






首先打开抖音-记录美好生活 (douyin.com),这里以chrome浏览器为例
随便找一个视频,右键之后打开详情页
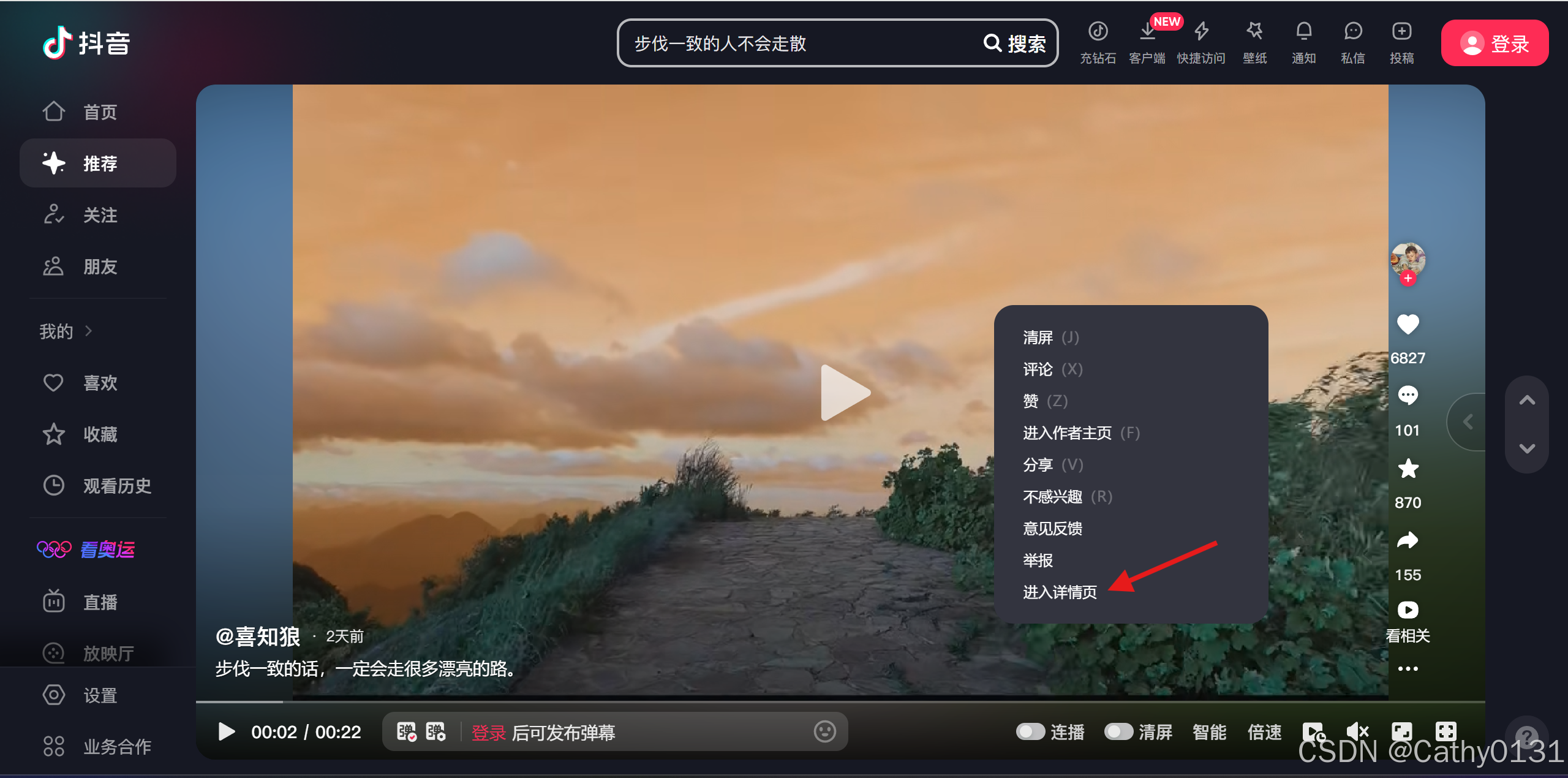
Fn+F12打开开发者模式
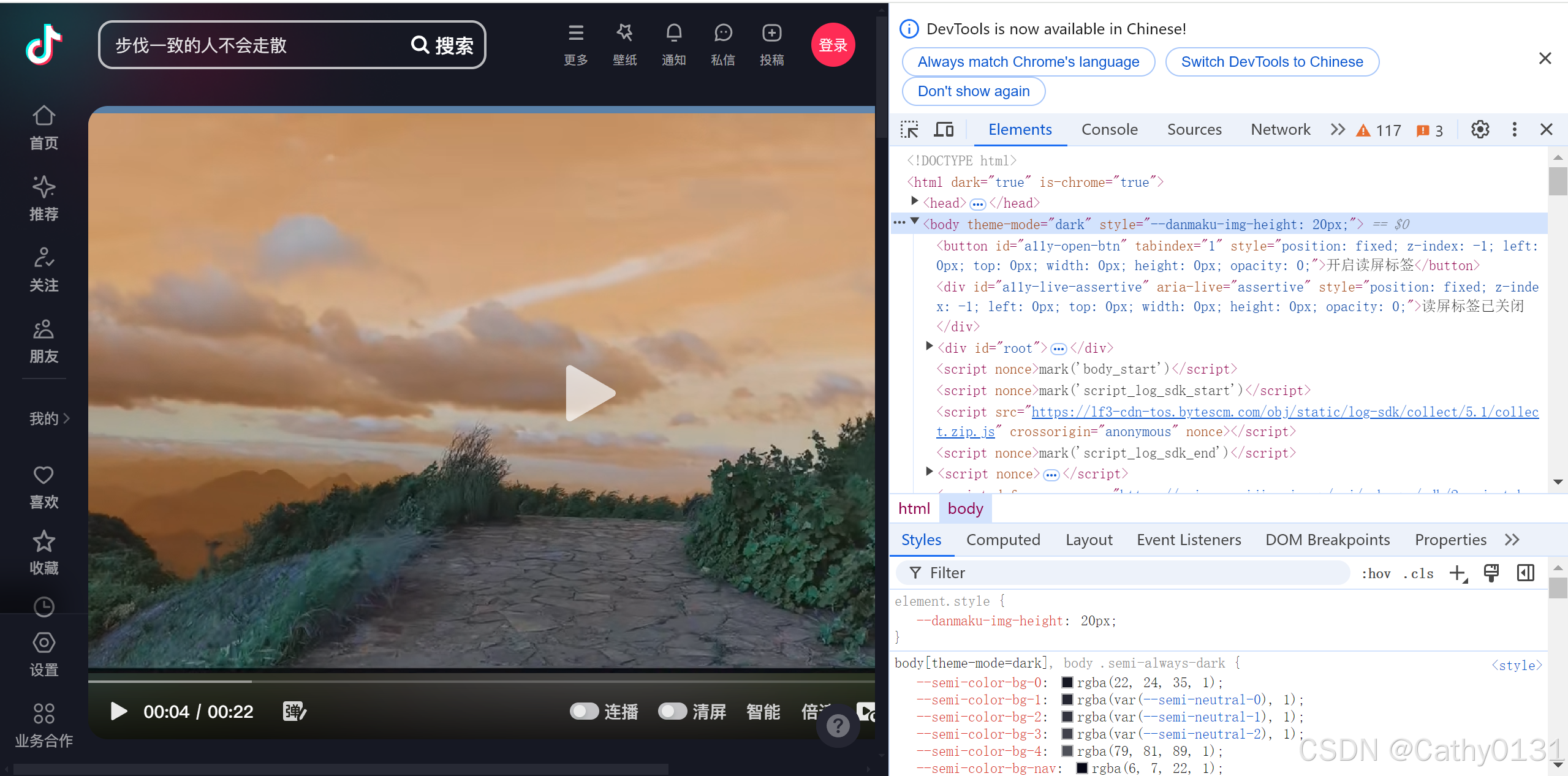
在当前页面CTRL+F进行查找,输入
www.douyin.com/aweme/v1/play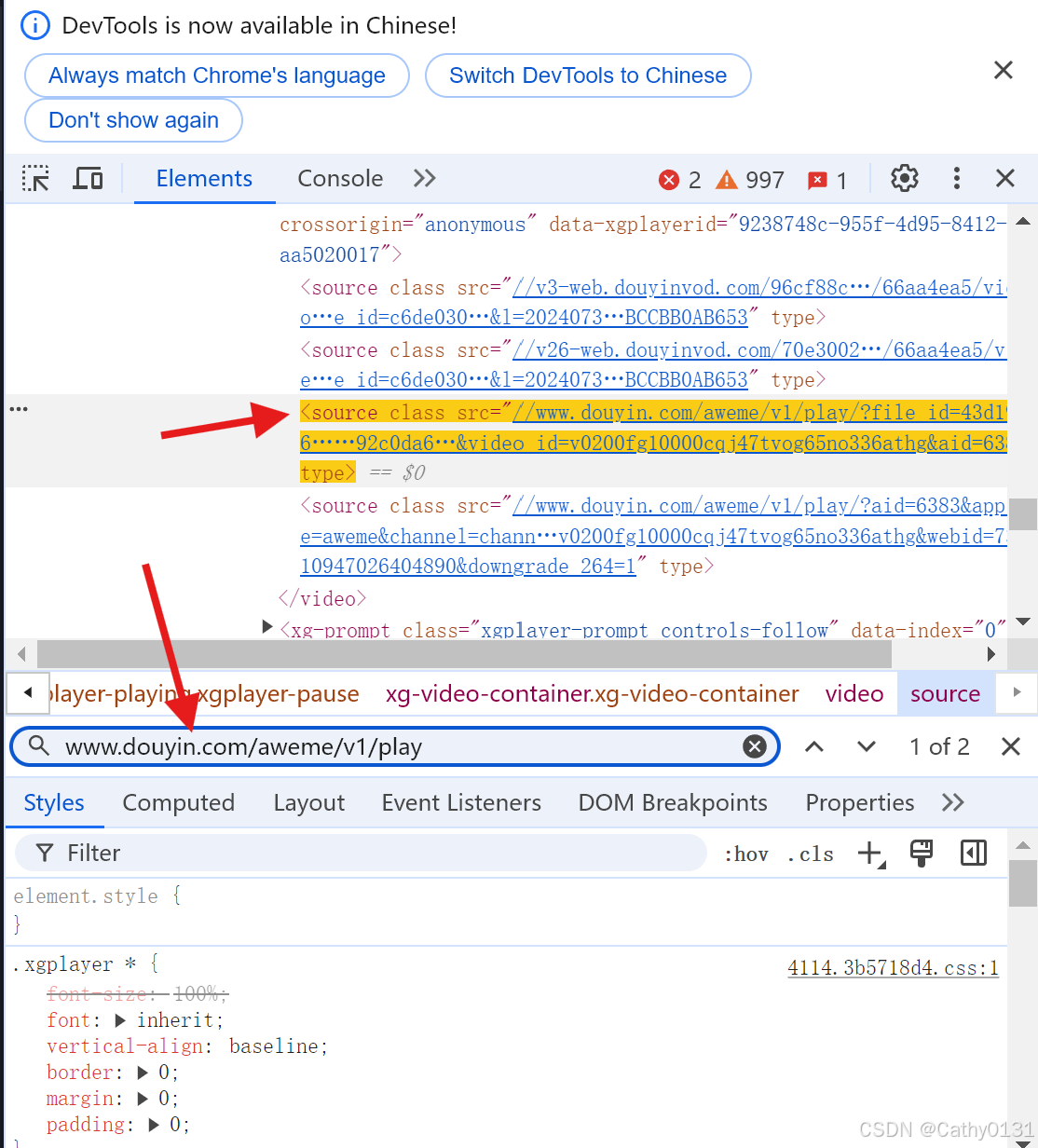
黄色高亮处就是该视频的url,双击展开这一部分代码
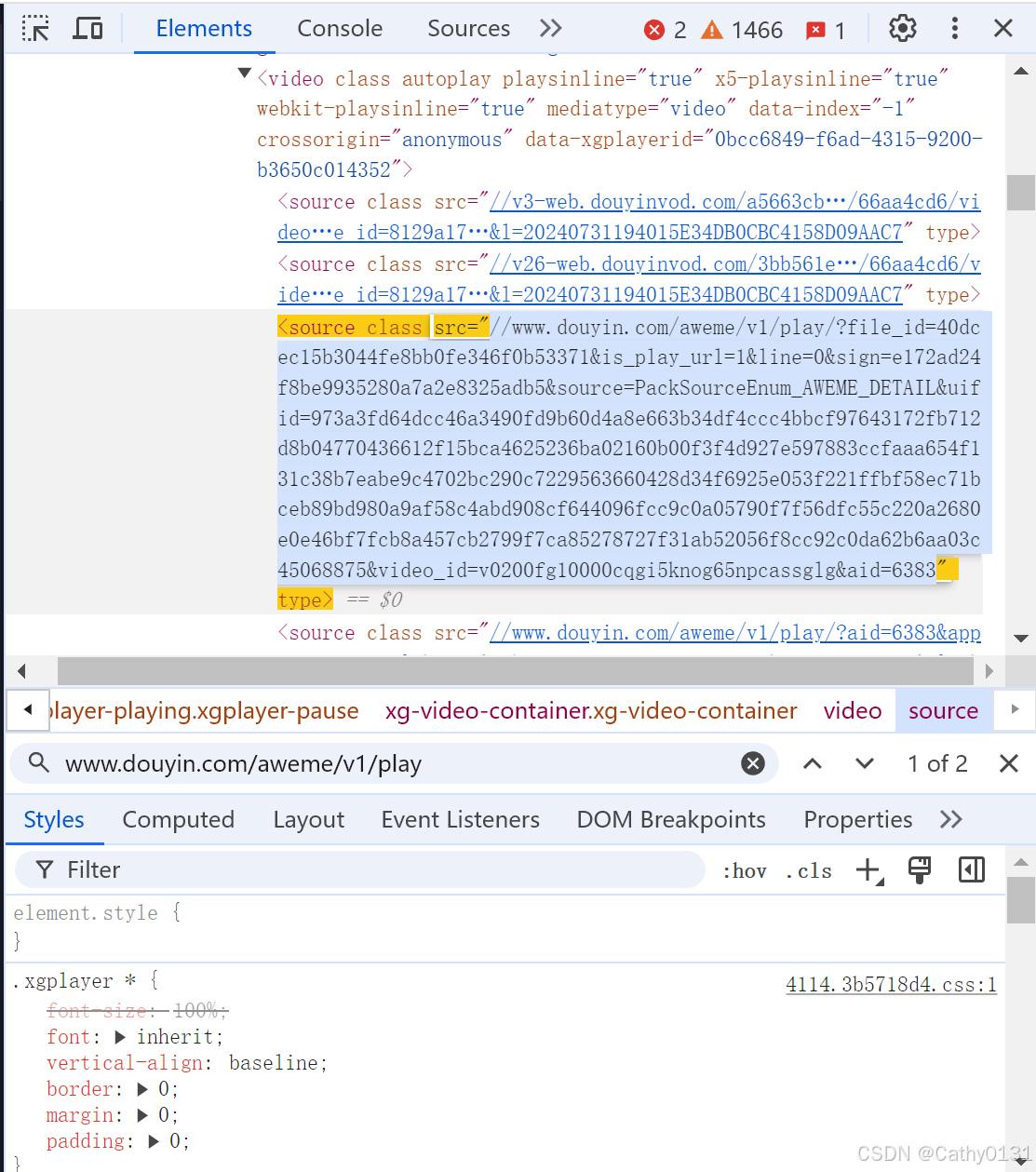
复制后得到类似以下这一串url:
//www.douyin.com/aweme/v1/play/?file_id=40dcec15b3044fe8bb0fe346f0b53371&is_play_url=1&line=0&sign=e172ad24f8be9935280a7a2e8325adb5&source=PackSourceEnum_AWEME_DETAIL&uifid=973a3fd64dcc46a3490fd9b60d4a8e663b34df4ccc4bbcf97643172fb712d8b04770436612f15bca4625236ba02160b00f3f4d927e597883ccfaaa654f131c38b7eabe9c4702bc290c7229563660428d34f6925e053f221ffbf58ec71bceb89bd980a9af58c4abd908cf644096fcc9c0a05790f7f56dfc55c220a2680e0e46bf7fcb8a457cb2799f7ca85278727f31ab52056f8cc92c0da62b6aa03c45068875&video_id=v0200fg10000cqgi5knog65npcassglg&aid=6383然后把这段url粘贴在新网页打开,这时候就可以右键保存到本地了
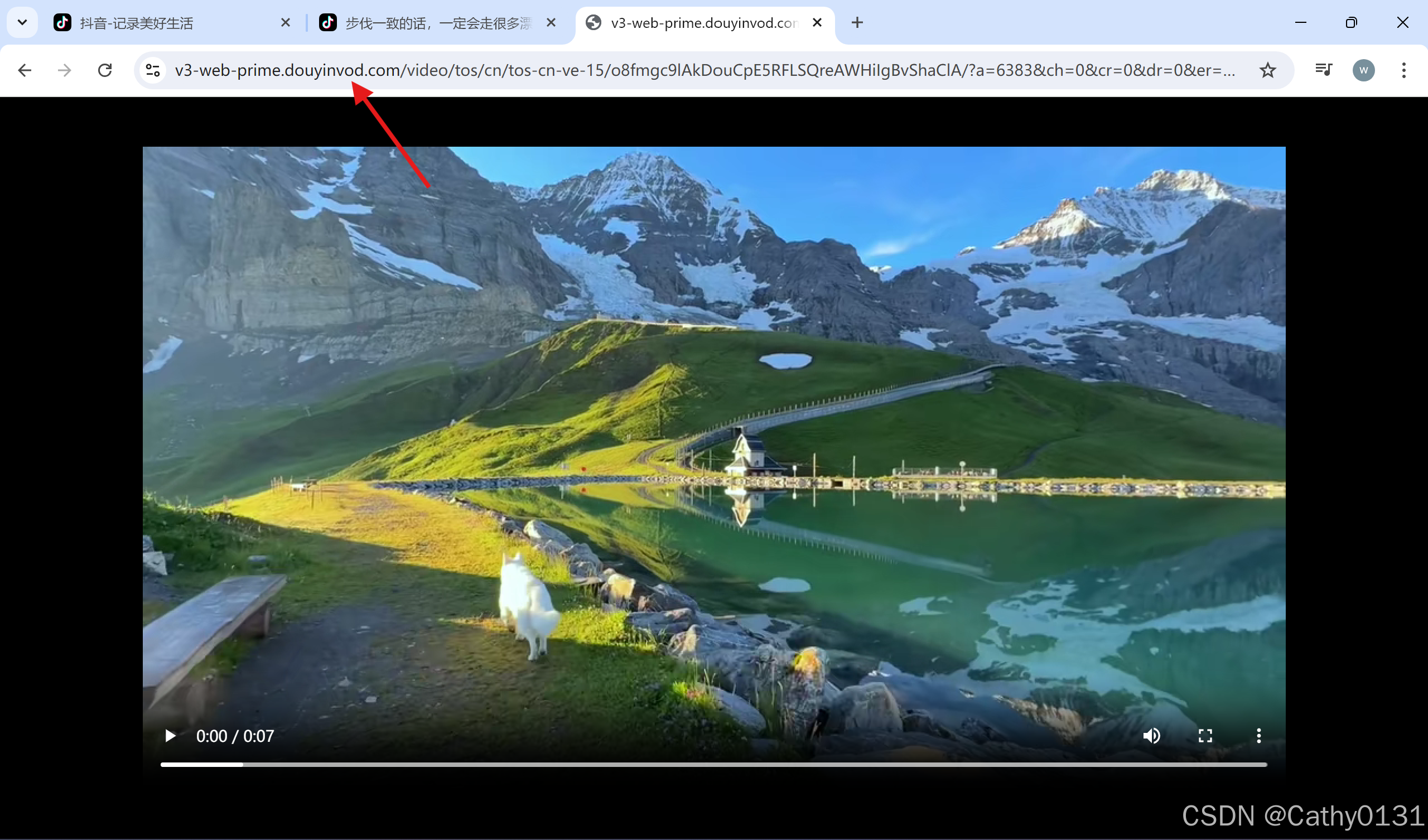
箭头处可以看到url变了,这是因为抖音使用了重定向和视频流服务来处理视频播放。当浏览器请求初始链接时,抖音的服务器会根据请求参数、用户的地理位置、网络状态等信息,动态生成一个实际的视频流url。


















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











