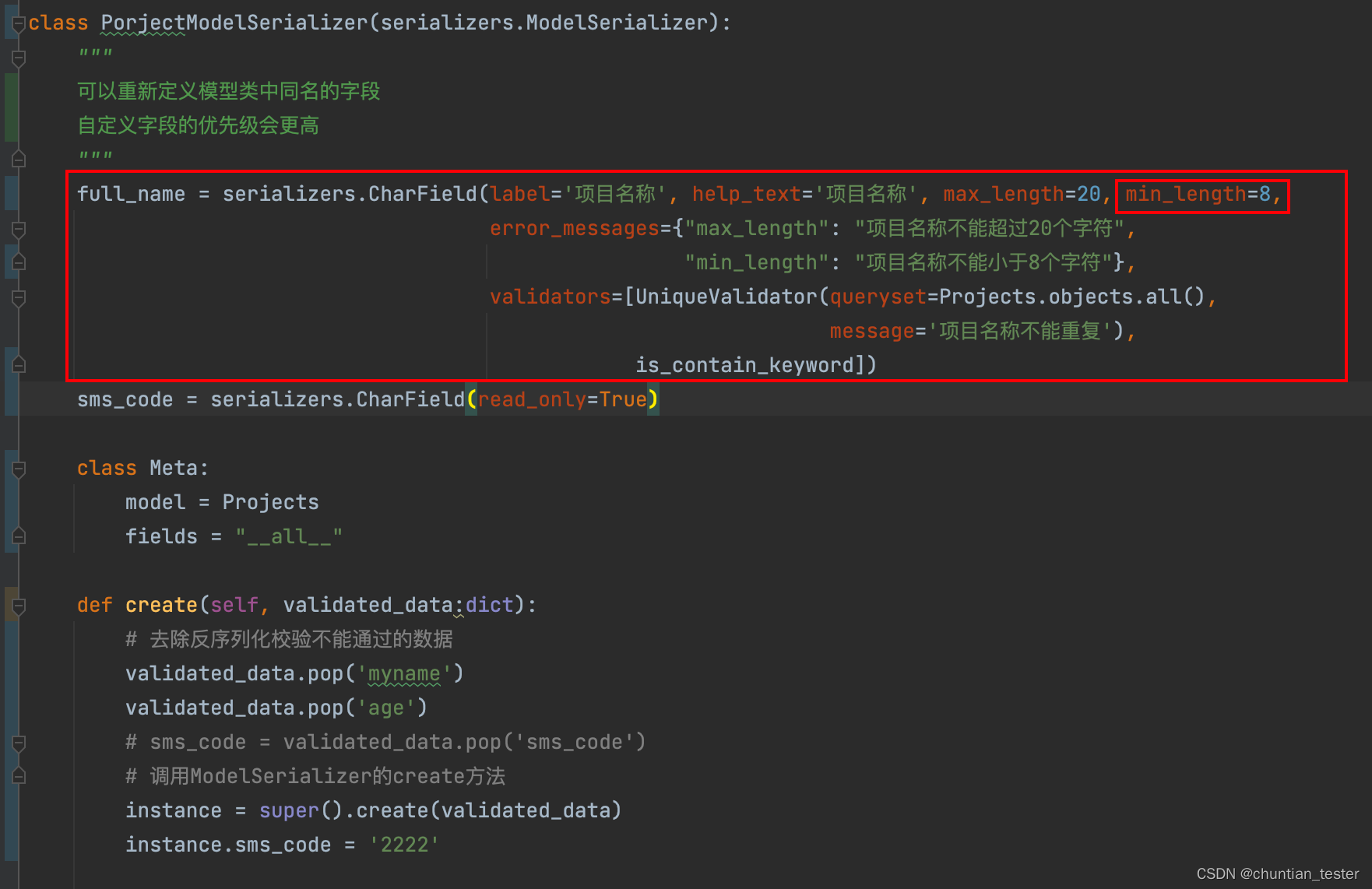
6.1 方式一:
6.1.1 可以重新定义模型类中同名的字段
6.1.2 自定义字段的优先级会更高
例如:给序列化器自动生成的full_name字段增加min_length=8
输出

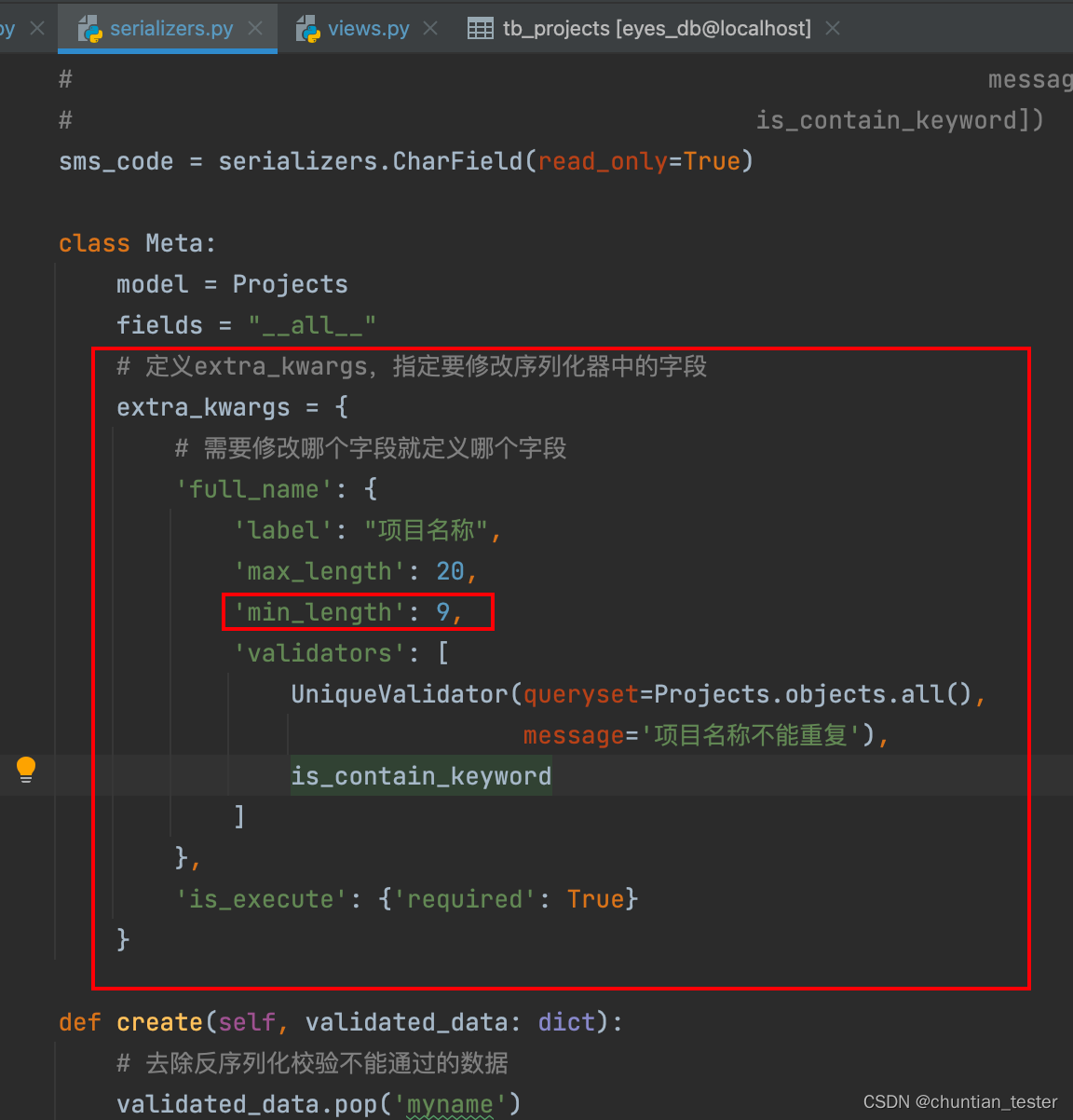
6.2 方式二:
如果生成的序列化器中只有少量字段不满足需求,可以在Meta内部类中定义extra_kwargs字典进行微调,将需要调整的字段作为key,需要修改的内容作为value
6.2.1 在Meta内部类中定义extra_kwargs属性(字典)
输出
6.3 代码
class PorjectModelSerializer(serializers.ModelSerializer):
"""
可以重新定义模型类中同名的字段
自定义字段的优先级会更高
"""
# full_name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=8,
# error_messages={"max_length": "项目名称不能超过20个字符",
# "min_length": "项目名称不能小于8个字符"},
# validators=[UniqueValidator(queryset=Projects.objects.all(),
# message='项目名称不能重复'),
# is_contain_keyword])
sms_code = serializers.CharField(read_only=True)
class Meta:
model = Projects
fields = "__all__"
# 定义extra_kwargs,指定要修改序列化器中的字段
extra_kwargs = {
# 需要修改哪个字段就定义哪个字段
'full_name': {
'label': "项目名称",
'max_length': 20,
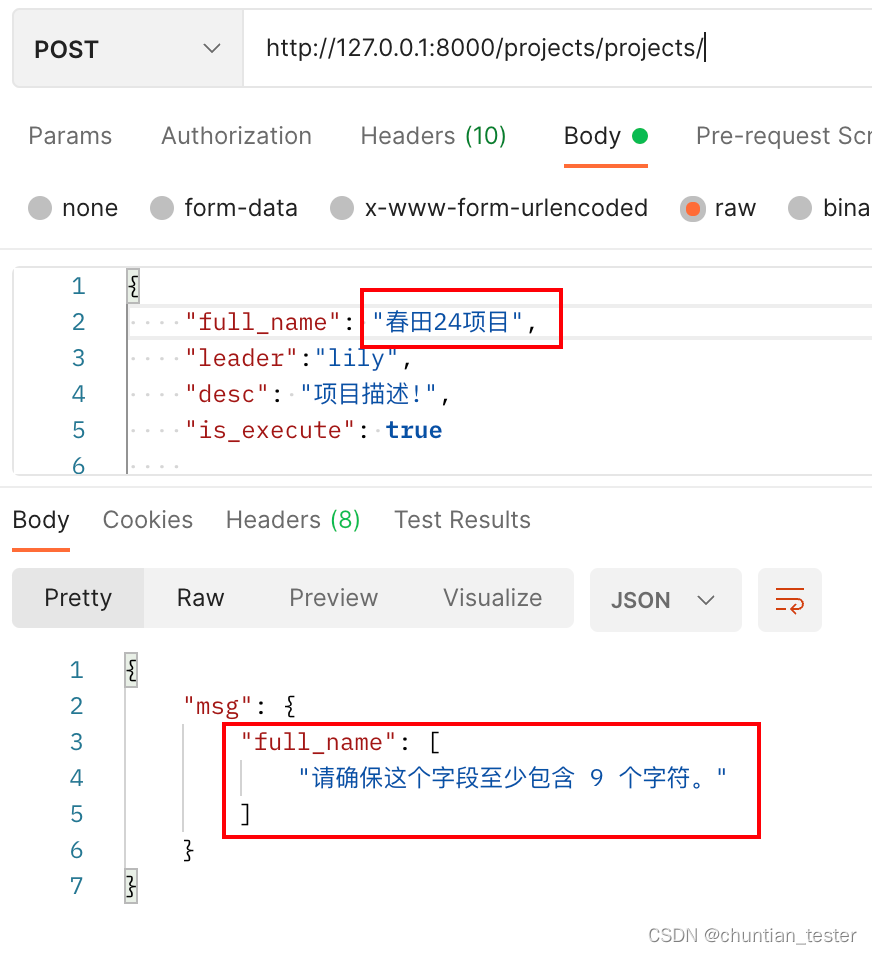
'min_length': 9,
'validators': [
UniqueValidator(queryset=Projects.objects.all(),
message='项目名称不能重复'),
is_contain_keyword
]
},
'is_execute': {'required': True}
}
def create(self, validated_data: dict):
# 去除反序列化校验不能通过的数据
validated_data.pop('myname')
validated_data.pop('age')
# sms_code = validated_data.pop('sms_code')
# 调用ModelSerializer的create方法
instance = super().create(validated_data)
instance.sms_code = '2222'
return instance
def update(self, instance, validated_data):
instance = super().create(validated_data)
return instance
















 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











