






 本文讲述了如何在曙光智算平台上配置Python环境、使用SLURM调度资源、编写并提交作业,以及解决Keras查找问题的过程。
本文讲述了如何在曙光智算平台上配置Python环境、使用SLURM调度资源、编写并提交作业,以及解决Keras查找问题的过程。
曙光智算平台的初使用
最近得到了中科曙光服务器的免费体验资格,也是第一次用服务器跑深度学习 (穷啊,买不起服务器,实验室又不给配),记录一下这个入门过程。
使用入门
添加链接描述
进入命令行模式:
应该是也可以界面操作
进入后就按照linux环境下配置python环境,但不要在这里运行,这里是登录节点,不是计算节点,要使用sbatch提交作业到计算节点进行模型训练。
具体操作可以参考:
曙光智算入门手册
其通过slurm管理计算资源的调度,这个暂时不重要不用管
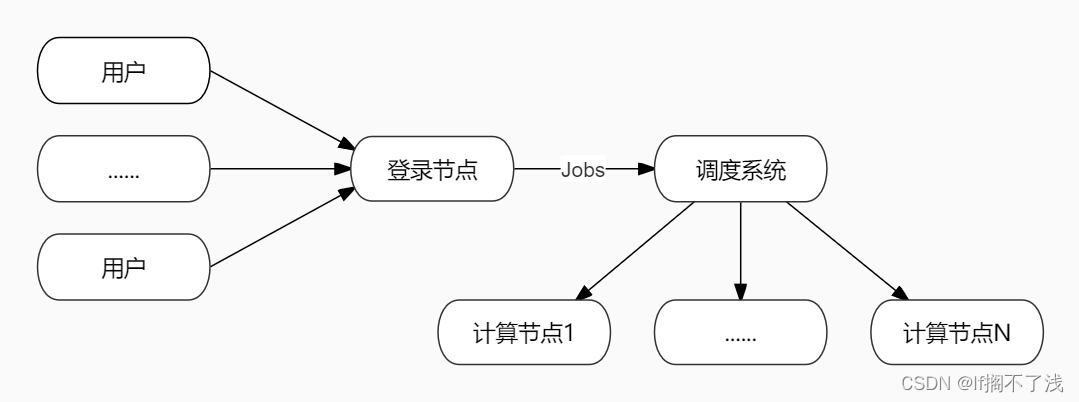
这里默认配置好了深度学习程序的运行环境,就是安装anaconda,pytorch或者tensorflow等框架,然后在工程文件夹下建立一个脚本,比如:run.sh, 通过配置这个脚本来提交作业。
比如:
#!/bin/bash
#指定作业提交的队列
#SBATCH -p kshdsctest
#指定作业申请的节点数
#SBATCH -N 1
#指定每个节点运行进程数。
#SBATCH --ntasks-per-node=32
#指定任务需要的处理器数目
#SBATCH --cpus-per-task=1
#指定每个节点使用通用资源的名称及数量
#SBATCH --gres=dcu:4
#作业名称,使用squeue看到的作业名
#SBATCH -J ceshi
#指定作业标准结果输出文件名称
#SBATCH -o output.txt
#指定作业标准错误输出文件名称
#SBATCH -e error.txt
#添加环境变量
#export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
PYTHON_HOME=/public/home/ac4r2lhqwl/miniconda3/envs
export PATH=$PYTHON_HOME/bin:$PATH
source ~/miniconda3/bin/activate
conda activate test
#加载本地环境
module load compiler/rocm/dtk-22.10.1
#运行程序
python3 run.py
PYTHON_HOME的路径换成自己的,加载本地环境的时候可以使用
module avail
查看集群现有软件活库
确定不了是哪个就都给它加载进来
因为使用sbatch提交作业后没法实时输出,但可以将输出定向到文件中,这里是output.txt
准备工作作好后
- 提交作业
sbatch run.sh

- 查看作业
squeue

3. 如果作业停了可能是程序有错误或者配置有错误,通过 cat error.txt查看
4. 实时查看输出通过tail -f output.txt查看,output.txt是在sh文件中配置过的
5. 取消作业
scancel 作业号 (JOBID)
终于跑起来了
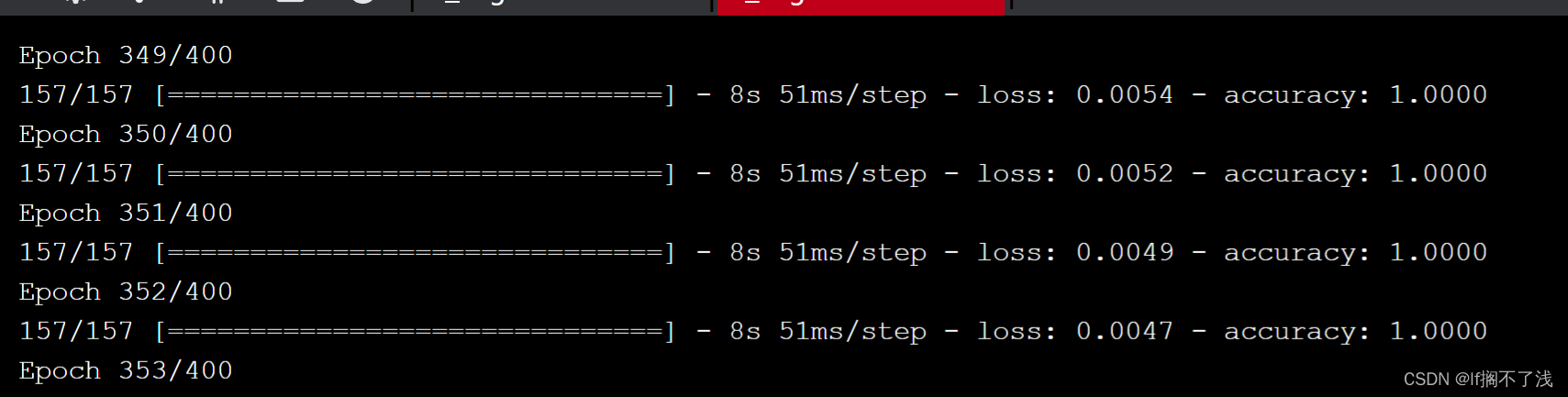
踩坑记录
提交作业后一直提示找不到Keras,但明明都安装了,我一直以为是在sh文件中国加载的环境错误,试了又试还是不行,最后发现是因为
tensorflow和keras的版本不匹配导致的

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









