







如图所示,构建工程结构
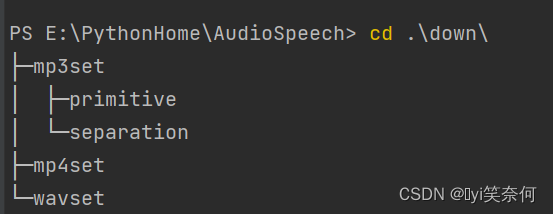
mp3set
-primitive用来存储从mp4提取出的mp3
-separation用来存储分离人声和背景音乐的mp3
mp4set用来存储爬下来的资源
wavset用来保存mp3转wav的数据
语料准备
首先需要下载安装FFmpeg并设置到系统环境变量中。
可以根据需要,使用工具爬取各大平台上面视频,下载到指定文件夹;对下载的MP4等视频文件进行格式重命名。
def NormalizedDirectory():
path = os.getcwd() + '/down/mp4set/'
file_name = os.listdir(path)
q = 1
for i in file_name:
old = path + i
new = path + str(q) + '.mp4'
print(old)
print(new)
os.rename(old, new)
q += 1抽取音频,需要提取为MP3格式的音频文件
def separationMp3():
path = os.getcwd() + '/down/'
inpath = path + 'mp4set/'
outpath = path + '/mp3set/primitive/'
file_list = os.listdir(inpath)
for file_name in file_list:
inpa = inpath + file_name
outpa = outpath + file_name[:len(file_name) - 4]
os.system('ffmpeg.exe -i ' + inpa + ' -f mp3 -vn ' + outpa + '.mp3')需要使用spleeter的python包进行人声与伴奏分离
def Peeloff():
path = os.getcwd() + '/down/'
inpath = path + 'mp3set/primitive/'
outpath = path + 'mp3set/separation/'
file_list = os.listdir(inpath)
for i in file_list:
os.system('spleeter separate -c mp3 ' + inpath + i + ' -o ' + outpath)内容标注
可以通过平台免费语音识别工具来做标注,样例以百度ASR为例,如果非普通语音需要人工标注,返回结果后自行整理保存(保存文件名需要与音乐频文件一致)。
import requests
import base64
import json
import os
API_KEY = "API_KEY"
SECRET_KEY = "SECRET_KEY"
def paddlespeech_request(wav_file):
with open(wav_file, 'rb') as f:
base64_bytes = base64.b64encode(f.read())
base64_string = base64_bytes.decode('utf-8')
url = "https://vop.baidu.com/server_api"
payload = json.dumps({
"format": "wav",
"rate": 16000,
"channel": 1,
"cuid": "cuid",
"speech": base64_string,
"len": os.path.getsize(wav_file),
"token": get_access_token()
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
if __name__ == '__main__':
wav_path = 'E:\PythonHome\AudioSpeech\down\mp3set\separation'
wav_list = os.listdir(wav_path)
for index in wav_list:
index = wav_path + '/' + index
paddlespeech_request(index)
AISHELL3格式将中文字转为拼音格式化保存为content.txt
# coding:utf8
import os
import sys
import numpy as np
from pypinyin import pinyin, lazy_pinyin, Style
import re
root_dir = "./train/td/"
pattern = re.compile(r'(.*)\.txt$')
for root, dir, files in os.walk(root_dir):
for filename in files:
output = pattern.match(filename)
if output is not None:
text_file = open(root + "/" + filename, encoding='utf-8')
line = text_file.readline()
print(line)
pinyin = lazy_pinyin(line, style=Style.TONE3, neutral_tone_with_five=True)
pinyinline = str()
for i in range(0, len(line)):
pinyinline = pinyinline + line[i] + ' ' + pinyin[i] + ' '
outline = filename[0:len(filename) - 4] + '.wav' + '\t' + pinyinline + '\n'
target_text_file = open(root + "/" + 'content.txt', "a+", encoding='utf-8')
target_text_file.write(outline)
target_text_file.close()
使用MFA生成音素长度相关内容,具体方法可以参考下方
需要前置以来kaldi环境具体安装方法如下kaldi安装方法;
然后使用MFA来操作相关,具体如下参考Github方法
















 2652
2652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











