






采用哈希map存储数值和索引,在遍历过程中一种情况是找到target-num[i],这个时候直接返回两个索引;另一种情况是没找到target-num[i],这个时候存储当前Num和索引到map
func twoSum(nums []int, target int) []int {
hashMap := map[int]int{}
for i:=0;i<len(nums);i++{
if index,ok:= hashMap[target-nums[i]];ok{
return []int{index,i}
}else {
hashMap[nums[i]] = i
}
}
return nil
}创建dummy链表指针,cur=dummy从而不断移动cur,返回dummy.Next
创建sum变量存储一次相加的和
当l1 l2 != null的时候如果l1不等于null 加和到sum
l2 类似
cur.Next存储sum 取模的值
sum 除等产生进位
处理特殊情况,sum 出循环后等于1的情况
type ListNode struct {
Next *ListNode
Val int
}
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
dummy:= &ListNode{Val: 0}
cur := dummy
p1,p2 := l1,l2
sum := 0
for p1 != nil || p2 != nil{
if p1 != nil{
sum += p1.Val
p1 = p1.Next
}
if p2 != nil{
sum += p2.Val
p2 = p2.Next
}
cur.Next = &ListNode{Val: sum%10,Next: nil}
sum /= 10
cur = cur.Next
}
if sum == 1{
cur.Next = &ListNode{Val: 1}
}
return dummy.Next
}遍历,在map中看当前到标志位是否重复,如果重复了max(ans,标志位置-当前位置);如果没重复,标志位++直到结束。从当前位置向后遍历,当在map中不存在时,标记为存在
索引++第二层for循环退出表示索引刚好到重复字符出现的位置,此时ans = max(ans,index-i)求最大值。外层第i次循环污染了map的i到j. 因此一个循环清空map的i到j以便后续使用
func max(x,y int)int{
if x>y{return x}
return y
}
func lengthOfLongestSubstring(s string)int{
ans := 0
index := 0
m := map[byte]bool{}
for i:=0;i<len(s);i++{
for index = i;index<len(s)&&m[s[index]] != true;{
m[s[index]]= true
index++
}
for j:=i;j<index;j++{
m[s[j]] = false
}
ans = max(ans,index-i)
}
return ans
}
思路一
i , j两层循环遍历位置,选择最小高度,提取最大值 然而两层循环超时了
思路二
头尾双指针,不断抛弃h[index]较小的一方,max提取最大值
package main
import "fmt"
func main() {
fmt.Println(maxArea([]int{1,8,6,2,5,4,8,3,7}))
}
func maxArea(height []int) int {
ans := 0
i,j:=0,len(height)-1
for j>i {
area := min(height[i],height[j]) * (j-i)
ans = max(ans,area)
if height[i]>height[j]{
j--
}else{
i++
}
}
return ans
}
func min(a,b int)int{
if a<b{return a}
return b
}
func max(a,b int)int{
if a> b {return(a)}
return b
}
a+b+c = 0 可以翻译为 a+b = -c
假设遍历a
那么问题转化为求遍历a下b+c = -a
需要注意的是不重复
例如 [1,2,3] 不重复的二元子集有 [1,2] [1,3] [2,3]
可以发现他们的索引都是01 02 12 向后递增的。如果索引为[1,0]那么生成子集[2,1]就重复了
再例如[1,2,2,2,2,3]要想不重复那么需要跳过 nums[i] == nums[i-1]
一层循环first遍历 设置target = 0-num[first] 设置二层循环second遍历 注意去重相等的情况和索引后者必须大于前者的限制。如果num[second]+num[third] > target third--
为什么是third-- 呢
因为first 和 second 已经确定了 这个时候大于的话只能左移third ,因为排序后的first和second会越来越大
func threeSum(nums []int) [][]int {
ans := [][]int{}
sort.Ints(nums)
for first := 0;first < len(nums);first++{
if first > 0 && nums[first-1] == nums[first]{continue}
target := 0-nums[first]
third := len(nums)-1
for second := first +1;second<len(nums);second ++{
if second >first+1 && nums[second-1] == nums[second]{continue}
for second < third && nums[second]+nums[third]>target{
third--
}
if second == third {break}
if nums[second]+nums[third]==target{
ans = append(ans,[]int{nums[first],nums[second],nums[third]})
}
}
}
return ans
}{ [ [ ] ] } 这一种需要压入栈中。 过程为
一次遍历,遇到左括号,压入栈,遇到右括号,看与栈顶是否匹配,如果匹配,出栈
如果一个元素们没有匹配,且为右括号 返回false 全部结束栈中还有未匹配的左括号,返回false
最后返回true
package main
import "fmt"
func main() {
fmt.Println(isValid("("))
}
/*
*/
func isValid(s string) bool {
stack := []byte{}
for i:=0;i<len(s);i++{
if s[i] == '(' || s[i] == '{' || s[i] == '['{
stack = append(stack,s[i])
continue
}
matched := false
if len(stack)>0{
peekStack := stack[len(stack)-1]
if (s[i] == ']' && peekStack == '[') ||(s[i] == '}' && peekStack == '{') || (s[i] == ')' && peekStack == '('){
stack = stack[:len(stack)-1]
matched = true
}
}
if (s[i] == ')' || s[i] == '}' || s[i] == ']')&& !matched{
return false
}
}
if len(stack) != 0{return false}
return true
}
空表返回另一个
每次递归选择值最小的
最小值.Next = merge()
package main
import "fmt"
func main() {
list1 := &ListNode{Val: 0,Next: &ListNode{Val: 1,Next: &ListNode{Val: 2}}}
list2 := &ListNode{Val: 1,Next: &ListNode{Val: 2,Next: &ListNode{Val: 3}}}
m := mergeTwoLists(list1,list2)
fmt.Println(m.Val)
}
type ListNode struct{
Val int
Next *ListNode
}
func mergeTwoLists(list1 *ListNode, list2 *ListNode) *ListNode {
if list2 == nil{return list1}
if list1 == nil{return list2}
if list1.Val>list2.Val{
list2.Next = mergeTwoLists(list1,list2.Next)
return list2
}else{
list1.Next = mergeTwoLists(list1.Next,list2)
return list1
}
}
超时解法
一次遍历
二次遍历
求和
求最大值
func max(a,b int) int{
if a>b {
return a
}
return b
}
func maxSubArray(nums []int) int {
ans := nums[0]
for i := 0;i<len(nums);i++{
sum := 0
for j:=i;j<len(nums);j++{
sum += nums[j]
ans = max(ans,sum)
}
}
return ans
}
动态规划解法
dp[0] = nums[0]
dp[i] = max(dp[i-1] + nums[i],nums[i])
func maxSubArray(nums []int) int {
ans := nums[0]
dp := make([]int,len(nums))
dp[0] = nums[0]
for i := 1;i<len(nums);i++{
dp[i] = max(dp[i-1]+nums[i],nums[i])
ans = max(ans,dp[i])
}
return ans
}
func max(a,b int) int{
if a>b {
return a
}
return b
}爬楼梯为经典的动态规划题目。爬N个楼梯可以翻译为爬N-1个楼梯与爬N-2个楼梯的和
写作 f(n) = f(n-1) + f(n-2) n>=3
官方采用了滚动数组节省空间,因为dp只需要存 f(n) f(n-1) f(n-2)三个数
最难以理解的是滚动数组的初始参数官方给的是0 0 1,虽然是对的但是实在是难以理解
我认为f(0)已经超出理解范围了。最小的应该是f(1) = 1
func climbStairs(n int) int {
if n ==1{return 1}
if n == 2{return 2}
dp := make([]int,3)
dp[0] = 1
dp[1] = 2
dp[2] = 3
for i:=4;i<=n;i++{
dp[0] = dp[1]
dp[1] = dp[2]
dp[2] = dp[1] + dp[0]
}
return dp[2]
}中序遍历的意思是根节点在中间被访问。因此递归顺序为左中右
package main
func main() {
}
type TreeNode struct{
Val int
Left *TreeNode
Right *TreeNode
}
func inorderTraversal(root *TreeNode) []int {
if root == nil{return nil}
ans := []int{}
ans = append(ans,inorderTraversal(root.Left)...)
ans = append(ans,root.Val)
ans = append(ans,inorderTraversal(root.Right)...)
return ans
}
看了题解才明白,一个树是对称二叉树可以转换为左右子树相互对称
判断左右子树是否对称的方法是
左子树的左边与右子树的右边对称或值相等
右子树的左边与左子树的右边对称或值相等
func isSymmetric(root *TreeNode) bool {
return check(root.Left,root.Right)
}
func check(left,right *TreeNode)bool{
if left == nil && right == nil{return true}
if left == nil || right == nil{return false}
if left.Val != right.Val{return false}
return check(left.Left,right.Right) && check(left.Right,right.Left)
}对左右子树的长度取最大值就是当前的最大深度
当前层要加1
递归出口为root == nil 返回0
func maxDepth(root *TreeNode) int {
if root == nil{return 0}
return 1 + max(maxDepth(root.Left) , maxDepth(root.Right))
}
func max(a,b int) int {
if a> b{return a}
return b
}模拟,假设某个位置买入,某个位置卖出,取最大值
结果超时了
func maxProfit(prices []int) int {
ans := 0
for i:=0;i<len(prices);i++{
for j := i+1;j<len(prices);j++{
ans = max(ans,(prices[j]-prices[i]))
}
}
return ans
}
func max(a,b int)int {
if a>b{return a}
return b
}看题解学到,如果当前值比我小,记录最小值;如果当前利润比我大,记录最大利润。
返回最大利润
func maxProfit(prices []int) int {
ans := 0
minPrice:= prices[0]
for i := 0;i<len(prices);i++{
if minPrice > prices[i]{
minPrice = prices[i]
}else if ans < prices[i] - minPrice{
ans = prices[i] - minPrice
}
}
return ans
}map记录出现次数
func singleNumber(nums []int) int {
m := map[int]int{}
for i :=0;i<len(nums);i++{
m[nums[i]]++
}
for k,v := range m{
if v == 1{
return k
}
}
return 0
}
还有不占空间的做法,看答案得知。异或运算相同的数字做异或的结果是0,因此一组数字中出现两次的数字抑或后的结果为0,0与任意数异或的结果为任意数。因此程序为所有数字做位运算
func singleNumber(nums []int) int {
single := 0
for _,v := range nums{
single ^= v
}
return single
}map存储该节点的指针是否出现过,如果出现过,则是环表,否则不是。
func hasCycle(head *ListNode) bool {
m := map[*ListNode]bool{}
cur := head
for cur != nil{
if m[cur] == true{return true}
m[cur] = true
cur = cur.Next
}
return false
}两层遍历,当链表指针相等的时候返回。
func getIntersectionNode(headA, headB *ListNode) *ListNode {
tmp1:= headA
for tmp1 != nil{
tmp2 := headB
for tmp2 != nil{
if tmp1 == tmp2{return tmp1}
tmp2 = tmp2.Next
}
tmp1 = tmp1.Next
}
return nil
}一个map搞定。统计数字出现的次数,取出现次数大于n/2的数
func majorityElement(nums []int) int {
m := map[int]int{}
for i :=0;i<len(nums);i++{
m[nums[i]]++
}
for _,v := range nums{
if m[v] > len(nums)/2{
return v
}
}
return 0
}
采用有空间的做法,tamp1= ans 的目的是,ans不移动,通过tmp1的移动最终达成ans作为答案
func reverseList(head *ListNode) *ListNode {
ar := []int{}
tmp := head
for tmp != nil{
ar = append(ar,tmp.Val)
tmp = tmp.Next
}
ans := &ListNode{Val: 0}
tmp1 := ans
for i := len(ar)-1;i>=0;i--{
tmp1.Next = &ListNode{Val: ar[i]}
tmp1 = tmp1.Next
}
return ans.Next
}左右递归互换,递归出口为root == nil
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func invertTree(root *TreeNode) *TreeNode {
if root == nil{return nil}
tmp := root.Left
root.Left = invertTree(root.Right)
root.Right = invertTree(tmp)
return root
}
丢到数组里,数组头尾指针判断是否回文
func isPalindrome(head *ListNode) bool {
ar := []int{}
tmp := head
for tmp != nil{
ar = append(ar,tmp.Val)
tmp = tmp.Next
}
i,j := 0,len(ar) - 1
for i<j{
if ar[i] != ar[j]{return false}
i++
j--
}
return true
}遍历,设置一个标志0,不等于零的移动到标志处,标志++;清除标志后的数据
func moveZeroes(nums []int) {
flag := 0
for i := 0;i<len(nums);i++{
if nums[i] != 0{
nums[flag] = nums[i]
flag++
}
}
for i:=flag;i<len(nums);i++{
nums[i] = 0
}
}数组中的数字映射到map上。遍历1到N,未出现的数字加入答案
package main
import "fmt"
func main() {
fmt.Println(findDisappearedNumbers([]int{4,3,2,7,8,2,3,1}))
}
func findDisappearedNumbers(nums []int) []int {
ans := []int{}
m := map[int]bool{}
for _,v := range nums{
m[v] = true
}
for i:=1;i<=len(nums);i++{
if m[i] == false{ans = append(ans,i)}
}
return ans
}
汉明距离表示二进制中位置不同的个数,异或求出的所有一表示位置不同bits.OnesCount()求出了不同的个数。
func hammingDistance(x,y int) int{
return bits.OnesCount(uint(x^y))
}
二叉树的直径其实就是求某一个节点的左右子树的深度的和
申明一个全局变量,在求左右子树深度的过程中能够,不断把左右深度和的最大值写入全局变量
递归求解结束后,全局变量存储的就是答案
var maxLen int
func diameterOfBinaryTree(root *TreeNode) int {
maxLen = 0
getDep(root)
return maxLen
}
func getDep(root *TreeNode) int {
if root == nil{return 0}
l := getDep(root.Left)
r := getDep(root.Right)
maxLen = max(maxLen,l+r)
return 1+max(l,r)
}
func max(a,b int)int{
if a> b {return a}
return b
}
当前的值等于左右树的值相加
当前的左边等于合并两树的左边
当前的右边等于合并两树的右边
func mergeTrees(root1 *TreeNode, root2 *TreeNode) *TreeNode {
ans := &TreeNode{}
if root1 == nil{return root2}
if root2 == nil{return root1}
ans.Val = root2.Val + root1.Val
ans.Left = mergeTrees(root1.Left,root2.Left)
ans.Right = mergeTrees(root1.Right,root2.Right)
return ans
}
使用dfs函数回溯,出口为当前指针i==长度
set存储答案
当前指针i以及i以前的值在set中已经确定,递归求解指针为i+1的值,也就是dfs(i+1)
有两种情况,一种是选择nums[i]
一种是不选择nums[i]
两种情况都要搜索dfs(i+1)
package main
func main() {
subsets([]int{1,2,3})
}
func subsets(nums []int) [][]int {
ans := [][]int{}
set := []int{}
var dfs func(int)
dfs = func(i int){
if i == len(nums){
ans = append(ans,append([]int(nil),set...))
return
}
set = append(set,nums[i])
dfs(i+1)
set = set[:len(set)-1]
dfs(i+1)
}
dfs(0)
return ans
}
回溯框架,使用used map存储已经使用的信息。
一个元素的添加和释放以及被使用的信息都要被回溯掉
递归出口条件为答案数组长度等于函数输入数组长度
func permute(nums []int) [][]int {
ans:= [][]int{}
set:= []int{}
used := map[int]bool{}
var backTrack func(set []int,used map[int]bool)
backTrack = func(set []int, used map[int]bool) {
if len(set) == len(nums){
ans = append(ans,append([]int{},set...))
}
for i :=0;i<len(nums);i++{
if used[nums[i]]{
continue
}
used[nums[i]] = true
set = append(set,nums[i])
backTrack(set,used)
used[nums[i]] = false
set = set[:len(set)-1]
}
}
backTrack(set,used)
return ans
}回溯框架
l r 表示拥有的左括号,右括号的个数
r < l 的情况要返回。因为存在 ) ( 的情况 ; 这一句避免了 ( ) ) ( 这种答案
r == l 说明元素已经全部入栈
生成的时候入栈左括号
回溯
入栈右括号
回溯
func generateParenthesis(n int) []string {
ans := []string{}
set := []byte{}
var backTrack func(l ,r int)
backTrack = func(l,r int){
if l<0 || r<0{
return
}
//r<l说明右括号已经入栈,即这种情况:)(
if r < l {return}
//说明全部都已经入栈
if r == 0 && l == 0{
ans = append(ans,string(set))
}
set = append(set,'(')
backTrack(l-1,r)
set = set[:len(set)-1]
set = append(set,')')
backTrack(l,r-1)
set = set[:len(set)-1]
}
backTrack(n,n)
return ans
}
看作两步
第一步镜像旋转注意j<i
第二步水平对称
package main
import "fmt"
func main() {
//1 2 3
//4 5 6
//7 8 9
//
//1 4 7
//2 5 8
//3 6 9
//
//7 4 1
//8 5 2
//9 6 3
ar := [][]int{[]int{1,2,3},[]int{4,5,6},[]int{7,8,9}}
rotate(ar)
fmt.Println(ar)
}
func rotate(matrix [][]int) {
for i:=0;i<len(matrix);i++{
for j :=0;j<i;j++{
matrix[i][j],matrix[j][i] = matrix[j][i],matrix[i][j]
}
}
for i:=0;i<len(matrix);i++{
for j:=0;j<len(matrix[0])/2;j++{
matrix[i][len(matrix)-1-j],matrix[i][j] = matrix[i][j],matrix[i][len(matrix)-1-j]
}
}
}
右中左遍历,sum存储累加值,当前node值为sum
func convertBST(root *TreeNode) *TreeNode {
sum := 0
var dfs func(node *TreeNode)
dfs = func(node *TreeNode) {
if node == nil{
return
}
dfs(node.Right)
sum += node.Val
node.Val = sum
dfs(node.Left)
}
dfs(root)
return root
}暴力超时解法
func productExceptSelf(nums []int) []int {
ans := make([]int,len(nums))
for i:=0;i<len(nums);i++{
ans[i] = 1
for j:=0;j<len(nums);j++{
if j == i{continue}
ans[i] *= nums[j]
}
}
return ans
}动态规划解法
ans[i] = L[i] * R[i] 每一个答案等于它左边的乘积乘以右边的乘积
L[i] = nums[i-1]*L[i-1] 左边的第i个乘积等于 nums[i-1] * L[i-1]
R[i] = nums[i+1]*R[i+1] 右边第i个乘积等于 nums[i+1] * R[i+1]
func productExceptSelf(nums []int) []int {
ans := make([]int,len(nums))
L := make([]int,len(nums))
R := make([]int,len(nums))
L[0],R[len(nums)-1] = 1,1
for i:=1;i<len(nums);i++{
L[i] = L[i-1] * nums[i-1]
}
for i:= len(nums)-2;i>=0;i--{
R[i] = R[i+1] * nums[i+1]
}
for i :=0;i<len(nums);i++{
ans[i] = L[i] * R[i]
}
return ans
}
func combinationSum(candidates []int, target int) (ans [][]int) {
//backTracking(candidates,target,0)
set := []int{}
var dfs func (target, index int)
dfs = func(target, index int) {
if index == len(candidates){
return
}
if target == 0{
ans = append(ans,append([]int(nil),set...))
return
}
dfs(target,index+1)
if target-candidates[index]>=0{
set = append(set,candidates[index])
dfs(target-candidates[index],index)
set = set[:len(set)-1]
}
}
dfs(target,0)
return ans
}先序遍历,然后构建,注意,最后要将值拷贝而不是地址拷贝
package main
import "fmt"
func main() {
root := &TreeNode{
Val:1,
Left: &TreeNode{
Val: 2,
Left: &TreeNode{
Val: 3,
},
Right: &TreeNode{
Val: 4,
},
},
Right: &TreeNode{
Val: 5,
Left: nil,
Right: &TreeNode{Val: 6},
},
}
flatten(root)
fmt.Println("a")
}
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
type TreeNode struct{
Val int
Left *TreeNode
Right *TreeNode
}
func flatten(root *TreeNode) {
ans := &TreeNode{Val: 0}
tmp := ans
var dfs func(root *TreeNode)
dfs = func(root *TreeNode){
if root == nil{
return
}
tmp.Right = &TreeNode{Val:root.Val}
tmp = tmp.Right
dfs(root.Left)
dfs(root.Right)
}
dfs(root)
if root != nil {
*root = *ans.Right
}
}
/*
[1,2,5,3,4,null,6]
1
2 5
3 4 null 6
*/trie的数据结构为
isEnd存储该trie是否为末尾
children存储26个字母
Insert函数对于空的trie children进行创建
一个字段为this打工
最后一个字段标记isEnd
新写了一个SearchPrefix函数,对于空返回nil 最后返回node
type Trie struct {
isEnd bool
children [26]*Trie
}
func Constructor() Trie {
return Trie{}
}
func (this *Trie) Insert(word string) {
node := this
for _,w := range word{
w -= 'a'
if node.children[w] == nil{
node.children[w] = &Trie{}
}
node = node.children[w]
}
node.isEnd = true
}
func (this *Trie)SearchPrefix(word string) *Trie {
node := this
for _,w := range word{
w -= 'a'
if node.children[w] == nil{
return nil
}
node = node.children[w]
}
return node
}
func (this *Trie) Search(word string) bool {
node := this.SearchPrefix(word)
return node != nil && node.isEnd == true
}
func (this *Trie) StartsWith(prefix string) bool {
return this.SearchPrefix(prefix) != nil
}
package main
func main() {
buildTree([]int{3,9,20,15,7},[]int{9,3,15,20,7})
}
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
/*
先序遍历的性质
根节点 左子树先序遍历的结果 右子树先序遍历的结果
中序遍历的性质
左子树中序遍历的结果 根节点 右子树中序遍历的结果
*/
func buildTree(preorder []int, inorder []int) *TreeNode {
if len(preorder) == 0{
return nil
}
root := &TreeNode{Val: preorder[0]}
j := 0
for i := 0;i<len(inorder);i++{
if inorder[i] == preorder[0]{
j = i
break
}
}
/*
先序 根 左 右
中序 左 根 右
*/
leftPreorder := preorder[1:len(inorder[:j])+1]
leftInorder := inorder[:j]
root.Left = buildTree(leftPreorder,leftInorder)
rightPreorder := preorder[len(inorder[:j])+1:]
rightInorder := inorder[j+1:]
root.Right = buildTree(rightPreorder,rightInorder)
return root
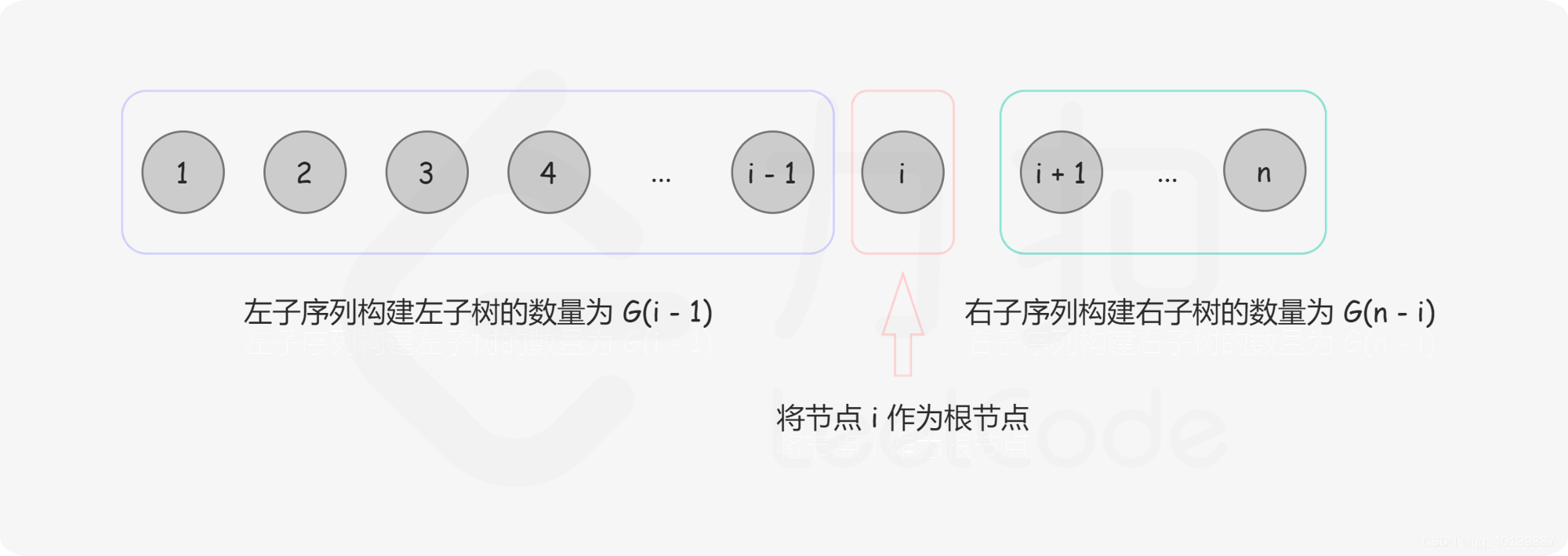
}G[n]表示长度为n的序列的二叉搜索树个数
F[i,n]表示为以i为根长度为n的序列的二叉搜索树个数
F[i,n] = G[i-1]*G[n-i]
F[i,n]等于左边乘以右边。左边右 i-1-1+1 = i-1个;右边有 n-(i+1)+1个
从而推出上述式子
G[n] = F[i,N]的累加
func numTrees(n int) int {
G := make([]int,n+1)
G[0],G[1] = 1,1
for i:=2;i<=n;i++{
for j:=1;j<=i;j++{
G[i] += G[j-1]*G[i-j]
}
}
return G[n]
}dp[i][j]表示到i,j处的最短路径和
dp[i][j] = min(dp[i-1][j],dp[i][j-1]) + grid[i][j]
带入边界,先求边界值。
dp[0][0] = grid[0][0]
dp[0][j] = dp[0][j-1] + grid[0][j]
dp[i][0] = dp[i-1][0] + grid[i][0]
func minPathSum(grid [][]int) int {
dp := make([][]int,len(grid))
for i:=0;i<len(grid);i++{
dp[i] = make([]int,len(grid[0]))
}
dp[0][0] = grid[0][0]
for i:=1;i<len(grid);i++{
dp[i][0] = dp[i-1][0] + grid[i][0]
}
for j:=1;j<len(grid[0]);j++{
dp[0][j] = dp[0][j-1] + grid[0][j]
}
for i :=1;i<len(grid);i++{
for j:=1;j<len(grid[0]);j++{
dp[i][j] = grid[i][j] + min(dp[i-1][j],dp[i][j-1])
}
}
return dp[len(dp)-1][len(dp[0])-1]
}
func min(a,b int)int{
if a<b{return a}
return b
}暴力求解,在每一个位置仰望距离最近的高温
func dailyTemperatures(temperatures []int) []int {
ans := make([]int,len(temperatures))
for i:=0;i<len(temperatures);i++{
for j:=i+1;j<len(temperatures);j++{
if temperatures[j]>temperatures[i]{
ans[i] = j-i
break
}
}
}
return ans
}一个看似简单实际晦涩的递归
type TreeNode struct{
Val int
Left *TreeNode
Right *TreeNode
}
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
if root == nil{return nil}
/*
2
3
2为最近公共祖先
*/
if root.Val == p.Val || root.Val == q.Val{
return root
}
left := lowestCommonAncestor(root.Left,p,q)
right := lowestCommonAncestor(root.Right,p,q)
/*
1
2 3 [2,3]
left=2
right=3
root=1 为最近公共祖先
*/
if left != nil && right != nil{return root}
/*
1
2 3
4 [3,4]
*/
if left == nil{return right}
if right == nil{return left}
return root
}map的键为排序后的字符串,值为字符数组存储答案
注意排序自定义函数的使用,注意比较对象
func groupAnagrams(strs []string) [][]string {
m := map[string][]string{}
for _,str := range strs{
strArray := []byte(str)
sort.Slice(strArray, func(i, j int) bool {
return strArray[i]>strArray[j]
})
s := string(strArray)
m[s] = append(m[s],str)
}
ans := [][]string{}
for _,v := range m{
ans = append(ans,v)
}
return ans
}写了个递归,结果超时了
func uniquePaths(m int, n int) int {
if m < 1 || n < 1{return 0}
if m == 1|| n == 1{return 1}
return uniquePaths(m-1,n)+uniquePaths(n-1,m)
}将每一次运算的结果存储起来多次复用,采用map[int]map[int]int存储
注意该数据结构要双层make初始化
var storeMap map[int]map[int]int
func uniquePaths(m int, n int) int {
if storeMap == nil{
storeMap = make(map[int]map[int]int)
}
if m < 1 || n < 1{return 0}
if m == 1|| n == 1{
if storeMap[m] == nil{
storeMap[m] = make(map[int]int)
}
storeMap[m][n] = 1
return 1
}
_,okOne := storeMap[m-1][n]
if ! okOne{
if storeMap[m-1] == nil{
storeMap[m-1] = make(map[int]int)
}
storeMap[m-1][n] = uniquePaths(m-1,n)
}
_, okTwo := storeMap[n-1][m]
if ! okTwo{
if storeMap[n-1] == nil{
storeMap[n-1] = make(map[int]int)
}
storeMap[n-1][m] = uniquePaths(n-1,m)
}
ans := storeMap[m-1][n] + storeMap[n-1][m]
return ans
}
一编过,列联表取到数组中,排序重构链表
注意tmp,tmp1都是打工的
func sortList(head *ListNode) *ListNode {
tmp := head
ar := []int{}
for tmp != nil{
ar = append(ar,tmp.Val)
tmp = tmp.Next
}
sort.Slice(ar, func(i, j int) bool {
return ar[i]<ar[j]
})
dummy := &ListNode{Val: 0}
tmp1 := dummy
for _,v := range ar{
tmp1.Next = &ListNode{Val: v}
tmp1 = tmp1.Next
}
return dummy.Next
}不同大小的滑窗
不同的滑窗开始位置
如果命中,获取答案
func countSubstrings(s string) int {
ans := 0
for w := 1;w <= len(s);w++{
//start :=0
//stop :=w
for start :=0;start<w;start++{
i := start
stop := start+w
for stop <= len(s){
if isAnswer(s[i:stop]){
ans++
}
i+=w
stop+=w
}
}
}
return ans
}
func isAnswer(s string) bool {
ans := true
i,j := 0,len(s)-1
for i<j{
if s[i] == s[j]{
i++
j--
}else {
ans = false
break
}
}
return ans
}
动态规划
一种是不取数字,最小值等于当前值
另一种是取数字,最小等于 1+ f(i-j^2) , 1表示取了一个数字
func min(a,b int)int{
if a<b{return a}
return b
}
func numSquares(n int) int {
f := make([]int,n+1)
for i := 1;i<=n;i++{
f[i] = i
// 将i用i个1表示是最大的情况
for j :=1;j*j<=i;j++{
f[i] = min(f[i],1+f[i-j*j])
}
}
return f[n]
}没有按照要求O(1)
要求太高了
func findDuplicate(nums []int) int {
m := map[int]int{}
for _ ,v := range nums{
m[v]++
}
for num,v := range m{
if v >1{return num}
}
return 0
}两层循环超时
func findDuplicate(nums []int) int {
for i :=0;i<len(nums);i++{
for j:=0;j<len(nums);j++{
if nums[i] == nums[j] && i != j{
return nums[i]
}
}
}
return 0
}队列解法,比较复杂
根元素先入队
只要队列q长度不为0就不退出
遍历当前队列元素,收录值到当前数组
将左右子树加入未来队列
退出条件为未来队列为空
func levelOrder(root *TreeNode)([][]int){
if root == nil{return nil}
ret := [][]int{}
q := []*TreeNode{root}
/*
只要队列q长度不为0就不退出
内部遍历当前队列
如果左右子树不为空则加入未来队列p
当前值收录到当前数组
*/
for i := 0;len(q)>0;i++{
p := []*TreeNode{}
ret = append(ret,[]int{})
for j:=0;j<len(q);j++{
ret[i] = append(ret[i],q[j].Val)
if q[j].Left != nil{
p = append(p,q[j].Left)
}
if q[j].Right != nil{
p = append(p,q[j].Right)
}
}
q = p
}
return ret
}递归解法,精妙绝伦,一般人想不出来。
如果len(ans) == i 表示刚到这一层,初始化并收录当前值
否则第i个数组收录当前值
递归左右
func levelOrder(root *TreeNode) (ans [][]int) {
var dfs func(r *TreeNode,i int)
dfs = func(r *TreeNode, i int){
if r == nil{
return
}
if len(ans) == i{
ans =append(ans,[]int{r.Val})
}else{
ans[i] = append(ans[i],r.Val)
}
dfs(r.Left,i+1)
dfs(r.Right,i+1)
}
dfs(root,0)
return
}unc findKthLargest(nums []int, k int) int {
sort.Ints(nums)
return nums[len(nums)-k]
}f根据频率排序
去重
收录答案
func topKFrequent(nums []int, k int) []int {
ans := []int{}
m := map[int]int{}
for _,v := range nums{
m[v]++
}
ar := []int{}
for _,v := range nums{
ar = append(ar,v)
}
sort.Slice(ar, func(i, j int) bool {
return m[ar[i]] > m[ar[j]]
})
for i:=0;i<len(ar);i++{
for j:=i+1;j<len(ar);j++{
if ar[j] == ar[i]{
ar[j] = math.MaxInt32
}
}
}
ars := []int{}
for _,v := range ar{
if v != math.MaxInt32{
ars = append(ars,v)
}
}
ans = ars[:k]
return ans
}f存储不调用当前节点
g存储调用当前节点
算出f[node]和g[node]
最后取最大值
func max(a,b int)int{
if a>b {return a}
return b
}
func rob(root *TreeNode) int {
var dfs func(node *TreeNode)
f := map[*TreeNode]int{}
g := map[*TreeNode]int{}
dfs = func(node *TreeNode) {
if node == nil {
return}
dfs(node.Left)
dfs(node.Right)
f[node] = node.Val + g[node.Left] + g[node.Right]
g[node] = max(f[node.Left],g[node.Left]) + max(f[node.Right],g[node.Right])
}
dfs(root)
return max(g[root],f[root])
}不让调用库函数。我偏要调用。
func sortColors(nums []int) {
sort.Ints(nums)
}每次遇到1开始dfs,把相邻的都改成0,这样答案就是遇到1的次数
func numIslands(grid [][]byte) int {
m,n := len(grid),len(grid[0])
ans := 0
data := grid
var dfs func(i,j int)
dfs = func(i,j int) {
if i <0 || j < 0 || i>=m || j >=n || data[i][j] == '0'{
return
}
data[i][j] = '0'
dfs(i,j+1)
dfs(i,j-1)
dfs(i-1,j)
dfs(i+1,j)
}
for i := 0;i<m;i++{
for j:=0;j<n;j++{
if data[i][j] == '1'{
dfs(i,j)
ans++
}
}
}
return ans
}回溯法 23映射到abc def 递归到a后递归到def 因此,出口为index==len(digits)
func letterCombinations(digits string) []string {
if len(digits) == 0{return nil}
combinations := []string{}
m := map[string]string{
"2": "abc",
"3": "def",
"4": "ghi",
"5": "jkl",
"6": "mno",
"7": "pqrs",
"8": "tuv",
"9": "wxyz",
}
var backTrack func(digits string,index int,combination string)
backTrack = func(digits string, index int, combination string) {
if index == len(digits){
combinations = append(combinations,combination)
}else{
digit := string(digits[index])
letter := m[digit]
for i :=0;i<len(letter);i++{
backTrack(digits,index+1,combination+string(letter[i]))
}
}
}
backTrack(digits,0,"")
return combinations
}一个dfs写出选上当前节点的情况下的ans
pathSum递归写出未选上当前节点的ans
最后加和
func dfs(root *TreeNode,t int)int{
if root == nil{return 0}
ans := 0
if root.Val == t{
ans++
}
ans += dfs(root.Left,t-root.Val)
ans += dfs(root.Right,t-root.Val)
return ans
}
func pathSum(root *TreeNode, targetSum int) int {
if root == nil{return 0}
ans := dfs(root,targetSum)
ans += pathSum(root.Left,targetSum)
ans += pathSum(root.Right,targetSum)
return ans
}
获取数字,再获取字符,然后做字符重复
ptr表示当前字符的索引
var str string
var ptr int
func decodeString(s string) string {
str = s
ptr = 0
return getString()
}
func getDigit()int{
ret := 0
for ;str[ptr]>='0' && str[ptr]<='9';ptr++{
ret = ret*10 + int(str[ptr]-'0')
}
return ret
}
func getString()string{
if ptr == len(str) || str[ptr] == ']'{
return ""
}
ret := ""
cur := str[ptr]
repeatTime := 1
if cur >='0' && cur<='9'{
repeatTime = getDigit()
ptr++//跳过左括号
innerStr := getString()
ptr++//跳过右括号
ret = strings.Repeat(innerStr,repeatTime)
} else if cur >='a' && cur <= 'z'{
ret = string(cur)
ptr++
}
return ret+getString()
}type ListNode struct{
Val int
Next *ListNode
}
func detectCycle(head *ListNode) *ListNode {
m := map[*ListNode]int{}
tmp := head
for tmp != nil{
m[tmp]++
tmp = tmp.Next
if m[tmp]>1{return tmp}
}
return nil
}
仅仅对不是连续序列起始点的点进行遍历这个优化很重要,否则过不了
数据导入map
func longestConsecutive(nums []int) int {
if len(nums) ==0{return 0}
m := map[int]bool{}
ans := 1
for _,v := range nums{
m[v] = true
}
for k,_ := range m{
if !m[k-1]{
curNum := k
curAns := 1
for m[curNum+1] == true{
curNum++
curAns++
if curAns>ans{
ans = curAns
}
}
}
}
return ans
}暴力对字符排序,如果排序结果相同,则为异位词,结果超时了
func findAnagrams(s string, p string) []int {
if len(p)>len(s){return nil}
ans := []int{}
sortedP := sortStr(p)
for i := 0;i+len(p)<=len(s);i++{
if sortStr(s[i:i+len(p)]) == sortedP{
ans = append(ans,i)
}
}
return ans
}
func sortStr(s string)string{
ansAr := []byte(s)
sort.Slice(ansAr, func(i, j int) bool {
return ansAr[i]<ansAr[j]
})
return string(ansAr)
}在每个i处,当j<i时 如果 num[i]>nums[j]
那么dp[i]取所有dp[j]中的最大值再加1
dp[i]表示从0到i的最大序列长度
总答案取dp[i]的最大值
func lengthOfLIS(nums []int) int {
if len(nums)==0{
return 0
}
/*
dp[i] = max(dp[j])+1 nums[i]>nums[j]
*/
ans := 1
dp := make([]int,len(nums))
dp[0] = 1
for i:=1;i<len(nums);i++{
dp[i] = 1
for j := 0;j<i;j++{
if nums[i]>nums[j]{
dp[i] = max(dp[i],dp[j]+1)
}
}
ans = max(ans,dp[i])
}
return ans
}
func max(a,b int)int {
if a>b {return a}
return b
}dp[i]表示从0到i间房子的总金额
如果偷第i间房子,则没法偷第i-1间房子
最大值为 dp[i-2]+nums[i]
另一种情况为不偷第i间房子 那就可以头i-1
最大值为dp[i-1]
因此 dp[i] = max(dp[i-1],nums[i]+dp[i-2])
func rob(nums []int) int {
if len(nums) == 0{return 0}
if len(nums) == 1{return nums[0]}
dp := make([]int,len(nums))
dp[0] = nums[0]
dp[1] = max(nums[0],nums[1])
for i := 2;i<len(nums);i++{
dp[i] = max(dp[i-1],nums[i]+dp[i-2])
}
return dp[len(dp)-1]
}
func max(a,b int)int{
if a>b{return a}
return b
}m map 存储所有合法字符
dp[i]表示当前s[:i] 字符串合法
dp[i] = dp[j] && m[j:i]
当前字符合法相当于子字符s[j:i]合法且dp[j]合法
func wordBreak(s string, wordDict []string) bool {
m := map[string]bool{}
for _,v := range wordDict{
m[v] = true
}
dp := make([]bool,len(s)+1)
dp[0] = true
for i:=1;i<=len(s);i++{
for j:=0;j<i;j++{
if dp[j] == true && m[s[j:i]]{
dp[i] = true
break
}
}
}
return dp[len(s)]
}这题没做,直接贴了答案
type LRUCache struct {
size int
capacity int
cache map[int]*DLinkedNode
head, tail *DLinkedNode
}
type DLinkedNode struct {
key, value int
prev, next *DLinkedNode
}
func initDLinkedNode(key, value int) *DLinkedNode {
return &DLinkedNode{
key: key,
value: value,
}
}
func Constructor(capacity int) LRUCache {
l := LRUCache{
cache: map[int]*DLinkedNode{},
head: initDLinkedNode(0, 0),
tail: initDLinkedNode(0, 0),
capacity: capacity,
}
l.head.next = l.tail
l.tail.prev = l.head
return l
}
func (this *LRUCache) Get(key int) int {
if _, ok := this.cache[key]; !ok {
return -1
}
node := this.cache[key]
this.moveToHead(node)
return node.value
}
func (this *LRUCache) Put(key int, value int) {
if _, ok := this.cache[key]; !ok {
node := initDLinkedNode(key, value)
this.cache[key] = node
this.addToHead(node)
this.size++
if this.size > this.capacity {
removed := this.removeTail()
delete(this.cache, removed.key)
this.size--
}
} else {
node := this.cache[key]
node.value = value
this.moveToHead(node)
}
}
func (this *LRUCache) addToHead(node *DLinkedNode) {
node.prev = this.head
node.next = this.head.next
this.head.next.prev = node
this.head.next = node
}
func (this *LRUCache) removeNode(node *DLinkedNode) {
node.prev.next = node.next
node.next.prev = node.prev
}
func (this *LRUCache) moveToHead(node *DLinkedNode) {
this.removeNode(node)
this.addToHead(node)
}
func (this *LRUCache) removeTail() *DLinkedNode {
node := this.tail.prev
this.removeNode(node)
return node
}翻译为找到一组子集,使和为总和的一半
动态规划 dp[i][j] 表示在0到i中选取若干个正整数(可以是0个),使得选取数的和是否为目标
注意边界条件 所有dp[i][0] = true 这个我想通了。 dp[i][0]是从0到i中选择几个数使得他们的和为0,选择0个数就行了,所以是true;另外,当 i==0 时,只有一个正整数nums[0] 可以被选取,因此 dp[0][nums[0]] = true
func canPartition(nums []int) bool {
if len(nums) < 2 {return false}
maxNum := 0
sum := 0
for _,n := range nums{
sum += n
if n > maxNum{
maxNum = n
}
}
if maxNum>sum/2{
return false
}
if sum%2 == 1{return false}
target := sum/2
dp := make([][]bool,len(nums))
for i := 0;i<len(dp);i++{
dp[i] = make([]bool,target+1)
}
for i := 0;i<len(nums);i++{
dp[i][0] = true
}
dp[0][nums[0]] = true
for i := 1;i<len(nums);i++{
v := nums[i]
for j :=1 ;j<=target;j++{
if v > j{
dp[i][j] = dp[i-1][j]
/*
不选
*/
}else{
dp[i][j] = dp[i-1][j] || dp[i-1][j-v]
/*
选或不选
*/
}
}
}
return dp[len(nums)-1][target]
}
大于限制条件的空间是没有必要搜索的,在限制空间内搜索
func searchMatrix(matrix [][]int, target int) bool {
for i:=0;i<len(matrix)&&matrix[i][0]<=target;i++{
for j:=0;j<len(matrix[0])&&matrix[0][j]<=target;j++{
if matrix[i][j] == target{
return true
}
}
}
return false
}
回溯,分为sum - num[index]和sum +num[index]两种情况
当sum==target时,记录为一种答案
func findTargetSumWays(nums []int, target int) int {
count := 0
var dfs func(index,sum int)
dfs = func(index, sum int) {
if index == len(nums){
if target == sum{
count++
}
return
}
dfs(index+1,sum-nums[index])
dfs(index+1,sum+nums[index])
}
dfs(0,0)
return count
}动态规划 dp[i][j]存储以i,j为右下角下标的最大正方形边长
注意初始化时的取值为所有字符- '0'
注意初始化如果dp[i][j] == 1则side = 1
注意动态方程表达式为 dp[i][j] = 1 + min(dp[i][j-1],dp[i-1][j],dp[i-1][j-1])
func maximalSquare(matrix [][]byte) int {
ans := 0
side :=0
dp := make([][]int,len(matrix))
for i := 0;i<len(matrix);i++{
dp[i] = make([]int, len(matrix[0]))
for j :=0;j<len(dp[0]);j++{
dp[i][j] = int(matrix[i][j]-'0')
if dp[i][j] == 1 {
side = 1
}
}
}
for i := 1;i<len(dp);i++{
for j :=1;j<len(dp[0]);j++{
if dp[i][j] == 1{
dp[i][j] = 1 + min(min(dp[i][j-1],dp[i-1][j]),dp[i-1][j-1])
if dp[i][j]>side{
side = dp[i][j]
}
}
}
}
ans = side * side
return ans
}
func min(a,b int)int{
if a<b{return a}
return b
}根据左节点排序
如果当前节点的左边大于答案的右边,说明无法重合,将该节点直接加入答案
否则,重合,重合的话右边取 最后一个答案的右边和当前节点右边的最大值
func merge(intervals [][]int) (ans[][]int) {
sort.Slice(intervals, func(i, j int) bool {
return intervals[i][0]<intervals[j][0]
})
ans = append(ans,intervals[0])
for i :=1;i<len(intervals);i++{
if intervals[i][0] > ans[len(ans)-1][1]{
ans= append(ans,intervals[i])
}else{
ans[len(ans)-1][1] = max(ans[len(ans)-1][1],intervals[i][1])
}
}
return
}
func max(a,b int)int{
if a>b {return a}
return b
}
动态规划
dp[i]表示的意思一般是题目直接提问的翻译。例如本题中题目提问是:计算并返回可以凑成总金额所需的最少的硬币个数。因此dp[i]表示凑成总金额i需要的最小硬币个数。答案返回dp[amount]即可。
dp[i]表示组成金额i需要的最少硬币数量
dp[i] = min(dp[i],dp[i-coins[j]]+1)
dp[i-coins[j]]+1表示取最少个数加上当前个数coins[j]的1
注意初始化为硬币数量大于amount
因为计算最小值需要初始化成更大值
func coinChange(coins []int, amount int) int {
dp := make([]int,amount+1)
for i := 1;i<=amount;i++{
dp[i] = amount+1
}
for i := 1;i<=amount;i++{
for j:=0;j <len(coins);j++{
if i-coins[j] >=0{
dp[i] = min(dp[i],dp[i-coins[j]]+1)
}
}
}
if dp[amount]>amount{
return -1
}
return dp[amount]
}
func min(a, b int) int {
if a < b {
return a
}
return b
}sum表示下标为 j,i 的子数组的和
注意j是从大到小枚举
很巧妙,跟买卖股票的题目很像
func subarraySum(nums []int, k int) (ans int) {
for i :=0;i<len(nums);i++{
sum :=0
for j:=i;j>=0;j--{
sum += nums[j]
if sum == k{
ans++
}
}
}
return ans
}先数出链表长度,停留在倒数K+1个节点处,删除。
package main
func main() {
l:= &ListNode{
Val: 1,
Next: &ListNode{
Val: 2,
Next: &ListNode{
Val: 3,
Next: &ListNode{
Val: 4,
Next: &ListNode{
Val: 5,
Next: nil,
},
},
},
},
}
removeNthFromEnd(l,2)
}
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
type ListNode struct{
Val int
Next *ListNode
}
func removeNthFromEnd(head *ListNode, n int) *ListNode {
tmp := head
l :=0
for tmp != nil{
tmp = tmp.Next
l++
}
dummy := &ListNode{0, head}
cur := dummy
for i := 0; i < l-n; i++ {
cur = cur.Next
}
cur.Next = cur.Next.Next
return dummy.Next
}
package main
func search(nums []int, target int) int {
for i := 0;i<len(nums);i++{
if nums[i] == target{return i}
}
return -1
}
精妙绝伦的贪心
rightMost维护最远可达 i + nums[i]
只有满足 i<= rightMost才可计算,否则不可达
package main
func main() {
canJump([]int{3,2,1,0,4})
}
func max(a,b int)int{
if a>b{return a}
return b
}
func canJump(nums []int) bool {
rightMost := 0
for i := 0;i<len(nums);i++{
if i<=rightMost{
rightMost = max(rightMost,i+nums[i])
if rightMost >= len(nums)-1{
return true
}
}
}
return false
}
package main
func main() {
}
func maxProduct(nums []int) int {
ans := nums[0]
maxF := nums[0]
minF := nums[0]
for i:=1;i<len(nums);i++{
mx,mn := maxF,minF
maxF = max(nums[i],max(mx*nums[i],mn*nums[i]))
minF = min(nums[i],min(mx*nums[i],mn*nums[i]))
ans = max(ans,maxF)
}
return ans
}
func max(x, y int) int {
if x > y {
return x
}
return y
}
func min(x, y int) int {
if x < y {
return x
}
return y
}O(n)解法
func searchRange(nums []int, target int) []int {
ans := make([]int,2)
ans[0],ans[1] = -1,-1
for i:=0;i<len(nums);i++{
if nums[i]==target{
ans[0] = i
for i<len(nums)&&nums[i] == target{
ans[1] = i
i++
}
}
}
return ans
}数组排序,获取值不相等的所有位置,返回其长度
注意数组拷贝要通过append拷贝值
func findUnsortedSubarray(nums []int) int {
if sort.IntsAreSorted(nums){return 0}
l,r := 0,len(nums)-1
ar := append([]int(nil),nums...)
sort.Ints(ar)
for l<len(nums) &&ar[l] == nums[l]{
l++
}
for r >= 0 && ar[r] == nums[r]{
r--
}
return r-l+1
}从右往左找到第一个降序点
在该点往右找到一个更大的点,交换
该点往右排序为顺序
func nextPermutation(nums []int) {
i := len(nums)-2
for i>-1 && nums[i]>=nums[i+1]{i--}
if i >=0{
j:=len(nums)-1
for j>-1 && nums[j]<=nums[i]{j--}
nums[i],nums[j] = nums[j],nums[i]
}
sort.Ints(nums[i+1:])
}相当于中序遍历结果严格单调递增
func isValidBST(root *TreeNode) bool {
var midOrder func(r *TreeNode)
midOrderAr := []int{}
midOrder = func(r *TreeNode) {
if r == nil{return}
midOrder(r.Left)
midOrderAr = append(midOrderAr,r.Val)
midOrder(r.Right)
}
midOrder(root)
if len(midOrderAr) == 1{return true}
i,j := 0,1
for i<len(midOrderAr) && j<len(midOrderAr){
if midOrderAr[j]<=midOrderAr[i]{return false}
i++
j++
}
return true
}func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
tmp1,tmp2 := l1,l2
dummy := &ListNode{Val: 0}
tmp := dummy
sum := 0
for tmp1!=nil || tmp2 != nil{
if tmp1 != nil{
sum += tmp1.Val
tmp1 = tmp1.Next
}
if tmp2 != nil{
sum += tmp2.Val
tmp2 = tmp2.Next
}
tmp.Next = &ListNode{Val:sum%10}
tmp = tmp.Next
sum /= 10
}
if sum == 1{tmp.Next = &ListNode{Val: 1}}
return dummy.Next
}func lengthOfLongestSubstring(s string) int {
ans := 0
for i := 0;i<len(s);i++{
m :=map[byte]bool{}
c := 0
for j:=i;j<len(s);j++{
if m[s[j]] != true{
m[s[j]] = true
c ++
}else {
ans = max(ans,j-i)
break
}
}
ans = max(ans,c)
}
return ans
}
func max(x,y int)int{
if x>y{return x}
return y
}从最大滑动窗口w开始计算 w--
start 到 stop开始滑动
func longestPalindrome(s string) string {
for w := len(s);w>=0;w--{
for start := 0;start<len(s);start++{
stop := start + w
if stop >len(s){break}
if isAnswer(s[start:stop]){
return s[start:stop]
}
}
}
return ""
}
func isAnswer(s string)bool{
i,j := 0,len(s)-1
for i<j{
if s[i] != s[j]{return false}
i++
j--
}
return true
}i<j<k会降低重复
依然会有重复,先对子答案排序,再通过map存储重复子答案的索引。最后选择不重复的子答案
超时了,不过没关系,先这样。
func threeSum(nums []int) (ans [][]int) {
if len(nums) <3{return nil}
for i := 0;i<len(nums);i++{
for j:=1;j<len(nums);j++{
for k :=2;k<len(nums);k++{
if nums[i] + nums[j] + nums[k] == 0 && i<j && j<k{
ans = append(ans,[]int{nums[i],nums[j],nums[k]})
}
}
}
}
for i, _ := range ans{
sort.Ints(ans[i])
}
index := map[int]bool{}
for i:=0;i<len(ans);i++{
for j := 0;j<len(ans)&& j != i;j++{
if ans[i][0] == ans[j][0] && ans[i][1] == ans[j][1] && ans[i][2] == ans[j][2]{
index[j] = true
}
}
}
aans := [][]int{}
for i,v:= range ans{
if !index[i]{
aans = append(aans,v)
}
}
return aans
}













 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









