







前言:
前言1:这个题的题目条件给的不太严谨,题目描述中说“如果存在解,则保证它是唯一的”,通过我的实践,我发现这句话的意思其实是本题的所有样例只有两种情况,无解/有唯一解;而不可能存在多个解的情况;
注:可以使用样例【gas=(10,10,10,10,10) cost=(1,1,1,1,1)】来验证,这个样例每个节点都可以作为起点,即样例存在多个解,但是运行后LeetCode会报错;

a
a
前言2:这个题在代码随想录上的答案也没有写清楚他的思路,而且答案提供的暴力解法超过了时间复杂度,我提供一下我的暴力解法,并将用自己的语言讲清楚我做这道题时的思路;
a
a
a
a
a
方法1:暴力求解
注:这个题看似使用暴力很简单,但是暴力其实也有一些小坑,如果不想清楚,很难直接过;
思路1:很明显暴力一定是两个循环嵌套起来的,外层使用for循环选择起点,内层则使用while循环从该起点开始一直向后开车,验证能否从新回到起点;
思路2:外层循环很好写,但是我们需要考虑一下内层循环怎么写,选择什么条件来跳出while循环呢?我定义了变量sum_gas来代表从起点走到某一个节点时邮箱里的剩余油量,那么选择【sum_gas < 0】作为跳出条件是绝对没问题的,即如果走到当前节点时邮箱里的油为负,说明选择的起点到不了这个节点,也就无法完成闭环操作;
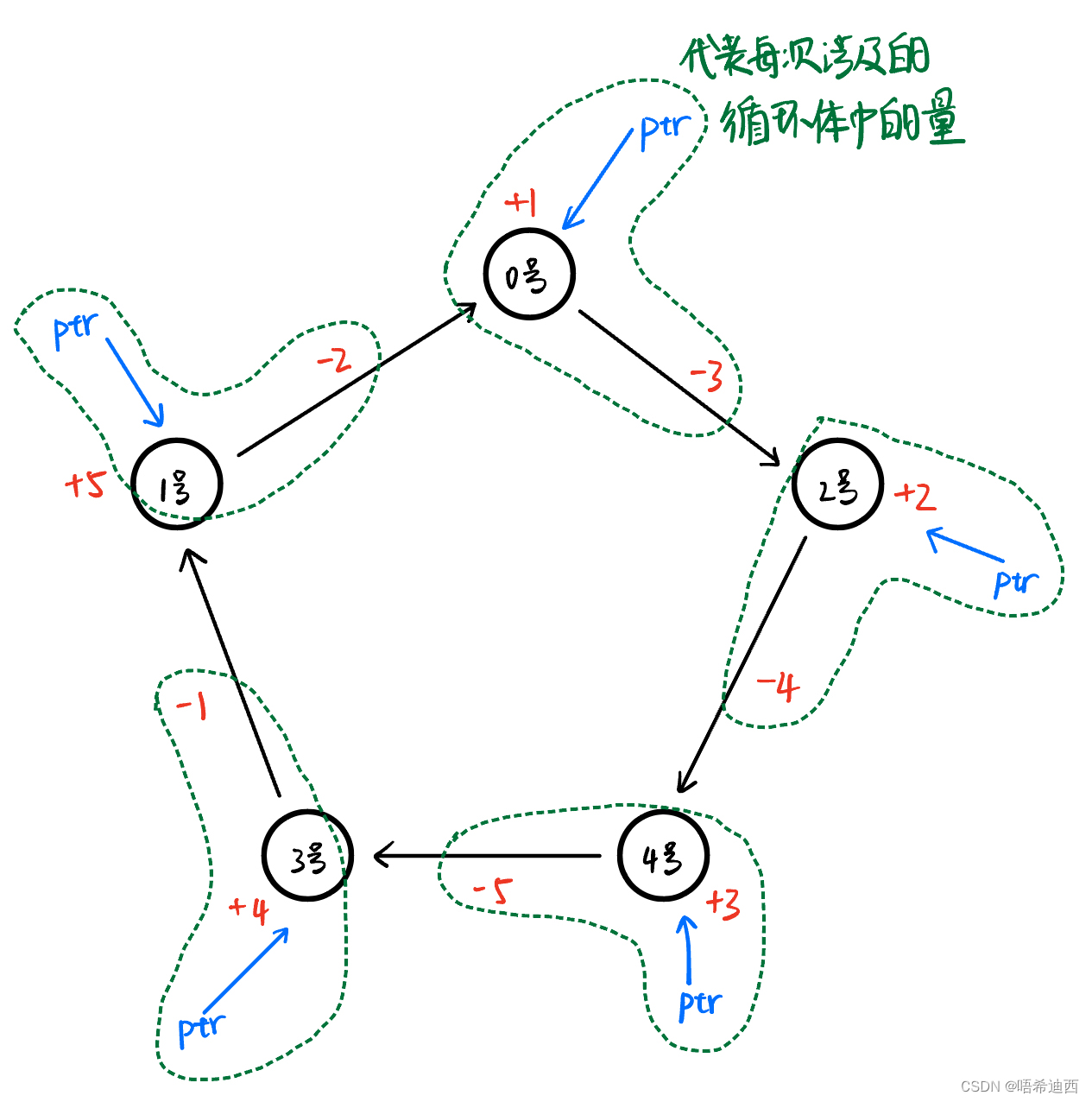
初始版本代码:这个版本的代码逻辑上完全没有问题,样例都过了,但是提交运行超时了;
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//自己尝试:暴力求解
for(int i = 0; i < gas.size(); i++) {
if(gas[i] == 0) continue; //剪枝:如果起点加油站没有,那车辆根本无法行使
int ptr = i; //选择起点为ptr
int sum_gas = gas[ptr] - cost[ptr]; //以ptr为当前出发站点,如果往后行驶一站,车的剩余油量
while(sum_gas >= 0) {
ptr = (ptr + 1) % gas.size(); //切换当前出发站点为ptr
if(ptr == i) return i;
sum_gas = sum_gas + gas[ptr] - cost[ptr]; //以ptr为当前出发站点,如果往后行驶一站,车的剩余油量
}
}
return -1;
}
};思路3:但是我现在还是不太甘心放弃使用暴力搜索,那么我想是否可以通过剪枝操作来优化一点点代码的时间复杂度?使得可以通过提交?如果要剪枝,那就只有两种情况可以剪枝,因为通过这个题的描述我们可知,这个题只有两种情况,要么无解,要么有唯一解;所以我们如何可以在还没有满足【sum_gas < 0】这个条件的时候,就可以提前知道选择当前的这个起点,到底是无解,还是有唯一解?
思路4:我们考虑一种特殊情况,即【sum_gas == 0】这种情况;如果起点到当前节点的sum_gas == 0,那么只可能有两种情况,要么无解,要么有多个解;
看下图进行分析:如果从起点x到节点z的sum_gas == 0,那么我们针对节点y进行思考;如果从节点z开始前进,那么有两种可能:
- 节点z无法到达节点x:则代表以节点x为起点,是不可能重新回到起点的,即无解;
- 节点z可以到达节点x:则节点x和节点z作为起点,都可以重新回到本身的位置,即解不唯一;
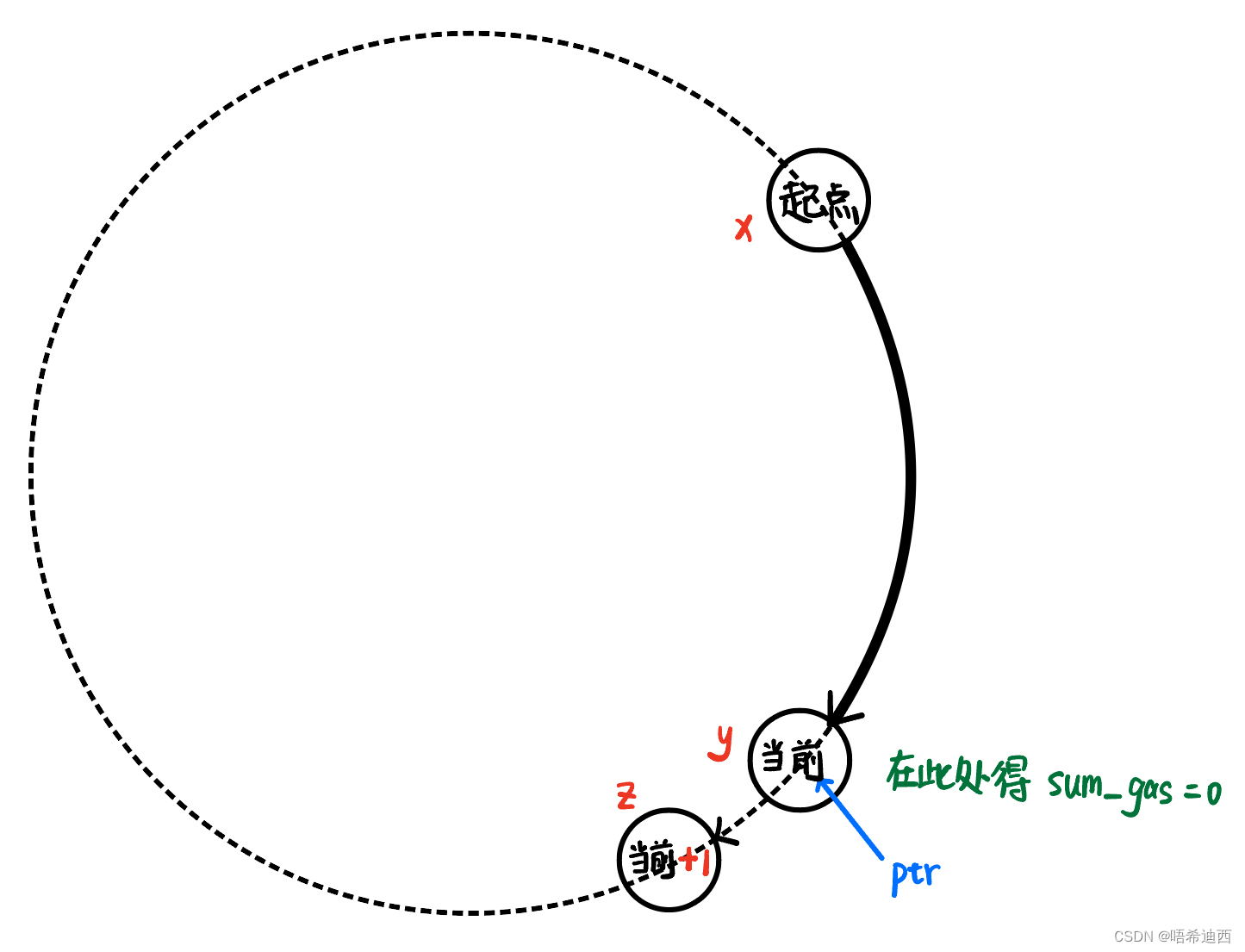
思路5:所以我们不用看到【sum_gas < 0】才跳出while循环,而可以看到【sum_gas <= 0】就跳出循环;这样就节省了时间复杂度;但是有一个特殊情况,如果从起点回到起点的过程中sum_gas == 0,那么这个时候在起点的前一个点会得到sum_gas == 0;
改进版本代码:改动一共两处
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//自己尝试:暴力求解
for(int i = 0; i < gas.size(); i++) {
if(gas[i] == 0) continue; //剪枝:如果起点加油站没有,那车辆根本无法行使
int ptr = i; //选择起点为ptr
int sum_gas = gas[ptr] - cost[ptr]; //以ptr为当前出发站点,如果往后行驶一站,车的剩余油量
while(sum_gas > 0) {
ptr = (ptr + 1) % gas.size(); //切换当前出发站点为ptr
if(ptr == i) return i;
sum_gas = sum_gas + gas[ptr] - cost[ptr]; //以ptr为当前出发站点,如果往后行驶一站,车的剩余油量
}
//剪枝:特殊情况 -- 从起点回到起点后车辆剩余油量为0
if(sum_gas == 0 && ptr == (i + gas.size() - 1) % gas.size()) return i;
}
return -1;
}
};a
a
a
a
a
方法2:贪心算法
注:使用暴力算法时间复杂度为,还是太高很容易过不了提交,有没有其他的算法可以将时间复杂度降到
或者
之类的;
样例1图解:

思路1:我们知道对于节点x,如果他的【gas[x] - cost[x] <= 0】,那么他一定不能作为起点;小于零的情况不用多说,等于零的情况在上面讨论过,要么是无解要么是多个解;所以只要节点x的【gas[x] - cost[x] <= 0】,就意味着这个节点不可以作为起点;只有【gas[x] - cost[x] > 0】的节点才有作为起点的潜质;
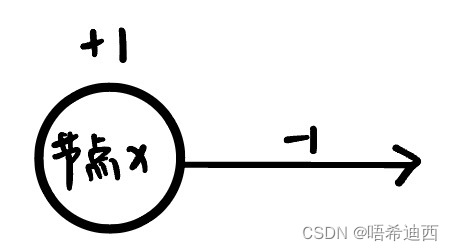
思路2:那么对于一串节点的temp_sum值,如果temp_sum小于等于0,是否也意味着这一串节点都是不能作为起点的呢?答案是肯定的;如下如示例,从节点x到节点n的temp_sum为0,那么意味着所有的节点都不可作为起点;
- 本身作为起点的节点x和其中【gas[] - cost[] <= 0】的节点y和节点m,自不必说肯定不能作为起点;
- 而节点z满足【gas[z] - cost[z] > 0】却也不能作为起点,是因为本身从节点x到节点z的【temp_sum > 0】,再加之节点z本身z满足【gas[z] - cost[z] > 0】,就这样两个正数相加,都不能突破节点m的封锁,导致在节点n处仍有【temp_sum = 0】,那么如果直接将节点z作为起点,那情况肯定更糟糕,更到达不了节点n了;

思路3:因此我们可以只用一个for循环,遍历所有的点,且每个点只访问一次,如果在这个点处获得的【temp_sum <= 0】,那么就意味着到当前位置的所有节点都不能作为起点;只能再遍历后面的节点,寻找具有成为起点潜质的新节点;
思路4:那如何判断一个节点可以作为起点,且可以回到本身?那么就需要遍历数组到头的时候,有【sum >= 0】,即可知道当前起点是满足答案约束的;在我的代码中,特殊情况(从第一个节点到最后一个节点的sum = 0)已经被包含进去了;
贪心算法代码:
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//自己尝试:贪心算法
int start = 0; //起点位置(即temp_sum的开头元素)
int sum = 0; //到当前节点时的剩余油量
int temp_sum = 0; //从起点到当前位置时的剩余油量
for(int i = 0; i < gas.size(); i++) {
sum = sum + gas[i] - cost[i];
temp_sum = temp_sum + gas[i] - cost[i];
if(temp_sum <= 0) {
temp_sum = 0;
start = i + 1;
}
}
if(sum >= 0) return (start % gas.size());
return -1;
}
};














 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









