







1、简介
伸展树(Splay Tree)是平衡二叉搜索树的一种形式。
相对于 AVL,伸展树的实现更为简捷。伸展树无需时刻都严格地保持全树的平衡,但却能够在任何足够长的真实操作序列中,保持分摊意义上的高效率。伸展树也不需要对基本的二叉树节点结构,做任何附加的要求或改动,更不需要记录平衡因子或高度之类的额外信息,故适用范围更广。
2、局部性
所谓的“数据局部性”(data locality),包括两个方面的含义:
1)刚刚被访问过的元素,极有可能在不久之后再次被访问到
2)将被访问的某一元素,极有可能就处于不久之前被访问过的某个元素的附近
充分利用好此类特性,即可进一步地提高数据结构和算法的效率。
这里之所以提到这一特性,是因为在伸展树中,我们会利用此特性,即访问过的节点会被放置到树根处,以便于下次访问。
当然了,这一策略与“自调整列表”类似,它就是通过“即用即前移”的启发式策略,将最为常用的数据项集中于列表的前端,从而使得单次操作的时间成本大大降低。
连续的 m 次查找,若采用 AVL 则共需 o(nlogn) 时间;而在伸展树中,我们能在一段时间查找后使得查找更快。接下来就让我们看看伸展树的具体内容吧。
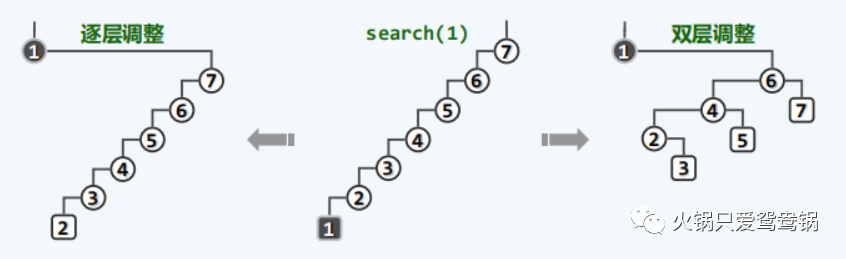
3、逐层伸展
3.1、伸展方式
所谓逐层伸展,即:每访问过一个节点之后,随即反复地以它的父节点为轴,经适当的旋转将其提升一层,直至最终成为树根。
旋转的方式自然是 zig 或 zag 方法。
来看看这个示例图:
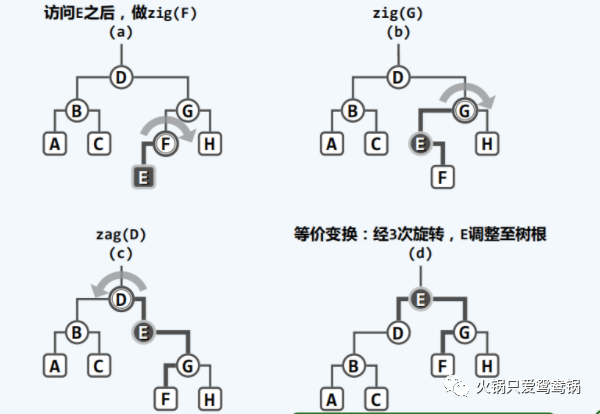
随着节点 E 的逐层上升,两侧子树的结构也不断地调整,故这一过程也形象地称作伸展(splaying),而采用这一调整策略的二叉搜索树也因此得名。
然而,如果仅仅是这样,则会在最坏的情况导致效率十分低下,因此,为实现真正意义上的伸展树,还须对以上策略做点微妙而本质的改进。
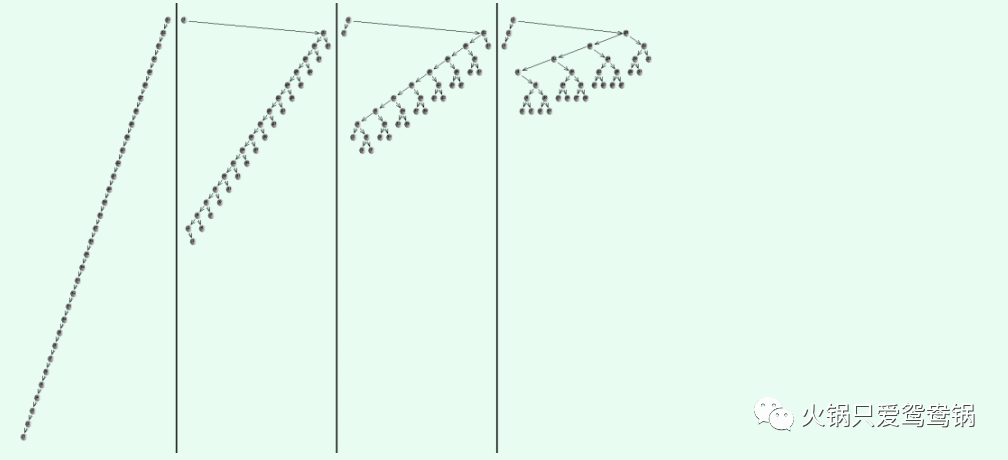
3.2、最坏情况
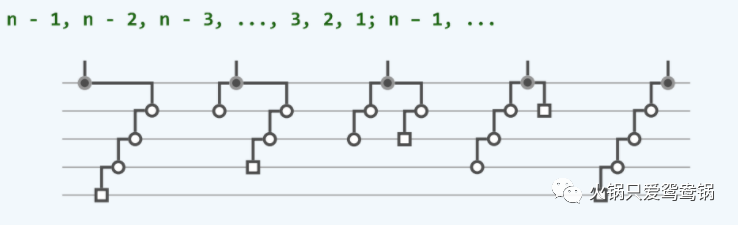
下面来看看逐层伸展的最坏情况:

可以看到,在五次访问之后,树的结构又恢复到了初始结构。当然这一实例,完全可以推广至规模任意的二叉搜索树。于是对于规模为任意n的伸展树,
只要按关键码单调的次序,周期性地反复进行查找,则无论总的访问次数
m >> n 有多大,就分摊意义而言,每次访问都将需要 O(n) 时间!
因此我们需要尽可能的回避这样的最坏情况出现,双层伸展能帮助我们解决这个问题。
4、双层伸展
4.1、双层伸展介绍
首先我们应该明白,最坏情况的问题出在哪里?
1)全树拓扑始终呈单链条结构,等价于一维列表;
2)被访问的节点的深度,呈周期性的算术级数演变,平均为 O(n) 。
为了解决可能会出现的最差情况,下面来看看新的思路:双层伸展
所谓双层伸展,即:每次都从当前节点v向上追溯两层(而不是仅一层),并根据其父亲p以及祖父g的相对位置,进行相应的旋转。
构思的精髓在于:向上追溯两层,而非一层。
反复的考察祖孙三代:g = parent(p), p = parent(v),其中 g 是 p 的父亲,p 是 v 的父亲。
那么接下来就来看看具体的实现思路吧。
4.2、实现思路
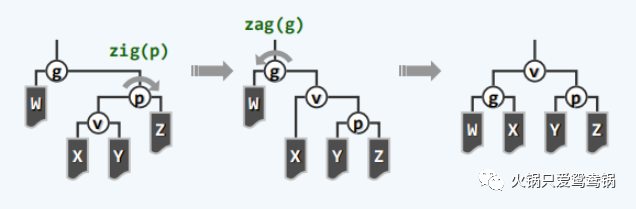
首先需要指明的是:zig - zag 和 zag - zig 的情况。
在 g, p, v 这三代节点中,如果呈现 “之” 字形,则他们的旋转与 AVL 中的双旋完全等效,也就意味着这样的情况下双层伸展与逐层伸展时别无二致。即采用的是一般双旋进行调整。
就像这样,虽然名义上是双层伸展,但是实际上的操作仍然是一般双旋:
实际上:双层伸展主要针对的是 zig - zig 和 zag - zag 的情况,这是因为最坏情况通常出现在一棵树只有左子树或者只有右子树的情况(即呈单链的时)。
来这看看具体的实现:(注意 g,p,v 的祖孙关系)
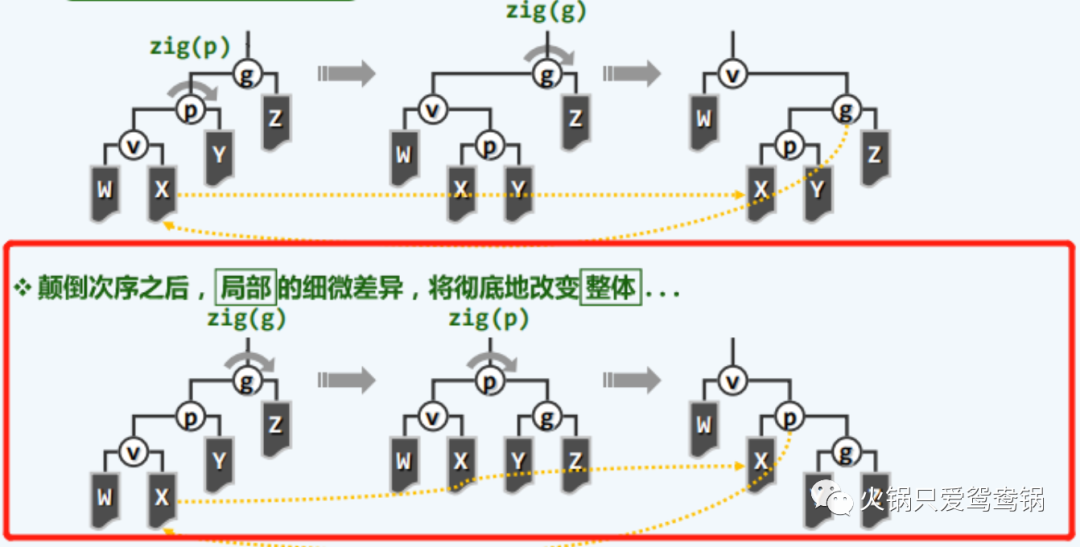
这张图的上半部分采用了一般的双旋,两次旋转首先旋转了“父节点”,然后旋转“祖父节点”。
而下半部分采用了双层伸展策略,即两次的旋转首先旋转的是“祖父节点”,随后旋转“父节点”。
从局部上看好像没有多大的区别,但实际上这些局部的细微差异,会彻底的改变整体情况。
4.3、效果
这样操作的效果,是一旦访问坏节点,对应路径的长度将随即减半。
从而让最坏的情况不至于持续发生!需要注意的是,并不能完全避免最坏情况的发生,只是降低发生概率。
单趟伸展操作,分摊 O(logn) 时间。
看两张示例图:
下面一张的直观效果更明显:
4.4、特殊情况
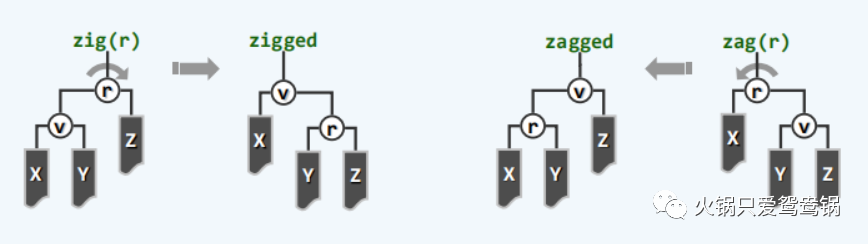
通常我们考虑的是三代祖孙情况,即 g -> p -> v 三者。但如果 v 只有父亲而没有祖父呢?
出现这种情况,则必有 parent(v) == root(T)。即 v 的父亲节点一定是树根节点!
每轮调整中,这种情况至多(且在最后)出现一次!
此时只需要视具体形态,做单词旋转:zig(r) 或 zag(r)。如下图:
5、算法实现
5.1、定义类模板
因为伸展树的查找也会引起整树的结构调整,因此 search 也需要重写。
template <typename T>class Splay: public BST<T> {protected:BinNodePosi(T) splay( BinNodePosi(T) v ); // 核心,将节点V伸展至树根public:BinNodePosi(T) & search( const T & e ); // 查找(重写)BinNodePosi(T) insert( const T & e ); // 插入(重写)bool remove( const T & e ); // 删除(重写)};
5.2、splay 实现
其中 zig 和 zag 的旋转操作,可以在教材查找对应的示例图进行比对。多思考!!!
/*** 注意 attachAsLC 和 attachAsRC 的参数传递位置关系,否则很容易弄混!*/template <typename NodePosi> inline //在节点*p与*lc(可能为空)之间建立父(左)子关系void attachAsLC ( NodePosi lc, NodePosi p ) { p->lc = lc; if ( lc ) lc-> parent = p; }template <typename NodePosi> inline //在节点*p与*rc(可能为空)之间建立父(右)子关系void attachAsRC ( NodePosi p, NodePosi rc ) { p->rc = rc; if ( rc ) rc->parent = p; }template <typename T>BinNodePosi(T) Splay<T>::splay( BinNodePosi(T) v ) {if ( !v ) return NULL; // 如果 V 节点不存在,则直接返回 NULLBinNodePosi(T) p; BinNodePosi(T) g; // 定义父亲,祖父节点// 只要 v,p,g 存在,则自下而上,反复进行双层伸展while ((p = v -> parent) && (g = p -> parent)){BinNodePosi(T) gg = g -> parent; // 保存祖父节点的父亲,每轮之后 v 都以此作为父节点// 根据左右孩子进行区分if ( IsLChild( *v ) ) {if ( IsLChild( *p ) ) { // zig-zigattachAsLC( p->rc, g ); attachAsLC( v->rc , p );attachAsRC ( p, g ); attachAsRC ( v, p );} else { // zig-zagattachAsLC( v->rc, p ); attachAsRC( g, v->lc );attachAsLC( g, v ); attachAsRC( v, p )}} else {if ( IsRChild( *v ) ) { //zag-zagattachAsRC ( g, p->lc ); attachAsRC ( p, v->lc );attachAsLC ( g, p ); attachAsLC ( p, v );} else { //zag-zigattachAsRC ( p, v->lc ); attachAsLC ( v->rc, g );attachAsRC ( v, g ); attachAsLC ( p, v );}}if ( !gg ) { //若*v原先的曾祖父*gg不存在,则*v现在应为树根v->parent = NULL;} else { //否则,*gg此后应该以*v作为左或右孩子( g == gg->lc ) ? attachAsLC ( v, gg ) : attachAsRC ( gg, v );}updateHeight ( g ); updateHeight ( p ); updateHeight ( v );}// 特殊情况:双层伸展结束时,必有 g == NULL,但 p 可能为空if ( p = v -> parent ) {if ( IsLChild( *v ) ) {attachAsLC ( v->rc, p ); attachAsRC ( v, p );} else {attachAsRC ( p, v->lc ); attachAsLC ( p, v );}updateHeight ( p ); updateHeight ( v );}v->parent = NULL;return v; //调整之后新树根应为被伸展的节点,故返回诠节点的位置以便上层函数更新树根}
在有了 splay 这个核心的节点伸展函数之后,下面的功能就会相较于简单的多!
5.3、search 实现
与常规的 BST 中的 search 方法不同,在伸展树中由于涉及到节点的伸展,因此可能会改变树的拓扑结构,因此不再属于静态操作。
template <typename T>BinNodePosi(T) & Splay::search( const T & e ) {/*** 1、利用标准 BST 的内部接口定位到目标节点* 2、根据 searchIn 的算法,成功则定位至目标节点,失败定位于哨兵节点* 3、其中 _hot 节点是目标节点的父节点,失败情况下就是最后被访问的节点*/BinNodePosi(T) p = searchIn(_root, e, _hot = NULL);// 最后被访问的节点都将伸展至根节点处_root = splay( p ? p : _hot ); // 成功,失败// 总是返回根节点return _root;}
5.4、insert 实现
一般情况下,我们可以调用 BST 的插入算法,然后再将新节点伸展至根节点。其中会首先调用 BST:: search() 算法。
然而,在重写的 splay 方法中,已经集成了过 search 方法,因此这样的话未免太过繁琐,下面会给出一种更好的办法。
即直接在树根附近完成新节点的接入:(e大于t->data,在右侧嫁接)
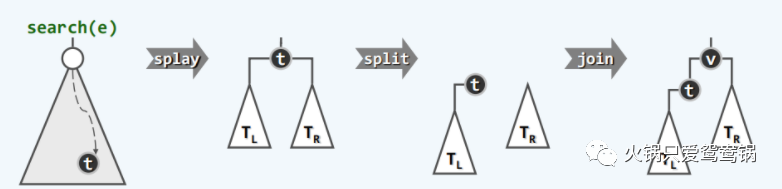
大体步骤:
1)通过伸展树的 search 直接定位到目标节点的父节点 _hot;并且 _hot 会被移动至树根节点处;
2)根据目标节点的大小与 _hot 节点的大小对,对把树拆成两部分,再将目标节点拼接上去;
具体实现:
template <typename T>BinNodePosi(T) Splay::insert ( const T & e ) {if ( !_root ) { // 处理原树为空的情况,直接构建新节点返回即可_size = 1;return new BinNode<T>( e );}BinNodePosi(T) t = search( e );if ( e == t -> data ) { // 如果节点 t 存在,则伸展至跟并直接返回return t;}// 节点插入if ( t -> data < e ) { // 在右侧嫁接t -> parent = _root = new BinNode<T> ( e, NULL, t, t -> rc );if ( t -> rc ) {t -> rc -> parent = _root;t -> lc = NULL;}} else {t -> parent = _root = new BinNode<T> ( e, NULL, t -> lc, t );if ( t -> lc ) {t -> lc -> parent = _root;t -> lc = NULL;}}_size++;updateHeightAbove ( t );return _root; // 更新规模及高度,报告插入成功}
尽管伸展树并不需要记录和维护节点高度,为与其它平衡二叉搜索树的实现保持统一,这里还是对节点的高度做了及时的更新。出于效率的考虑,实际应用中可视情况,省略这类更新。
5.5、remove 实现
同 insert 类似,我们仍然选择在树根附近完成对目标节点的删除!
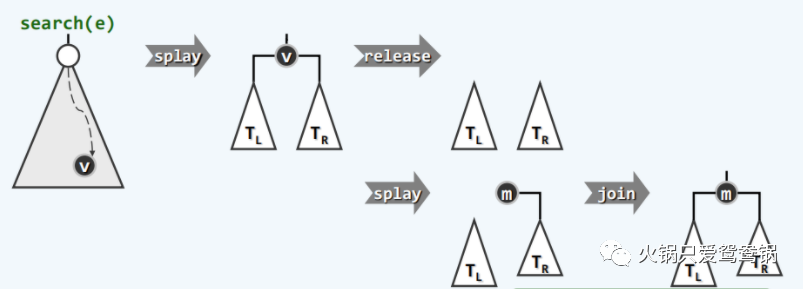
大体步骤:
1)通过伸展树的 search 方法找到目标节点,并将目标节点伸展至树根处;
2)在原右子树中找到最小值,令其作为新的树根节点;这个新的树根节点的值一定小于全部右子树,同时大于全部左子树。
具体实现:
template <typename T>bool Splay::remove ( const T & e ) {if ( !_root ) { // 若树为空,则直接返回 falsereturn false;}if ( e != search ( e ) -> data ) { // 若目标节点不存在,则直接返回 falsereturn false;}// 经过上面的 search 方法,目标节点 e 已经被伸展到树根节点处BinNodePosi(T) L = _root -> lc,R = _root -> rc;release(_root); // 记下左、右子树L、R后,释放根节点,此时就实现了目标节点的删除if ( !R ) {if ( L ) { // 在右子树为空,左子树不为空的情况下,左子树直接就是最新的树l -> parent = NULL;_root = L;}} else { // 右子树不为空_root = R; R -> parent = NULL; // 令右子树为整棵树// 在R中再次查找e:注定失败,但其中的最小节点必伸展至根(且无左孩子),故可令其以L作为左子树search( e );if ( L ) {L -> parent = _root;_root -> lc = L;}}if ( --_size ) updateHeight ( _root );return true; // 更新规模及树高,报告删除成功}
将代码对照着图例理解起来并不难,但是其中有一句注释需要额外注意下:在 R 中再次查找 e:注定失败,但其中的最小节点必伸展至根(且无左孩子),故可令其以L作为左子树。
为什么在 R 中查找 e 后最小节点被伸展至根节点就一定没有左孩子呢?实际上着得益于二叉搜索树的特点:当找到最小孩子后,其在二叉树中一定是最小的值,则其他值都应该存在于该最小节点的右子树上,因此该最小节点一定没有左子树。
同时,如此不仅删除了v,而且既然新树根m在原树中是v的直接后继,故数据局部性也得到了利用!
6、综合评价
6.1、伸展树的优点
在伸展树中,我们无需记录节点高度或平衡因子;编程实现也简单易行 --- 优于 AVL 树。
就复杂度而言,伸展树与 AVL 树相当,都是 O(logn)。
在伸展树中,充分利用了局部性,每一次的搜索操作,都会使得被搜索的目标提前至根,一段时间之后,常用的搜索结果必然会集中于根部附近,从而导致缓存的命中率极高。
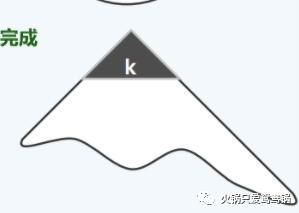
其中 k 区域就是一段时间之后的缓存结果。效率甚至可以更高,达到自适应的 O(logk)。
任何连续的 m 此查找,都可在 O(mlogk + nlogn)的时间内完成!
6.2、伸展树的缺点
前面已经提到,即使伸展树可以降低最坏情况出现的概率,但仍然不能杜绝单次最坏情况的出现。
伸展树不适用于对效率敏感的场合,例如手术操作系统之类的,必须拥有极快的反应速度。
复杂度的分析也稍显复杂。
最后,欢迎大家关注我的微信公众号:火锅只爱鸳鸯锅!















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









