







1、简介
什么是优先级队列呢?我们得首先清楚优先级的概念。
有这样一个例子,在一家医院里面,一开始的时候看病是按照先到先看的顺序,也就是我们前面学到的队列。然后有一天一个身受重伤的病人来了,护士告诉他说你去排队吧,然后还没有等到他排到就不幸去世了。这件事情让医院明白了一个道理,那就是针对不同情况的病人,需要给他们一个不同的级别,例如受重伤的人就应该最先被治疗,而仅仅是轻微感冒这类似的问题则可以稍微延后一点。
这个例子里面的级别也就正对应着我们所说的优先级,优先级最高的则排在最前面。
那么此时你应该大致明白什么是优先级队列了,接下来让我们看看在 C++ 中如何定义优先级队列的结构体定义吧:
template <typename T> struct PQ {
// 按照优先级次序插入词条
virtual void insert(T) = 0;
// 取出优先级最高的词条
virtual T getMax() = 0;
// 删除优先级最高的词条
virtual T delMax() = 0;
}实际上,与其说 PQ 是数据结构,不如说是 ADT;其不同的实现方式,效率及使用场合也各不相同。
我们在前面学到的 栈 和 队列,都是 PQ 的一种特列 --- 它们的优先级完全取决于元素的插入次序
2、基本实现
本小节会实现几种简单的优先级队列。(最大优先级的值以下简称位最大值)
2.1、向量
在向量中,一般在尾端插入,从尾端弹出。
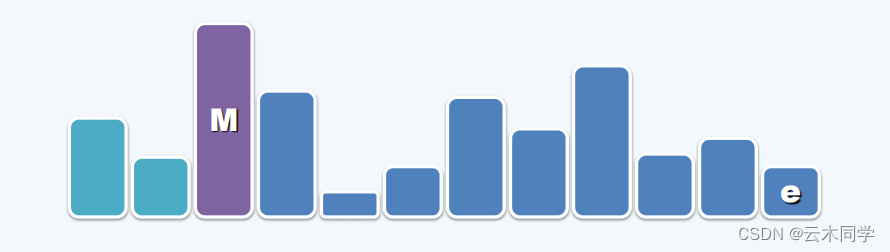
因此其 insert 接口的时间复杂度是 O(1),然而对于 getMax 和 delMax 的效率却难以令人满意,后二者的时间复杂度都会达到 O(n) 。
对于 getMax 而言,需要遍历整个向量,则时间复杂度都会达到 O(n) 。
对于 delMax 而言,首先需要遍历向量找到最大值,在删除之后还需要将刚刚被删除值后面的所有值向左(前)移动一位。这样的话实际的时间复杂度也会达到 O(n) 。
2.2、有序向量

也许你已经想到,既然希望能快速获取到最大值和删除最大值,那么就可以实现一个有序向量啊。
没错,在这样的思路下,getMax 和 delMax 的时间复杂度都达到了 O(1)。然后令人不满意的是 insert 操作,由于需要有序,因此在插入时首先要搜索合适的位置,并将插入位置后的所有元素向右(后)移动一位。这样的操作会让时间复杂度达到 O(n)。
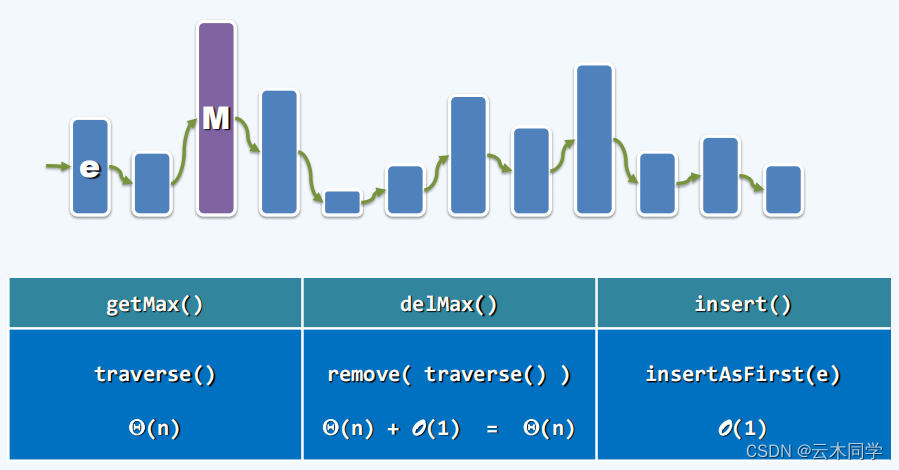
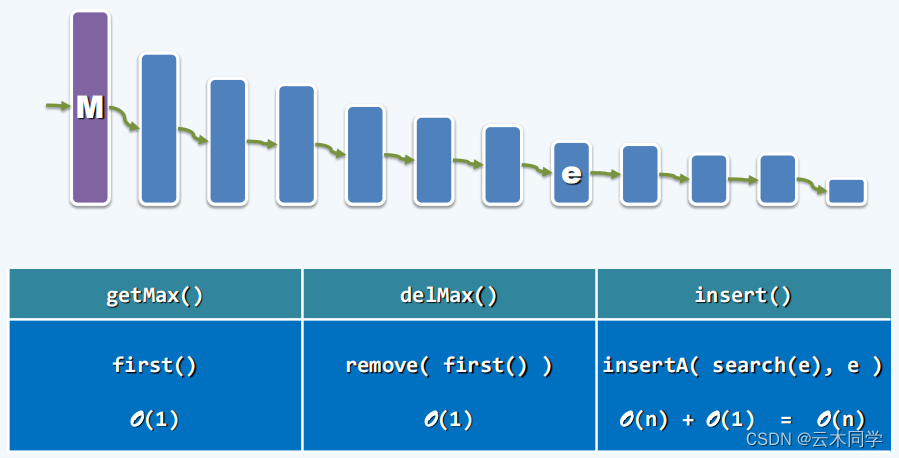
2.3、链表和有序链表
在链表和有序链表中的情况与向量中类似,即总会至少有一个操作的效率无法令我们满意。下面给出对应的图例。
链表:
有序链表:
2.4、BBST
既然前面的四种操作的操作效率都不能让我们满足,那么 BBST 呢?
在 BBST( AVL,Splay,Red-Black ) 中, 其插入,删除,搜索接口均只需要 O(logn) 的时间。
然后,这却会让我们有一种“杀鸡用牛刀”的感觉,BBST 太过强大,远远超出了 PQ 的需求。
在优先级队列中,只需要查找极值,则没有必要维护所有元素的全序关系!
2.5、小结
看了上面五种方案,我们有理由相信存在某种更简单,维护成本更低的数据结构,其时间复杂度依然是 O(logn),且实际的效率更高。
当然,在某些情况下上述的方案并不是毫无用处,我们也需要根据具体情况来选择最适合的实现方案。
3、完全二叉堆
3.1、介绍
根据我们上面的描述,可以清楚的明白“杀鸡无需用牛刀”,因此可以相信某种更合适的数据结构来实现优先级队列。
没错,这就是我们本节的主要介绍内容:完全二叉堆!
完全二叉堆:(结构性)
1)在逻辑上,等同于完全二叉树;
2)在物理上,直接借助向量实现
即在逻辑思路上,完全二叉堆是这样的:
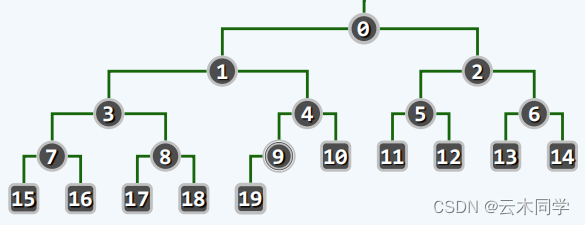
注:图中的数字并不是代表数值,而是代表秩。
在物理实现上,我们借助向量来实现:

注:这样画仅仅是为了表示出树的不同层级,其本质是向量
那么我们如何联系这两种结构呢?
事实上,通过向量的下标(秩)完全可以确定其对应的父,左孩子,右孩子的位置!
例如取某元素下标 i ;
1)若存在父节点,则父节点在向量中的秩为:( i - 1 ) >> 1;
2)若存在左孩子,则左孩子在向量中的秩为:( i ;
3)若存在有孩子,则右孩子在向量中的秩为:( 1 + i ) ;
实例:现在取 i 为 6,按照上述方法,则其父节点秩为 2 ,其左孩子节点秩为 13 ,右孩子节点秩为14 。
由此,结合前面提到的优先级队列的结构体定义和向量,我们可以实现完全二叉堆的模板类:
template <typename T>
class PQ_ComplHeap : public PQ<T>, public Vector<T> {
protected:
Rank percolateDown( Rank n, Rank i ); // 下滤
Rank percolateUp ( Rank i ); // 上滤
void heapify( Rank n ); // Floyd 建堆算法
public:
PQ_ComplHeap( T* A, Rank n ) { // 批量建堆
copyForm( A, 0, n );
heapify( n );
}
void insert( T ); // 按照比较器确定的优先级次序,插入词条
T getMax(); // 读取优先级最高的词条
T delMax(); // 删除优先级最高的词条
};上面有些方法还未提及,不用担心,在后面会一一涉及。
3.2、堆序性
在完全二叉堆中,应该要满足些什么条件呢?
第一个自然是向量本身的结构体不变,第二个就是这里提到的堆序性。
所谓堆序性,即:父节点的优先级 >= 子节点的优先级。
从这个角度看,那么向量的首位元素一定是全局优先级最大的元素,则可以得到 getMax 方法的具体实现为:
/**
* 获取最大优先级的元素
*/
template <typename T>
T PQ_ComplHeap::getMax() {
// _elem 是向量自带的,因为 PQ_ComplHeap 继承了 Vector
return _elem[0];
}3.3、插入
在完全二叉堆中插入一个词条 e,只需要将 e 作为末元素接入向量即可,在这种方式下,其结构性一定是满足的,而堆序性却不一定能满足,因此需要分两种情况:
1)满足堆序性,则插入完成;
2)不满足堆序性,则堆序性被破坏,需要进行处理。
1、修复堆序性
首先明确,是新插入节点 e 违反了堆序性,即 e 的优先级是大于其父节点的,因此只需要互换 e 和其父节点的位置。这个操作我们称为:上滤!
但是交换后的 e 却仍有可能和其新父节点造成堆序性的再一次破坏,幸运的是,我们只需要不断重复刚才的步骤,直至 e 与其父节点满足堆序性,或者 e 到达堆顶(向量的首位)。
来看一个实例,在当前堆中插入新的节点 5 :
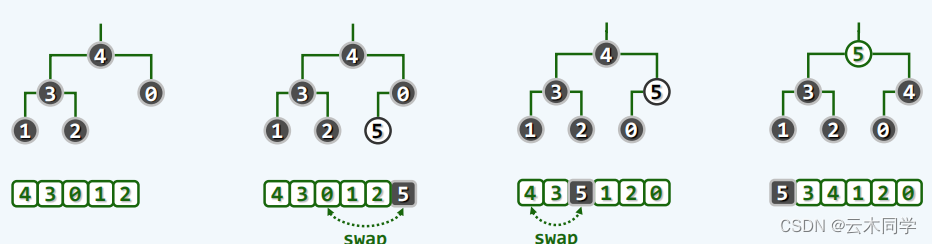
让我们来简单分析一下:
1)插入节点 5 与其父节点 0 的堆序性被破坏,计算得到节点 5 和节点 0 的秩,然后交换其位置;
2)第一次交换后,节点 5 和其新父节点 4 的堆序性被破坏,则按照第一步的方法再次交换;
3)节点 5 到达堆顶,局部堆序性恢复,此时整体的堆序性也满足了。
2、insert 实现:
/**
* 插入元素
*/
template <typename T>
T PQ_ComplHeap::insert( T e ) {
// 借用向量的 insert 方法将 e 插入向量末端
Vector<T>::insert( e );
// 上滤操作,为了修复堆序性
percolateUp( _size - 1 );
}可以看到,在具体的 insert 中,我们物理上只是借用了向量的插入方法,将元素插入尾端。
而按照前面的分析,这种情况有可能发生堆序性被破坏的情况,因此紧接着插入操作的就是上滤操作:percolateUp 。
3、percolateUp 实现
/**
* 上滤
*/
template <typename T>
Rank PQ_ComplHeap::percolateUp( Rank i ) {
// ParentValid 方法用于判断当前节点是否有父节点,若有则进入循环
while ( ParentValid(i) ) {
// Parent 方法用于获取当前节点的父节点的秩
Rank j = Parent( i );
// lt 方法用于比较当前节点与其父节点优先级的大小是否满足堆序性
// 需要注意的是,因为是优先级,所以不能仅用简单的 >, <, = 进行比较
if ( lt( _elem[i], _elem[j] ) ) {
// 若满足堆序性,则直接退出循环
break;
}
// 若不满足堆序性,则交换位置,并更新 i 的位置
swap( _elem[i], _elem[j] );
i = j;
}
// 返回上滤最终抵达的位置
return i;
}依照注释和前面的描述,相信看懂这段代码应该不是问题!
4、效率
e 与其父亲交换,每次只需要 O(1) 的时间,且每次交换 e 都会上升一层。同时需要指明,只有 e 的祖先们才有可能和 e 进行交换。
而即使在最坏的的情况下,这种交换也不过是到达树根,堆是以完全二叉树的形式实现,则必是平衡的,因此 e 的祖先最多也不过 O(logn) 个。
因此,可以得出上滤过程的效率是 O(logn)。
注意:实际上,e 上滤至树根的概率极低,即这种情况出现的可能性很小。
3.4、删除
1、原理
在前面的内容中,我们已经明确一点,即最大优先级的元素一定在堆顶,也就是向量的首位元素,因此要删除最大优先级元素,只需要直接摘除首元素,然后以末元素(e)代之!
然而事情并非这么简单,当我们用末元素代替之后,确实保证了完全二叉堆的结构性没有被破坏,但是堆序性却不一定能保证。
此时新的堆顶元素为 e ,它极有可能不是最大的优先级元素,因此需要把 e 和它最大的那个孩子节点进行交换,从而实现局部的堆序性恢复。(此行为称为下滤)
和插入时的交换类似,这种交换有可能只能满足局部,因此有可能 e 到达新的位置后和其新的孩子节点仍然不满足堆序性,不过无需担心,我们只需要重复这个操作直至 e 成为叶子节点或者某 e 满足堆序性即可。
来看一个具体的实例:
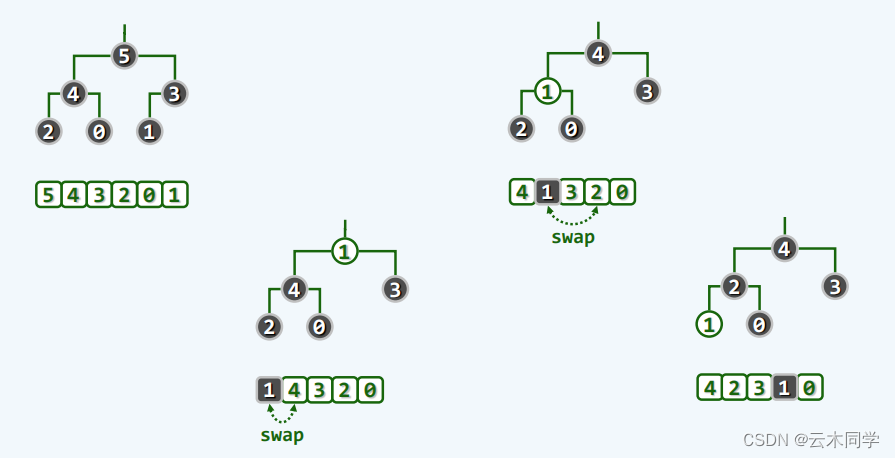
简单分析一下,此时需要删除 5 ,则:
1)直接删除 5 ,并用末尾元素 1 代替;
2)1 和其孩子节点中最大的 4 不满堆序性,因此交换其位置;
3)此时 1 仍然和其孩子节点中最大的 2 不满足堆序性,继续交换;
4)1 到达叶子节点,局部恢复堆序性,此时全局也恢复了堆序性。
2、delete 实现
/**
* 删除最大优先级元素
*/
template <typename T>
T PQ_ComplHeap::delMax() {
// 备份堆顶元素,并用末元素将其取代
T maxEle = _elem[0];
_elem[0] = _elem[--_size];
// 堆序性修复
percolateDown( _size, 0 );
// 返回被删除的最大优先级元素
return maxElem;
}可以看到,物理逻辑上的删除操作并不复杂,配合注释应该很容易理解。
接下来,让我们继续看看下滤方法 percolateDown 的具体实现吧:
/**
* 下滤
*/
template <typename T>
Rank PQ_ComplHeap::percolateDown( Rank n, Rank i ) {
// 申明一个 rank ,用于表明 i 的最大孩子的秩
Rank j;
// ProperParent 用于获取 i 及其孩子中(若存在)最大的秩
// 只要 i != j,则表明 i 不满足堆序性
while ( i != ( j = ProperParent(_elem, n, i) ) ) {
// 交换元素及对应的秩
swap( _elem[i], _elem[j] );
i = j;
}
// 返回下滤抵达的最终位置
return i;
}针对下滤过程的效率,与上滤基本一致,即通过下滤,可以在 O(logn) 的时间内删除堆顶元素,并重新调整为堆!
3.5、建堆
还记得在前面的 PQ_ComplHeap 模板类吗?我们有一个 heapify 方法正是用于建堆的。
然而,一开始的方法就是这样吗,当然不是,下面就一步一步看吧。
1、自上而下的上滤(蛮力法)
有些同学可能会讲,建堆过程只需要不停的调用 insert 接口就好了啊。毫无疑问的是该方法时一定可行的,但是其时间的效率却远远低于我们的与其以至于我们不能接受。省略具体推导,若想要完成 n 个词条的建堆,则累计消耗的时间量可达到 O(n*logn)。这一效率实在是太糟糕了!
因为不可取,所以我们无需考虑该种方法的具体实现。
2、自下而上的下滤( Floyd 建堆算法)
Floyd 建堆算法相比较于前面的蛮力法而言要巧妙很多,我们只需要从最后一个内部节点开始,由下至上的依次进行下滤,就可以实现全树转换为完全二叉堆。
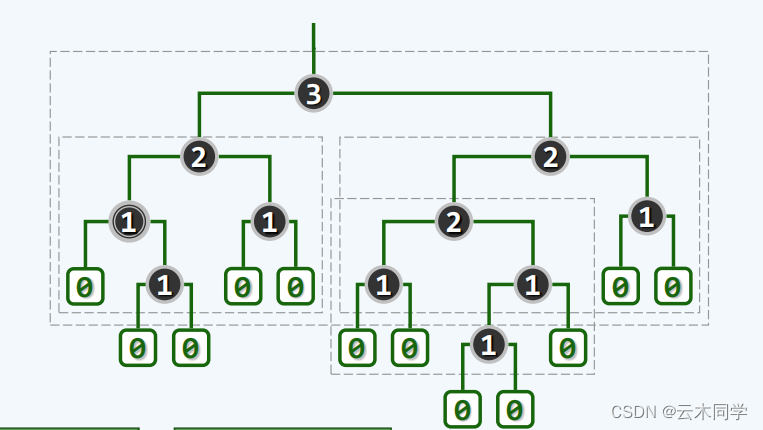
为了让大家能更好的理解,此处我们直接来分析一个实例,下图 (a) 是一个完全二叉树,现在需要将其转换为一个完全二叉堆:
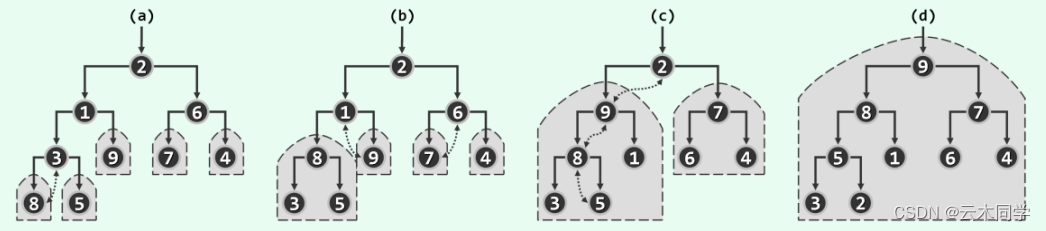
注:图中数字表明优先级大小
1)找到当前树的最后一个内部节点,及优先级为 3 的这个节点,此时对其做下滤,则结果如 (b) 中展示;
2)随后转向倒数第二个内部节点,即 6 这个节点,对其做一次下滤,然后对 1 这个点进行下滤,得到 (c) 这棵树;
3)此时继续向上,即对 2 这个节点进行下滤,最终得到 (d) 中的完全二叉堆。
那么该怎样用代码实现呢:
/**
* 建堆算法
*/
template <typename T>
void PQ_ComplHeap::heapify( Rank n ) {
// 从最后一个内部节点开始进行下滤
for ( int i = LastInternal( n ); i >=0; i-- ) {
// 下滤
percolateDown( n, i );
}
} // 可以理解为子堆的逐层合并 --- 由以上性质,堆序性最终必然在全局恢复省略其具体分析过程,我们可以直接明确该方法的累计时间复杂度为 O(n) 。
4、堆排序
我们在前面的学习中,已经明确一点,即完全二叉堆在物理上就是向量。
因此通过完全二叉堆的方式,我们可以实现堆排序:即通过把向量转换成堆然后再进行排序的行为!
可以看下这个过程图:

将 m(堆顶元素) 与 x 进行互换,此时再对 x 进行下滤,重复此操作以至排序完成!
整体思路是比较简单的,那么现在看看如何用代码实现吧:
/**
* lo 与 hi 即向量中需要排序的范围
*/
template <typename T>
void Vector<T>::heapSort( Rank lo, Rank hi ) {
// 建堆,范围是 lo 到 hi
PQ_ComplHeap<T> H( _elem + lo, hi - lo );
// 反复的摘除最大元并归入已排序的后缀,直至堆空
while ( !H.empty() ) {
/**
* 1、--hi:堆中元素减,获取堆尾部元素
* 2、删除堆顶元素 H.delMax(),返回值为堆顶元素,并做下滤
* 3、这里的 = 不是单纯的赋值,而是交换操作,即将原堆顶元素和
*
* ===> 以上三步等效于堆顶与末元素兑换后再进行下滤
*/
_elem[ --hi ] = H.delMax();
}
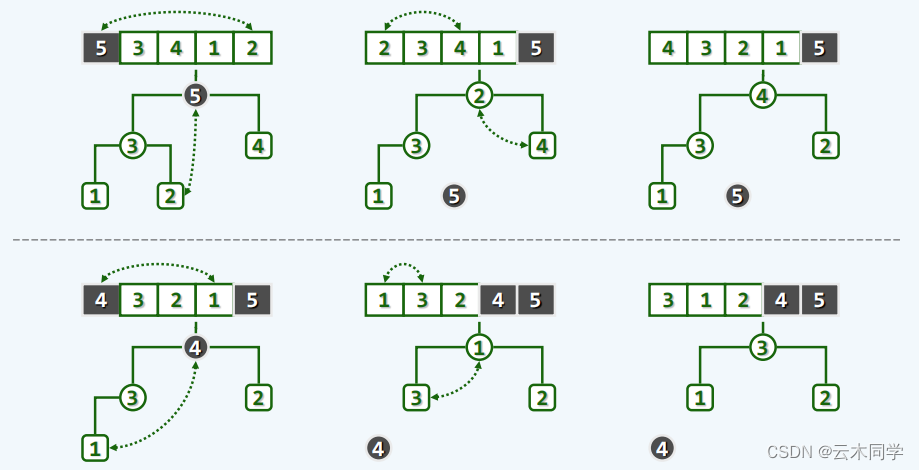
}下面给出一个实例:(已有向量: 4,2,5,1,3 )
1、建堆
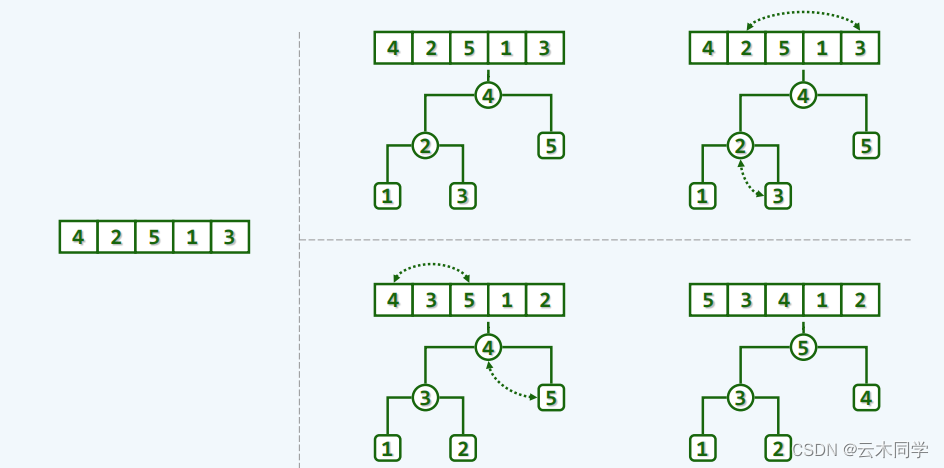
2、排序
堆排序的思路较于理解,并且针对大规模数据也是快速高效的,同时可以就地运转无需额外空间。
5、左氏堆
5.1、前因后果
如何合并两个堆?这是这一节讨论的重点。

方法一:遍历其中一个堆,将其中元素一次插入另一个堆中。
即:A.insert( B.delMax() );
该方法的时间复杂度为:O( M * log( n + m ) )。这样的效率是无法被接受的。
方法二:利用此前的建堆算法,即将两个向量直接合并,然后通过建堆来实现合并。
该方法的效率虽然可以达到线性时间,即 O( m + n ) 。但是还有没有更好的方法呢?
目标是在 O( logn ) 的时间内实现堆的合并!
在上面的描述中,我们期望能有一个更加高效的方法来实现堆的合并。那么现有的以向量为基础的完全二叉堆能支持即将出现的高效方法吗?
答案是不能!
因此我们在这里退出一种新的堆结构:左氏堆
1)仍以完全二叉树为神;
2)与此前不同的是,左氏堆以“二叉树”为神,即以二叉树的数据结构来帮助实现。
在讲解左氏堆之前,还需要提前了解几个要点:
1、单侧倾斜
为了实现满足合并方法的数据结构,我们需要增加新的条件,即“单侧倾斜”,它是指:节点分布偏向于左侧,而合并操作只涉及右侧。
然而在这种情况下,拓扑结构上却不见得是完全二叉树了,那结构性不久无法保证了吗?是的,实际上,结构性也并非堆结构的本质要求。
2、空节点路径长度(npl)
消除一度节点,从而转为真二叉树!
就像下面这样:
那么什么是空节点路径长度呢?
1)npl( NULL ) = 0;
2)npl( x ) = 1 + min( npl( lc(X) ), npl( rc(X) ) )
可以验证:

5.2、左氏堆介绍
左倾:对任何内节点 x ,都有 npl( lc(x) ) > npl( rc(x) )!
[ 推论:对任何内节点 x ,都有 npl( x ) = 1 + npl( rc( x ) ) ]
什么是左氏堆?即满足左倾性的堆就是左氏堆!
由上面可以知道,左氏堆的子堆也必是左氏堆。
下面让我们看看左氏堆的模板,正如前面提到的,左氏堆以二叉树为形:
/**
* 左氏堆的模板类
*/
template <typename T>
class PQ_LeftHeap: public PQ<t>, public BinTree<T> {
public:
// 按比较器确定的优先级次序来插入元素
void insert(T);
// 获取最大元素即获取树根元素
T getMax() {
return _root -> data;
}
// 删除优先级最高的元素
T delMax();
} // 主要接口,均基于统一的合并操作实现
/**
* 单独的静态合并方法
*/
template <typename T>
static BinNodePosi(T) merge( BinNodePosi(T) a, BinNodePosi(T) b );重点就在于这个 merge 方法!
5.3、merge 思路及实现
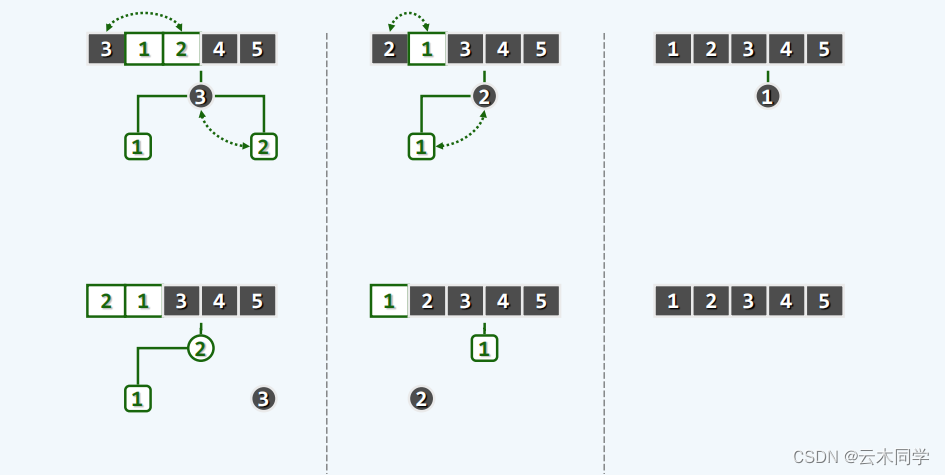
可以看一张图,结合图下的介绍:
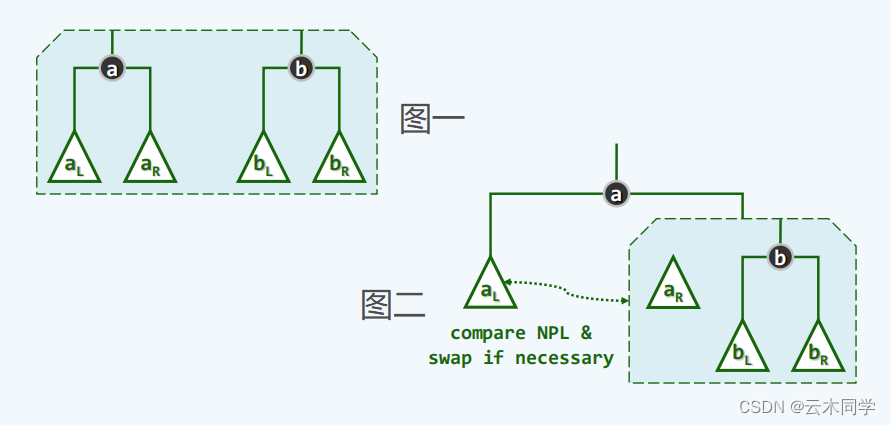
1)在图一中,a 对应两个堆中堆顶节点大的那个,而 b 对应小的,这个顺序不能变;
2)将 a 的右子树与 b 进行合并操作;
3)接下来就是重复此(1)(2)步
来配合一个实例帮助理解:
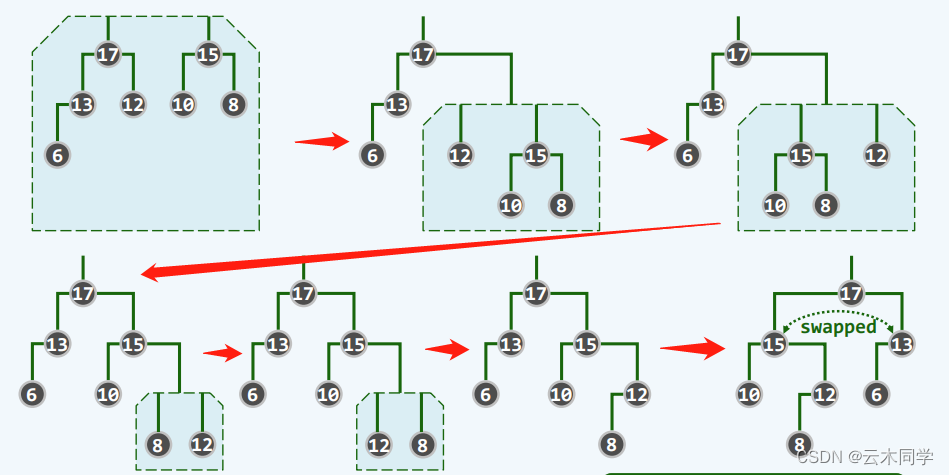
1)17 与 15 之间,17 大则 为 a,15 小则为 b,需要合并 17(a) 的右子树与 15(b) 这棵树;
2)来到 12 和 15,同理,此时 15 为 a ,12 为 b ,则需要合并 15 的右子树 和 12 这棵树;
3)来到 12 和 8,... 后续一样的;
4)当完成了两个堆的合并以后,此时的左倾性不一定能满足;
5)自底向上,一次判断 npl 值,不满足则交换位置保证左倾性。
最后通过代码再一次熟悉这个过程:
/**
* 单独的静态合并方法
*/
template <typename T>
static BinNodePosi(T) merge( BinNodePosi(T) a, BinNodePosi(T) b ) {
// a 堆为空则直接返回 b 即可,b 堆为空则直接返回 a 即可
if ( !a ) return b;
if ( !b ) return a;
// 比较 a、b ,确保 a 的值大于 b(不满足则交换以至满足)
if ( lt( a -> data, b -> data ) ) swap( b, a )
// 合并,递归实现
a -> rc = merge( a -> rc, b );
// 更新父子关系,因为在上面有可能 a,b 交换过
a -> rc -> parent = a;
// 不满足左倾性,则交换 a 的左右子树
if ( !a -> lc || a -> lc -> npl < a -> rc -> npl ) {
swap( a -> lc, a -> rc )
}
// 更新 a 的 npl 值
a -> npl = a -> rc ? a -> rc -> npl + 1 : 1;
// 返回合并后的堆顶元素
return a;
}配合注释,相信你可以更好的理解合并操作。
5.4、插入与删除
左氏堆的插入与删除,其核心仍然是 merge 方法!
1、insert

在左氏堆中插入一个元素,不就是相当于 merge 两个堆嘛,只不过其中有一个堆只有一个元素。
思路很简单,来看看代码实现吧:
/**
* 插入( insert )
*/
template <typename T>
void PQ_LeftHeap<T>::insert( T e ) {
// 为 e 创建一个新的二叉树节点
BinNodePosi(T) v = new BinNode<T>( e );
// 插入操作的本质:合并两个堆
_root = merge( _root, v );
// 更新新的堆顶元素的父子关系
_root -> parent = NULL;
// 更新规模
_size++;
}2、delMax
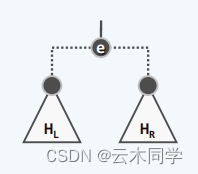
删除方法本质上是 merge 堆顶元素的两个子树!
思路同样很简单,来看看代码实现吧:
/**
* 删除( delMax )
*/
template <typename T>
T PQ_LeftHeap<T>::delMax() {
// 备份左右子堆
BinNodePosi(T) lHeap = _root -> lc; // 左子堆
BinNodePosi(T) rHeap = _root -> rc; // 右子堆
// 备份堆顶的最大元素
T e = _root -> data;
// 删除堆顶元素,更新规模
delete _root;
_size--;
// 删除操作的本质:原左、右子堆合并
_root = merge( lHeap, rHeap );
// 如果根还存在(有可能刚刚删掉的是根),则更新父子关系
if ( _root ) {
_root -> parent = NULL;
}
// 返回被删除的元素
return e;
}以上就是本次的全部内容!
最后,欢迎大家关注我的微信公众号:火锅只爱鸳鸯锅!















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









