






前提
很长一段时间,我们部署的服务经常性的出现以下异常
ERROR druid.sql.Statement - [statementLogError,148] - {conn-10135, stmt-24201} execute error. SELECT 1 FROM DUAL
com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
The last packet successfully received from the server was 3,741,977 milliseconds ago. The last packet sent successfully to the server was 3,741,978 milliseconds ago.
// 堆栈信息
xxx
了解druid连接池的应该都知道,这是DruidDataSource下的validationQuery配置,这段sql主要用来检测连接是否有效的,所以一段时间内,我们都没有当回事儿,毕竟不是业务报错,不影响正常使用就行。
一点点小问题
随着项目的推进,我们发现不仅仅是druid内部检测的sql报错,我们的一些业务性sql同样会超时,并且这些爆出超时sql并不是slow sql,在mysql服务器上执行耗时都是毫秒级的。
值得一提的是,在我们的开发、测试、演示环境均未出现这样的情况。通过控制变量法,我们一致认定这是政务网的网络问题。
我们的数据库和业务服务在政务网是异网部署的方式,当时的结论是两个网段之间存在丢包的情况(虽然ping的通,telnet也没问题),具体是网络的哪方面原因,因为项目刚刚开始,有很多服务都需要有产出,没有时间去深究(当然也不愿意去看druid的源码)。这些超时的异常由前端隐去,然后不了了之了。
问题升级
项目中期阶段,组内有个服务上线。出现一个非常诡异的现象,项目启动后,第一次请求某个页面非常非常慢,后面再请求页面时,所有接口又都能及时响应。过了20min左右,再次访问某个页面又会卡顿,周而复始。通过arthas定位,发现响应耗时均卡在db上。
定位
近期短信服务上线,经常性出现短信发送失败的情况。页面请求在转圈,一直等到http接口响应超时。为了不影响用户体验,趁此机会我决定摸排一下这个问题。
首先想到的就是去服务器上拉取日志,看下有没有什么明显的异常信息。错误日志虽然没有找到,但是发现短信发送的日志都只输出了一部分,像是卡在了某个环节,于是乎我们用jstack <PID> 看一下当前java线程执行的堆栈情况,发现所有的数据库操作都卡在了socketRead0上。
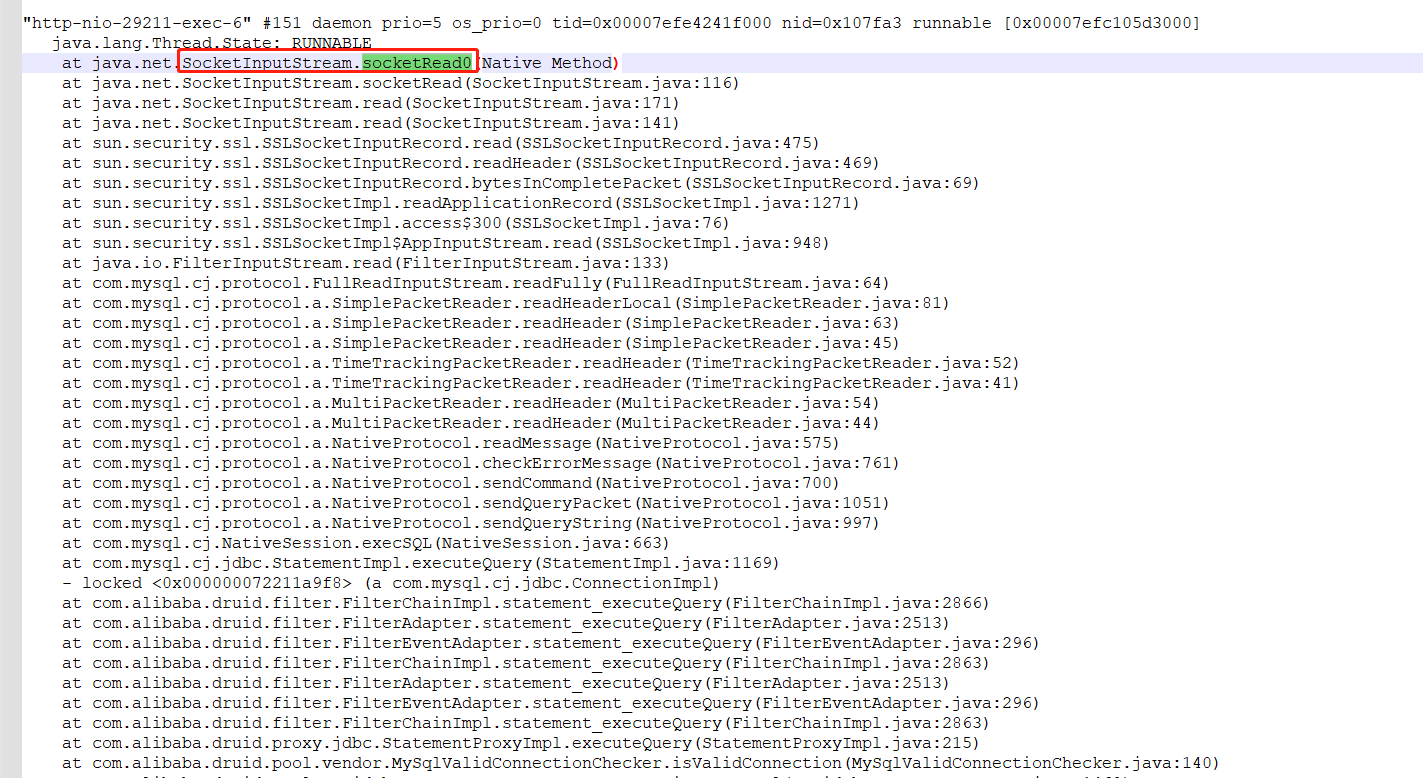
了解过数据库交互原理的应该知道,Druid是通过我们提供数据库的用户名、密码等,然后使用JDBC驱动程序来建立连接。建立连接时,JDBC驱动程序会通过TCP/IP协议与数据库服务器进行通信,以建立一个网络连接。一旦连接建立成功,JDBC API就可以使用该连接来执行SQL查询和更新操作。
看到这里,我想到以下几种可能导致的问题。
1、网络问题?按起初的想法,最先考虑的就是网络问题,如网络延迟或丢包等,那么Socket请求可能会发生阻塞。客户端发送了一个请求,如果服务器没有及时响应,那么客户端就会一直等待,直到收到服务器响应或者超时。
然而经过我的多次尝试,我发现网络并不存在丢包的情况,还算比较稳定。
2、服务器负载?如果服务器的负载过高,那么服务器可能无法及时响应客户端的请求,导致客户端的请求发生阻塞?
但是经过统计我们的QPS并不高
3、IO操作阻塞?如果客户端或服务器在进行IO操作(如读写数据)时阻塞,那么Socket请求也可能会发生阻塞。
但是实际来看,我们Sql执行的数据量并不占IO。
4、防火墙和代理服务器?这里不是指防火墙端口没有放开,否则就不会存在出现发送成功的短信了。因为我们数据库和业务服务在不同的网段,会不会是交换机的防火墙的TCP超时时长设置有问题?
再看问题之前,我们先了解一下druid的相关配置
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| keepAlive | false (1.0.28) | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
带着最后一个问题,我联系现场的人帮忙看下交换机的防火墙策略是怎样的,会不会因为防火墙TCP超时时长过小,甚至小于druid配置的minEvictableIdleTimeMillis导致物理连接已经断开,但是druid并未被驱逐。

由上图可知,TCP长连接的超时时长设置的是20min,但是我们minEvictableIdleTimeMillis设置的是5min,timeBetweenEvictionRunsMillis设置的是1min,就是说我们数据库连接池会定时每分钟检测连接,如果空闲超过5min就会关闭此连接,按理说不会有什么问题。
但是想到既然有minEvictableIdleTimeMillis,那会不会有maxEvictableIdleTimeMillis,虽然druid github上并没有给出相关配置,但是还是需要深入源码,看一下druid连接销毁的策略(主要看物理连接销毁的逻辑)。
public class DestroyTask implements Runnable {
public DestroyTask() {
}
@Override
public void run() {
shrink(true, keepAlive);
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
}
public void shrink(boolean checkTime, boolean keepAlive) {
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
boolean needFill = false;
int evictCount = 0;
int keepAliveCount = 0;
int fatalErrorIncrement = fatalErrorCount - fatalErrorCountLastShrink;
fatalErrorCountLastShrink = fatalErrorCount;
try {
if (!inited) {
return;
}
final int checkCount = poolingCount - minIdle;
final long currentTimeMillis = System.currentTimeMillis();
for (int i = 0; i < poolingCount; ++i) {
DruidConnectionHolder connection = connections[i];
if ((onFatalError || fatalErrorIncrement > 0) && (lastFatalErrorTimeMillis > connection.connectTimeMillis)) {
keepAliveConnections[keepAliveCount++] = connection;
continue;
}
if (checkTime) {
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - connection.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
continue;
}
}
long idleMillis = currentTimeMillis - connection.lastActiveTimeMillis;
if (idleMillis < minEvictableIdleTimeMillis
&& idleMillis < keepAliveBetweenTimeMillis
) {
break;
}
if (idleMillis >= minEvictableIdleTimeMillis) {
if (checkTime && i < checkCount) {
// 当前数据库连接数 > 最小连接池数量 并且 连接空闲时长 > 最小空闲时间
evictConnections[evictCount++] = connection;
continue;
} else if (idleMillis > maxEvictableIdleTimeMillis) {
// 当前数据库连接数 <= 最小连接池数量 并且 连接空闲时长 > 最大空闲时间
evictConnections[evictCount++] = connection;
continue;
}
}
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
}
} else {
if (i < checkCount) {
evictConnections[evictCount++] = connection;
} else {
break;
}
}
}
// 省略
}
看到注释的那段代码,结合druid控制台的连接数监控。果然问题就出现在maxEvictableIdleTimeMillis上面。他在druid的默认大小是7个小时远远高于防火墙的配置。
因为业务QPS并不高,连接数一般都不会高于我们配置的最小连接数,所以我们的连接一般要等到7个小时之后才会被druid关闭,但这期间已经被防火墙杀死了,所以大量业务报超时告警。
解决
知道问题的原因,我们有以下解决方案
1、业务和数据库尽量部署在一起,避免因为网络问题导致的超时
2、联系厂商,调整跨网交换机防火墙的TCP超时时长配置
3、设置数据库连接池的maxEvictableIdleTimeMillis配置,保证maxEvictableIdleTimeMillis小于防火墙的超时时间
















 2980
2980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









