







文章结构
- 导入数据集
- 打开可视化界面显示
- 加载自己的预测
- 数据集评估
- 结果分析
导入数据集
fiftyone支持许多官方数据集,如coco等。这些数据集的加载方式较为简单。可直接使用官方提供的加载方式:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
import numpy as np
import cv2
import json
from collections import defaultdict
# 加载官方数据集coco2017
dataset = foz.load_zoo_dataset(
"coco-2017",
split="validation",
dataset_name="evaluate-detections-tutorial",
)
但是许多时候我们的数据集存在本地,我们需要加载本地的数据集。这时候可以利用另一种方法:
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.COCODetectionDataset,
data_path=image_path,
labels_path=label_path,
)
这里的image_path为你保存图片的路径。而这里的label_path为你的json文件。注:如果是VOC格式的文件也可以使用一些转换脚本。我们可以使用print来打印数据集的信息:

|
打开可视化界面显示
fiftyone的强大功能在于他的可视化。虽然我们也能直接读取出预测结果,然后在图片上进行绘制标签。但每当进行一个新的任务时,我们都需要修修改改,很不方便。fiftyone提供了一个可视化界面给我们直接观看预测结果,而不用自己去一张一张的绘制标签。
session = fo.launch_app() # 打开APP
session.dataset = dataset # 添加数据集

|
我们可以打开每一张图片查看具体信息:

|
加载自己的预测
上述只是将数据集中的标注可视化,没有实际意义。我们需要加入自己的预测进行对比。官网给出的方式为将数据集中的图片读取出送入预测网络中进行端到端的添加。我们这里已经有预测结果了,需要做出一些改变。直接通过image_id字段添加。
image_path = '/home/xx/桌面/boat-voc/JPEGImages/'
labels_path = '/home/xx/桌面/boat-voc/val.json'
predict_path = '/home/xx/桌面/boat-voc/MSMF.json'
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.COCODetectionDataset,
data_path=image_path,
labels_path=labels_path,
)
# val json
with open(labels_path) as f:
val = json.load(f)
# prediction json file
with open(predict_path) as f:
predict_results = json.load(f)
# 建立图片id到预测的映射
id2predict = defaultdict(list)
with fo.ProgressBar() as pb:
print('generate the id2predict')
for result in pb(predict_results):
id2predict[result['image_id']].append(result)
# 建立图像名称到image_info的映射
image2instance = {}
with fo.ProgressBar() as pb:
print('generate the image2id')
for result in pb(val['images']):
image2instance[result['file_name']] = result
# 类别标签
classes = dataset.default_classes
# 需要增加预测的图片
predictions_view = dataset.view()
# 添加预测
with fo.ProgressBar() as pb:
for sample in pb(predictions_view):
image_name = sample['filepath'].split('/')[-1]
image_id = image2instance[image_name]['id']
w, h = image2instance[image_name]['width'], image2instance[image_name]['height']
detections_free = []
for image_result_i in id2predict[image_id]:
# msmf
x1, y1, w1, h1 = image_result_i['bbox']
rel_box = [x1 / w, y1 / h, w1 / w, h1 / h]
detections_free.append(
fo.Detection(
label=classes[image_result_i['category_id']],
bounding_box=rel_box,
confidence=image_result_i['score']
)
)
sample['FREE'] = fo.Detections(detections=detections_free)
sample.save()
print("Finished adding predictions")
session = fo.launch_app() # 打开APP
session.dataset = dataset # 添加数据集
session.view = predictions_view # 添加预测
这次打开APP显示之后,你会发现多了一个在ground_truth旁边多了一个字段。这个字段的名字为FREE即为我们添加的预测。
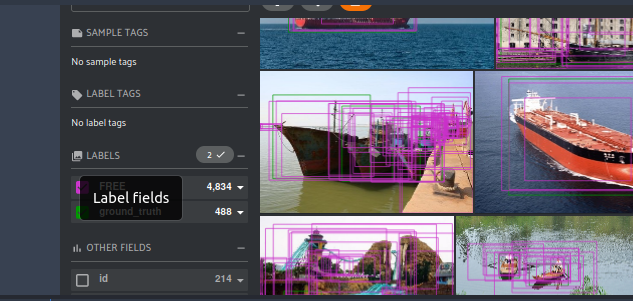

|

|

数据集评估
fiftyone 支持许多独特的数据集评估方式。我们可以按照coco数据集的方式去评估预测。对于上一步我们添加的数据集来说我们可以直接使用下面的代码进行评估:
results_FREE = predictions_view.evaluate_detections(
"FREE",
gt_field="ground_truth",
eval_key="eval_free",
compute_mAP=True,
)
FREE为需要评估的预测,gt_field为真值标签。这里的具体值对应我们我们的设置。比如我们在添加预测时使用了这一行代码sample['FREE'] = ......。这说明我们将预测添加后命名为FREE。如果自己不确定名字也可以打开APP查看名字。
得到了评估结果后我们可以根据我们的需求进行查看。在这里实现几个评估:
- 实现基本的mAP计算。直接打印结果即可:
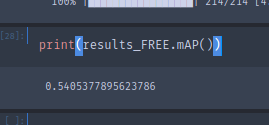
- 打印每一类别详细的报告(左),和只打印具体类别的报告(右):

|

|
- 显示PR曲线。和打印类别报告类似,我们也可以通过classes控制显示的类别:

|

|
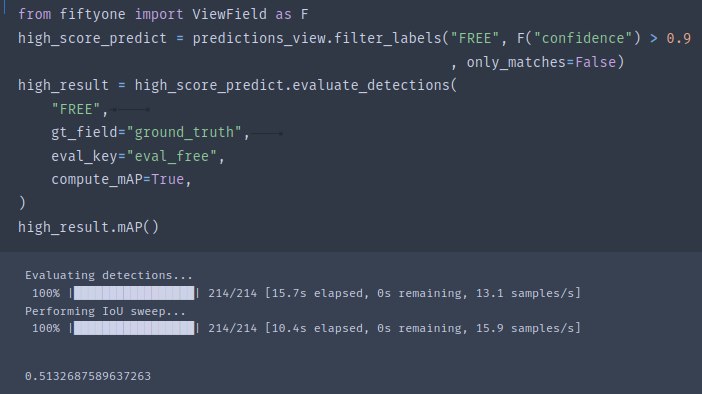
score_thr = 0.5
high_score_predict = predictions_view.filter_labels("FREE", F("confidence") > score_thr)
high_result = high_score_predict.evaluate_detections(
"FREE",
gt_field="ground_truth",
eval_key="eval_free",
compute_mAP=True,
)
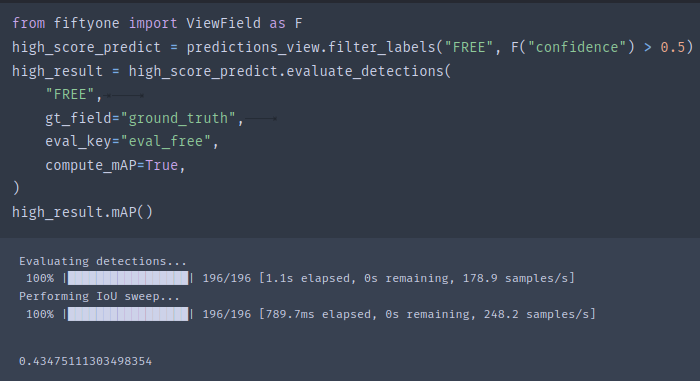
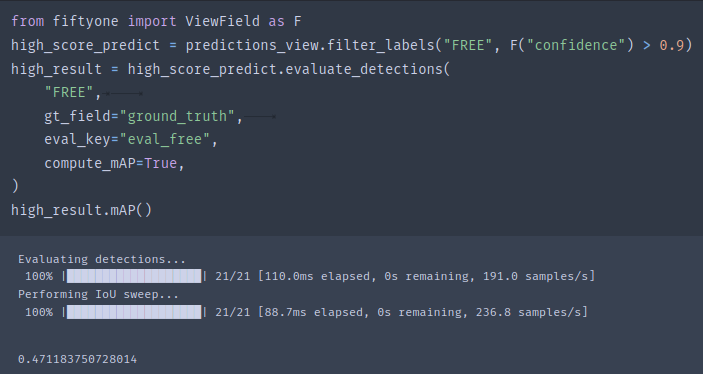
错误修订:事实上,官方给的样例是存在问题的。但是fiftyone是支持按照不同阈值来评估mAP的。不过我们需要添加一些参数:
结果分析
样本级别的分析
fiftyone 提供了样本级别的分析。在评估后,再一次打开APP界面你会发现多了三个字段TP,FP,FN分别对应了True Positive, False Positive,False Negative。再次打开app之后会出现这几个字段:

# 按照表现最好的样本排序
session.view = high_score_predict.sort_by('eval_free_tp',reverse=True) # 这里是以0.5为阈值的结果
# 按照表现最差的样本排序
session.view = high_score_predict.sort_by('eval_free_fp',reverse=True) # 这
小目标样本分析
在上诉的view视图中,我们仅仅按照分数大于某个阈值的的条件进行过滤。事实上,view能够完成更多复杂的操作,比如按照区域的大小来过滤。在coco数据集中像素数量少于 3 2 2 32^2 322的作为小样本。在这里我们采用同样的条件过滤:
# 计算,使得我们可以利用图像的宽度,和高
dataset.compute_metadata()
# 这里面的数据构建方式为[left-top-x, left-top-y, normalize-h, normalize-w]
# 使用width*normalize-h, high*normalize-w恢复原来的区域大小.
bbox_area = (
F("$metadata.width") * F("bounding_box")[2] *
F("$metadata.height") * F("bounding_box")[3]
)
small_boxes = bbox_area < 32 ** 2
# 注意这里没有only_matches没有使用false。也就是仅仅保留含有预测的图像
small_boxes_view = dataset.filter_labels("FREE", small_boxes)
session.view = small_boxes_view
得到了这个view之后,我们可以利用之前介绍的方法去进行评估和可视化。















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









