









序
- 算是自己看得机器阅读理解的第一个小项目,断断续续看完了,还是有点收获的,所以把自己学的时候的一些资料放上来,其实github上都有,自己只是总结下.
- CDQA: closed-domain QA,闭域的QA系统.
项目官方资料
-
项目github官方:
https://github.com/cdqa-suite/cdQA
-
CDQA——suit
https://github.com/cdqa-suite
-
项目主页:
https://cdqa-suite.github.io/cdQA-website/
-
项目介绍文章:
https://towardsdatascience.com/how-to-create-your-own-question-answering-system-easily-with-python-2ef8abc8eb5
-
项目视频介绍+PPT
https://blog.feedly.com/nlp-breakfast-9-closed-domain-question-answering/
项目特色
- 我们的目标是使内部搜索体验更快、更自然,这得益于使用深度学习技术的自然语言处理的最新进展。cdQA的任务是允许任何人用自然语言提问并得到答案,而不必阅读与该问题相关的内部文档。
- 单纯这么说你可能不懂,上一个图你就懂了:
项目工作流程图
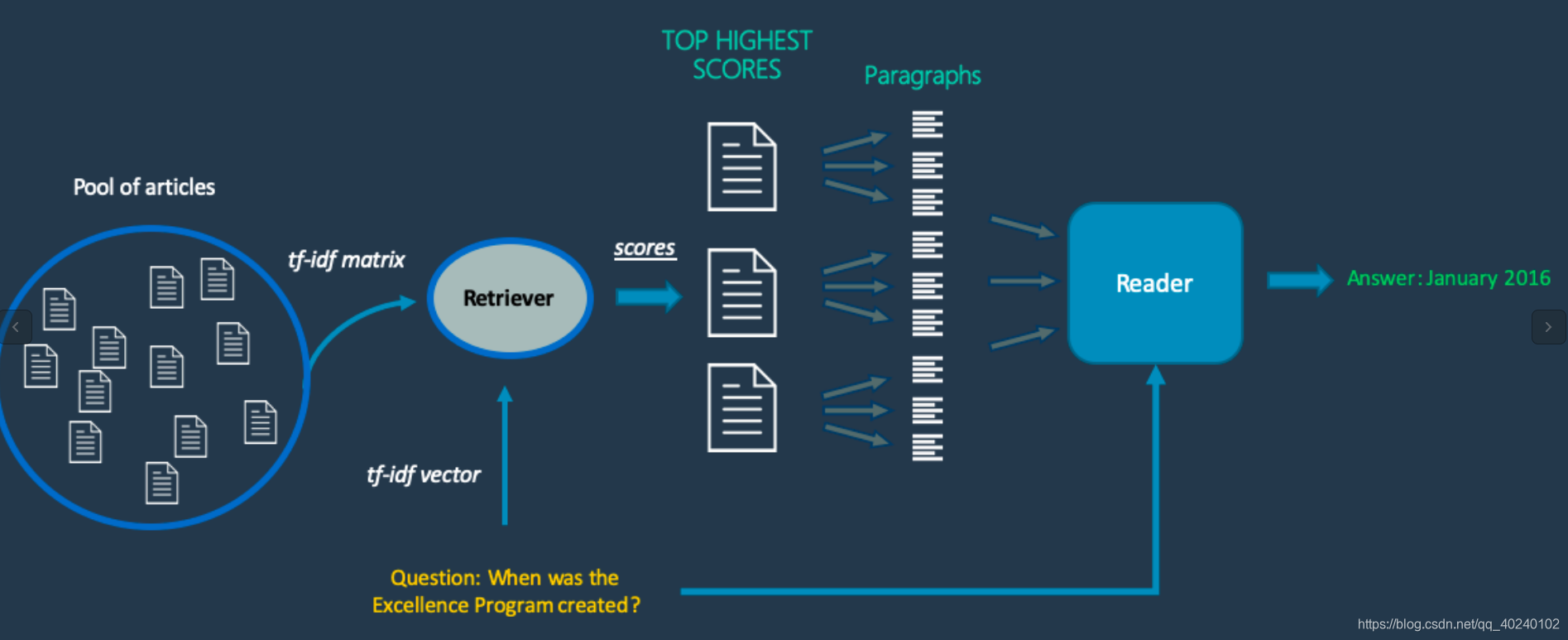
- 具体上面给的资料中,那篇介绍文章有提到,这里粗略说一下:
- 输入一个问题,系统通过retriever从所有文档里找到top n个文档档,把他们转化成对应格式后,传入bert_qa模型,每一篇文档都有一个结果,那怎么评价,代码通过一定的比例加权计算公式,求得最后的评价结果.
CDQA-suit
- The cdQA-suite is comprised of three blocks:
- cdQA: an easy-to-use python package to implement a QA pipeline
- cdQA-annotator: a tool built to facilitate the annotation of question-answering datasets for model evaluation and fine-tuning
- cdqa注释器:为方便注释用于模型评估和微调的问答数据集而构建的工具
- cdQA-ui: a user-interface that can be coupled to any website and can be connected to the back-end system.
- cdQA-ui:可以耦合到任何网站并可以连接到后端系统的用户界面。
- 自己只看了对应的第一个CDQA,后面的暂时没有看,这里只是想让读者对整个项目有一个具体了解.
碎语
- 代码整体设计(不考虑可视化ui和那些),单纯只是CDQA来说,其实不算难,但是里面的工程化操作对人很有启发,自己也稍微写了写文章总结了下,总之稳赚不亏…
- 本人暂时没有去train自己的数据集(因为我没有…)
安装
- 首先这是一个大坑…
- 当你sudo pip install cdqa的时候,他会自动去下载依赖,但是pandas ==0.25.0我一直报错,因为我的python版本不支持,开玩笑,我python绝对不能动,所以我上了docker,但是很多境外源timeout,搞的我烦了,就直接git clone源码下来了,用那个装那个.
快速启动:preditc.py
- 放到你cloen下源码文件夹下
import pandas as pd
from ast import literal_eval
from cdqa.pipeline import QAPipeline
# 这个是你的查找库
df = pd.read_csv('./path-to-directory/bnpp_newsroom-v1.1.csv', converters={'paragraphs': literal_eval})
# 这个是你的模型
cdqa_pipeline = QAPipeline(reader='bert_qa.joblib')
# 指明内存
cdqa_pipeline = cdqa_pipeline.to('cpu')
# 设置好retriever
cdqa_pipeline.fit_retriever(df=df)
# 保存模型
# cdqa_pipeline.dump_reader('test.joblib')
# 预测结果
print(cdqa_pipeline.predict(query="What's your name?"))
End
- 本篇完

















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









