







八股
-
C++中传引用和传指针的区别:参考
- 指针传参:
- 本质是值传递,形参的指针变量是个临时局部变量,用来接收外部实参指针变量保存的地址值
- 除了解引用对地址内存进行操作外,形参指针变量的其他任何操作都不会影响到外面的实参指针
- 可以修改形参指针指向,不会影响到实参指针的指向
- 可以传空指针
- 引用传参:
- 本质是引用传递,传进入的相当于就是实参本身,会在函数中开辟内存存放,引用参数本身和外面的变量不是独立的,会相互影响;
- 对形参的任何操作都会影响到实参,不存在解引用的情况
- 不能传空引用
- 指针和引用都是传地址,比一般的值传递效率都要高点,但是引用相当于和实参捆绑,指针在中途可以改变指向
- 指针传参:
-
一个函数什么时候返回引用,什么时候返回指针
- C++三种传递方式:值传递,指针传递,引用传递
- 返回的指针和引用区别不大,主要是看返回值的类型,如果类型是值的形式是会产生副本的????晕,需要改
- 需要注意的是,不能返回临时对象的指针或者引用,因为对应的地址,在栈帧回退的时候就不能使用了,
-
什么是野指针,如何避免野指针
- 没有进行初始化的指针,指向未知的内存空间
- 如何避免:在顶一个指针变量的时候,进行初始化,删除一个指针指向的堆地址的时候,进行指控,也可以通过智能指针进行管理裸指针进行避免
-
智能指针有哪些?为什么时候需要用到
weak_ptr?- 有
auto_ptr、unique_ptr、shared_ptr、weak_ptr,其中后面三个是C++11新引入的 auto_ptr、unique_ptr是独占式的智能指针,不带引用计数,资源只能由一个智能指针对象进行管理,shared_ptr、weak_ptr是共享式,带引用计数的智能指针weak_ptr主要搭配shared_ptr一起使用,用来观察shared_ptr管理的资源的生命周期,weak_ptr可以用来避免shared_ptr的循环引用问题
- 有
-
C++有哪些方式实现多态?
- 静态多态和动态多态,静态多态是编译时期的多态,分别有函数重载,和模板特别化
- 动态多态,指的是在继承关系种,子类重复父类虚函数,在运行时期实现的接口复用的多态
-
运行时多态涉及的函数绑定是在什么时期发生的
- 绑定分为静态绑定和动态绑定,静态绑定针对的是非虚函数,在编译阶段确定调用的具体函数
- 动态绑定,一般是通过父类指针指向子类对象实现的,由于在编译阶段不确定具体调用的函数,因为子类会重写父类虚函数,在运行时期,父类指针通过虚函数指针,访问虚函数表,如果子类重写了父类的虚函数,在对应位置调用的就是子类虚函数的地址,如果没有重写调用的就是父类的虚函数
-
多继承情况下,子类继承多个父类,父类都有虚函数,子类同时改写了多个父类虚函数,这种情况,子类的内存布局
class Base1 { public: virtual void func1(){} int a; } class Base2 { public: virtual void func2(){} int b; } class Son:public Base1,public Base2 { public: void func1(){cout<<"Son::func1"<<endl;} void func2(){cout<<"Son::func2"<<endl;} int c; } int main() { Son s; /* s的内存布局 Base1:: vfptr a Base2:: vfptr b c */ return 0; } -
多继承中,菱形继承的问题,如何处理二义性的字段
- B继承A,C继承A,D继承B和C,D中可能有多个A的成员变量,可以通过虚继承解决,让虚基类最优先构造
- 内存布局:
#include<iostream> using namespace std; class A { public: A() { cout << "A" << endl; } virtual void func(){} private: int aa; }; class test1 : virtual public A { public: test1() { cout << "test1" << endl; } int a; virtual void func1(){} }; class test2 : virtual public A { public: test2() { cout << "test2" << endl; } int b; virtual void func2(){} }; class derive2 :public test1, public test2 { public: derive2() { cout << "derive2" << endl; } private: int c; void func1(){} void func2(){} virtual void func3(){} }; // 上面代码需要注意的是,由于是多继承,所以会有多个虚函数指针 // 如果不是多继承,则只会有一个虚函数指针,相当于,子类和父类的指针合在一起 // 并且虚函数表合并,虚函数表中虚函数的位置是根据函数出现的先后顺序决定的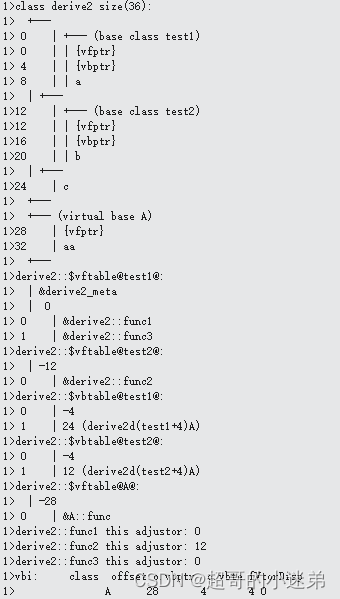
-
STL map中有两种,一种是map,一种是unorderd_map
unorderd_map和map之间的区别:unorderd_map: 底层数据结构是hashtable,是无序的,增删查的时间复杂度O(1)map:底层数据结构是红黑树,中序有序,增删查的时间复杂度O(log n)
unorderd_map的hash结构是如何实现hash算法的?- 无序映射表,底层是用一个
vector维护bucket桶的数据结构,vector的每个元素都是一个bucket,可以说是链表,因为是通过开链法解决hash冲突的,unorderd_map每插入一个元素,都先是根据key计算hashcode,再根据hashcode将对应的节点插到对应的bucket链表中
- 无序映射表,底层是用一个
- hash表是如何扩容的
- 有个负载因子和最大负载因子,其中负载因子是当前元素个数个底层bucket个数比,
当负载因子>=最大负载因子就会发生rehash,也就是扩容再重入插入,主要是防止同一个bucket上元素太多导致索引效率下降 - VS中,底层vector默认的
bucket个数是8,每次发送扩容的时候以8的倍数进行扩容,即扩容一次bucket个数为64
- 有个负载因子和最大负载因子,其中负载因子是当前元素个数个底层bucket个数比,
-
C++中动态库和静态库的区别
- 静态库: 运行时确认地址
- 动态库: 编译时确认地址
-
string类的大小问题:string内存布局
- VS x86系统下,
sizeof(string)=28,x64体系下sizeof(string)=40 - x86下为28的原因:
- 4字节Allocator + 4字节Size + 4字节Capacitry + 16个字节原始字符串大小
- 16个字节原始字符串大小:1字节结束符
'\0'+ 最大可以存储15个字节的 - 当字符长度<=15的时候,就保存在15原始字节里面(和string对应可能一起在栈上),如果>15就保存在堆上,指向堆内存的指针存放到15字节前4字节
- TIP:
- 不同编译器
string底层成员可能不一样,即不同编译器sizeof出来的结果可能不同,但是sizeof string大小是固定不变的 sizeof:是操作符,不是函数,返回对象或者类型的占用的字节数,sizeof详解
- 不同编译器
- VS x86系统下,
-
C++内存对齐的原则
-
提高cpu读取效率
-
例子展示:
class A//8字节 { public: char a; char b;//padding2 int c; } class B //12字节 { public: char a; //padding 3 int b; char c;//padding 3 }
-
-
STL是怎么做内存管理的,allocator分配器的原理,空间配置器:参考
- 将构造对象和内存开辟分开:
- C++中一般
new是先开辟内存再构造对象,delete是先析构对象再释放内存,STL为了防止模板元素是对象的时候,开辟空间有没有意义的对象构造和对象析构,所以就将new和delete的功能进行分割 - 内存配置操作由
alloccate()负责,内存释放由deallcate()负责;对象构造由construct()负责,对象析构则由destroy()负责。
- C++中一般
- 考虑内存分配过程存在的问题,
小块内存导致的碎片问题和小块内存频繁申请释放的问题,所以有了一级配置器和二级配置器的内存分配策略:- 一级配置器:直接使用
malloc(),free(),realloc()等C函数执行内存配置、释放、重配置操作。malloc()开辟失败,调用oom_malloc()和oom_realloc()函数是释放内存再开辟,由于开辟释放可能会循环释放内存,如果内存真的不够,就抛出异常bad_alloc; - 二级配置器:分两层,需要判断当前开辟的大小,如果大于128字节,就使用一级配置器,就使用二级配置器,采用的是
内存池+自由链表的管理方式,避免小块内存开辟带来的碎片化,自由链表有16个元素,每个元素都维护一个内存大小的链表,对应的内存大小为8、16、…、128字节,以8的倍数扩充;每次开辟空间,就在对应的free_list拿节点出去。 - 内存释放:如果大于128字节,就调用一级配置器,如果小于128字节就就将内存放回free_list对应的链表中
- 二及配置器内存池和自由链表的使用:
free_list列表中有空余内存:找到相应的free_list拿一个节点,申请的内存不一致,为向上padding到8的倍数,比如申请3,会分配8,如果内存用完了,就会重新放回来free_list列表中没有空余内存,内存池不为空:先检查申请的内存8字节*20的大小在内存池中够不够,够的话就拿一个8字节分配出去,剩下的放入free_list 8字节的链表中;如果不够20个8字节,则全拿了,拿一8字节分配出去,剩下的挂到free_list中;如果连一个8字节都没有,则看下一条;free_list没有空余,内存池也不够:内存池连一个需要的内存块都分配不出来,则调用malloc分配的内存,分配的内存为:所需内存块大小202,拿一半挂到free_list中,剩下一半在内存池中;free_list列表中没有空余,内存池不够,malloc失败:先找大的free_list有没有空间,如果没有,则调用一级配置器,里面有内存不够的循环处理流程,可能会分配出来,可能会抛出异常
- 一级配置器:直接使用
- 空间配置器的问题:
- 二级空间配置中申请的内存不是8的倍数则会浪费空间,比如1字节匹配8字节
- 二级空间配置器中内存池和free_list的内存是堆上的,且挂在free_list上的内存只会在进程结束还给操作系统,所以会导致其他进程可能使用不了这些空闲资源,并且频繁的开辟小内存,最后可能会导致在堆上开辟不出大内存
- 将构造对象和内存开辟分开:
-
计算机中虚拟地址和物理地址是什么
- 一个进程加载进入内存,是不会分配实际的物理地址,只有运行到对应需要的内存时候,就会通过页表将虚拟地址映射到实际的物理地址中
-
设计模式,C++如何实现单例模式
- 拷贝构造和普通构造私有化,只对外提供一个获取唯一实例的static接口函数,这个接口函数,返回的是私有成员中static的静态对象,一般在类内声明类外实现,通过类的作用域访问接口函数获取唯一实例,单例模式一般分为懒汉式和饿汉式,饿汉式是没有调用接口,在编译阶段对象就存在,是线程安全的,懒汉式是第一个调用接口的时候才进行实例化,是线程不安全的
- 手动实现一个
-
TCP和UDP的区别
- UDP有明显的丢包乱序的问题,以UDP的方式来传输,如何解决丢包乱序的问题,如何知道包丢了,如果
-
出于什么目的做自己的项目:
-
多线程如何解决高并发问题: 并发-同时能承载客户端数量(稳定的维护)
- C10k: 1w的并发
- 早期只有select/poll,select每次调用都需要将的fd_set(1024=1k)拷贝到内核中,Poll需要将大量的pllfd数组(没有限制),每次将fd_set和pollfd数组拷贝进内核并拷贝出来,会影响性能。
- 所以普通的select只能解决C10k问题(select管理的fd超过1024性能会急剧下降)
- C1000k:100w并发
- 通过epoll来解决,没有大量的fd拷贝在内核和用户空间中,全存放在底层的红黑树节点上,只会将发送时间的集合进行返回,因此相比select而已不需要每次都拷贝,因此epoll可以使得网IO的数量级达到100w级别
- C10M :1000w并发
- 网络IO并发量的限制,为什么做不到C10M,
- 不是CPU的限制(IO不属于计算密集型),也不是内存大小的限制(完全可以加物理硬件解决),也不是磁盘的问题,也不是文件系统的限制
- 是操作系统层面的限制,第一个是系统调用中断,一个是数据在内核和用户空间的限制,还一个网卡的限制,可以通过用户态协议栈解决前面两种问题,用户态协议栈本身可以解决系统中断的问题,并将网卡数据直接映射到用户空间的协议栈中
- 网络IO并发量的限制,为什么做不到C10M,
- C10k: 1w的并发
-
多线程中,每个连接都需要操作mysql数据库,如何解决IO瓶颈的问题
-
C++构造函数和析构函数可以抛异常吗,参考
- 构造函数可以抛出异常, 当抛出异常的时候,析构函数不会被执行,需要手动释放内部申请的资源
- 析构函数不应该抛出异常,程序可能发生未知错误,可能会莫名其妙的蹦吊,当析构有异常的时候应该是在析构函数内部处理,而不是抛出来
-
SLT优先级队列
- 如何实现:底层是依赖
vector容器实现的大根堆 - 创建大根堆的流程:
- 自顶向下:从第一个数据开始插入建立大根堆,每次插入最多可能都需要维护
O(log n)次,时间复杂度O(nlogn) - 自低向上:假设树存在,从最后一个有孩子节点的节点开始维护堆,时间复杂度
O(n)
- 自顶向下:从第一个数据开始插入建立大根堆,每次插入最多可能都需要维护
- 如何实现:底层是依赖
-
C++11关键字
default: 参考- 前置:如果自己提供了构造函数,编译器不会提供默认的,默认的拷贝构造还是存在的,如果自己只提供了拷贝构造,编译器不会提供默认的构造,也不会提供默认的拷贝构造
- 定义: 可以作用于默认构造函数、拷贝构造函数、复制重载函数、析构函数,提供编译器默认的实现
- 一般对构造函数进行重载,编译器是不会隐式生成默认构造,如果通过默认构造生成对象会报错,所以一般需要重写默认构造,而
default标记重写的默认构造函数,编译器会隐式生成一个版本,在代码层面可以更加的简洁,且编译器生成的版本效率更高,default使得编译器提供的版本和自己重载的默认构造可以共存
-
C++11的移动语义:
std::move:将左值可以转成右值,用于匹配右值拷贝和右值赋值重载,将对象底层管理的堆上的资源进行转移
-
进程间通信有哪些方式:
- socket、信号量、管道、消息队列,共享内存
-
共享内存如何解决消息通信的安全问题,参考
- 共享内存的是进程间共享数据最快的方法,不涉及数据在多个进程间的拷贝问题
- 可以在共享内存中,使用mutex保证通信的进程安全问题,mutex占用的内存必须是共享内存
-
线程安全和可重入的区别:参考
- 线程安全:多线程访问全局或者静态变量需要加锁进行,保证原子性
- 可重入函数:线程被不同的线程调用,结果总是正确的 ,也就是说是线程安全的
-
gdb的基本操作:
- 看当前线程的栈:
bt, - 看其他线程栈:
info threads,threads+线程编号,bt
- 看当前线程的栈:
-
gdb可以给子进程加断点吗,如何加
-
pid_t fork(void): 用于创建一个子进程,调用一次会有两次返回值,在父进程中返回子进程的进程id,在子进程返回0,如果出错就会返回复值,创建的子进程,会复制父进程的代码段、数据段、BSS段、堆栈等所有的用户空间信息,内核中OS会重新申请一个PCB,并用父进程的PCB进行初始化pid_t getpid(): 获取当前进程的pidpid_t getppid():获取当前进程的父进程pid
-
gdb调试多进程:
- 只调试子进程:
set follow-fork-mode child:只调试子进程,可以在进程里面设置断点,然后run
- 多个进程调试:
set detach-on-fork off: 设置off,一个线程暂停,其他线程也暂停,就可以同时调试多个线程info inferiors:查看进程信息,前提是进程被主进程创建inferiors id:切换进程,加断点可以切换进程加断点- 其他操作和线程一样
- 只调试子进程:
-
调试正在运行的子进程
attach pid:就会切换这个进程,然后可以通过gdb进行调试,前提要知道进程pid
-
-
centos如何管理软件包:参考
- 软件包管理:堆linux下的软件及安装包进行管理,比如下载、安装、卸载、删除等操作
- centos软件包管理工具有两种:
rpm和yum yum命令:- 安装包:
yum -y install 包名 - 列出所有可按转的软件包:
yum list - 列出所有可更新的软件包:
yum list updates - 列出所有已经安装的软件包:
yum list installed - 查找包:
yum search 包关键字 - 移除包:
yum remove 安装包/关键字
- 安装包:
-
linux给定一个文本,有两列,每列通过空格分割,如何将第二列提取出来,用shell命令实现,有时间再看
-
死锁产生的条件:
- 互斥条件:一个公共资源同时时刻只能给一个进程/线程使用
- 不可剥夺条件:进程/线程把资源使用完之前,其他进程/线程拿不到
- 请求和保持条件:进程/线程申请新资源的同时保留已申请的资源
- 循环等待:存在进程/线程A等待进程/线程B的资源,反之亦然,形成了一个等待环路
- 预防死锁:破坏后面三个条件,但是互斥条件是保证进程/线程同步的基础不能去破坏
- 避免死锁:动态检查等待资源的进程/线程资源状态,如果分配后不会死锁就分配,会的花就释放它的资源
-
C和C++的区别:
- C++面向对象,C面向过程
- C++有函数重载,C没有
- C++是new/delete,C是malloc和free
- C++有引用,C没有引用















 3446
3446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









