







状态一致性
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?
什么是状态一致性
- 有状态的流处理,内部每个算子任务都可以有自己的状态
- 对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
- 一条数据不应该丢失,也不应该重复计算
- 在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
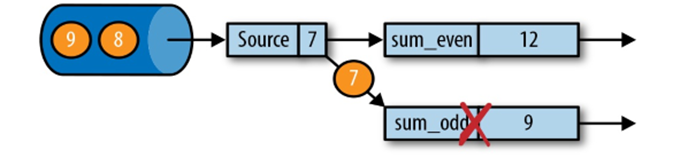
状态一致性分类
Flink的一个重大价值在于,它既保证了exactly-once,也具有低延迟和高吞吐的处理能力。
- AT-MOST-ONCE(最多一次)
当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。同样的还有udp。 - AT-LEAST-ONCE(至少一次)
在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为 at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。 - EXACTLY-ONCE(精确一次)
恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。这指的是系统保证在发生故障后得到的计数结果与正确值一致。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









