






1、内部表建表时指定表中字段分隔符
create table t_order(id int,name string…)
row format delimited
fields terminated by ‘,’;
2、外部表的建立
create external table t_job(id int,name string…)
row format delimited
fields terminated by ‘,’
location ‘/user/mytables’;
3、分区表(注意这里的分区条件和字段无关)
/user/hive/warehouse/t_pv_log/day=2019-1-29
/day=2019-1-30
…
在一个表目录下还可以建立其他子目录用以分区,具体按照什么来分去看实际场景
/user/hive/warehouse/t_consume_log/city=Beijing/
/city=Shanghai/
…
create table t_pv_log(ip string,url string,commit_time string)
partitioned by(day string)
row format delimited
fields terninated by ‘,’;
为了不用每次暴力地将文件丢在hdfs目录中去在hive中使用以下语句导入本地文件:
load data local inpath ‘/root/hivetest/xxx.day.29’ into table t_xxx_xxx partition(day=20190129); day---->不一定要是表中的字段
load data local inpath ‘/root/hivetest/xxx/day.30’ into table t_xxx_xxx partition(day=20190130);
不过在表中会多出一个分区字段(伪字段),例如:
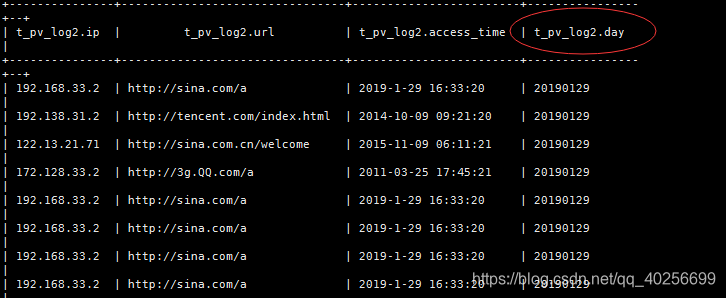
所以注意:分区字段不能是表定义中已存在的字段,可以用来作为查询条件
select count(1)
from t_pv_log
where url=‘http://sina.com/a’ and day=‘20190129’; —>这是查找某个分区中的数据
select count(1)
from t_pv_loh
where url=‘http://sina.com/a’; —>查询整个表中数据
4、CTAS建表
a、要建立与已有表相同的结构的一张新表可以使用一下语法
create table t_pv_log3 like t_pv_log;
这里的字段包括和t_pv_log中的所有字段n-1 加上1个伪字段
b、要建立与已有表相同的结构的表并且新表中存在数据,且数据来自于旧表的一部分
create table t_pv_log4
as
select * from t_pv_log2 where ip>‘192.168.33,2’;
这里的字段包括和t_pv_log2中的所有字段,n个字段都是普通字段。
but:如果是这样
create table t_pv_log4
as select ip from t_pv_log2;
这样的话新表中只会有一个字段(ip字段)
5、将数据文件导入hive表中
a、手动用hdfs命令,将文件放入指定表目录下;
b、在hive的交互式shell中用hive命令来导入本地数据到表目录(复制)
hive>load data local inpath ‘/root/order.data.2’ into table t_order [patition() …]
c、用hive命令导入hdfs中的数据文件到表目录(移动)
hive>load data inpath ‘/access.log.2019-01-29.log’ into table t_access partition(dt=‘20190129’);
5、hive条件查询
基本查询示例:
select * from t_access;
select count(*) from t_access;
select max(ip) from t_access;
…
6、hive连接查询
先准备两个表
create table t_a(name string,numb int)
row format delimited
fields terminated by ‘,’;
create table t_b(name string,nick string)
row format delimited
fields terminated by ‘,’;
load data local inpath ‘/root/hivetest/a.txt’ into table t_a;
load data local inpath ‘/root/hivetest/b.txt’ into table t_b;
各类join
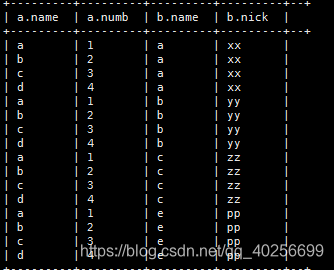
(1)、内连接/笛卡尔积(可以不要inner)
select a.,b.
from t_a as a inner join t_b as b;
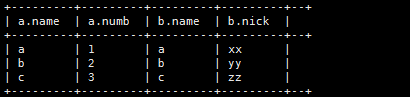
(2)、指定join条件(属于内连接,可以不要inner)
select a.,b.
from t_a as a inner join t_b as b on a.name=b.name;
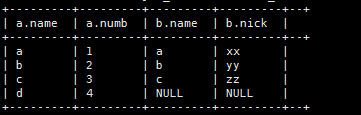
(3)、左外连接(左连接,可以不要outer)
select a.,b.
from
t_a as a left outer join t_b as b on a.name=b.name;
(4)、右外连接(右连接,可以不要outer)
select a.,b.
from
t_a as a right outer join t_b as b on a.name=b.name;
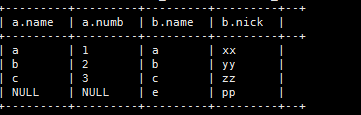
(5)、全外连接
select a.,b**
from
t_a as a full outer join t_b as b on a.name=b.name;
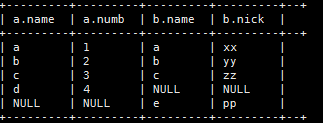
(6)、左半连接(左表全部返回,右表不返回)
这样会报错哦!
select a.,b.*
from
t_a as a left semi join t_b as b on a.name=b.name;

select a.*
from
t_a as a left semi join t_b as b on a.name=b.name;
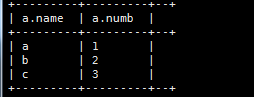
7、hive分组聚合
(1)、针对每一行进行运算 --该表达式是对数据中的每一行进行逐行运算
select ip,upper(url),access_time
from
t_pv_log;
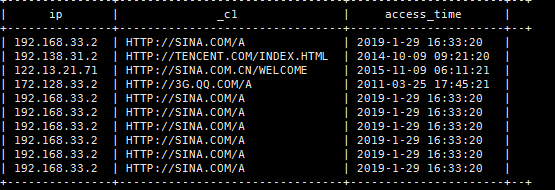
(2)、求每条URL的访问总次数 --该表达式是对分好组的数据进行逐组运算
select url,count(1) as cnts
from
t_pv_log
group by url;

(3)、求每个URL的访问者中ip地址最大的
select url,max(ip)
from
t_pv_log
group by url;
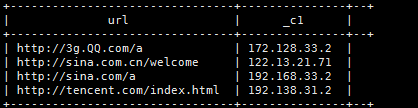
(4)、求每个用户访问同一页面的所有记录中,时间最晚的一条
select ip,url,max(access_time)
from
t_pv_log
group by ip,url;
先按照ip分组,再在分组好的基础上再次按照url分组

(5)、加上分区标志进行聚合
数据
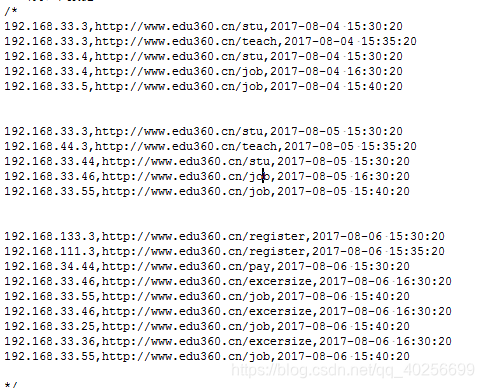
a)、建表映射上面数据
create table t_access(ip string,url string,access_time string)
patitioned by (dt string)
row format delimited
fields terminated by ‘,’;
b)、将数据加入表中并且进行分区
load data local inpath ‘/root/hivetest/access.log.xxxx’ into table t_access partition (dt=xxxx);
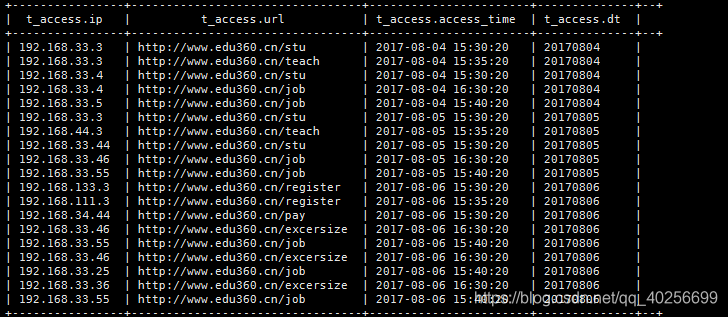
3)、查看表的分区
show partitions t_access;
4)、使用分区聚合语法,求出8月4号以后,每天http://www.baidu.com/job的总访问次数,以及访问者中ip地址最大的
写法a:select dt,‘http://www.baidu.com.cn/job’,count(1),max(ip) as cnt
from
t_access
where url=“http://www.baidu.com.cn/job”
group by dt having dt>‘2017-08-04’;

写法b:select dt,max(url),count(1),max(ip)
from
t_access
where url=‘http://www.edu360.cn/job’
group by dt having dt>‘2017-08-04’;
写法c:select dt,url,count(1),max(ip)
from
t_access
where url=‘http://www.edu360.cn/job’
group by dt,url having dt>‘2017-08-04’;
写法d:select dt,url,count(1),max(ip)
from
t_access
where url=‘http://www.edu360.cn/job’ and dt>‘2017-08-04’
group by dt,url;
8、hive子查询
还是引用7中的数据
(1)、求8月4号以后,每天每个页面的总访问次数,以及访问者中ip地址最大的
select dt,url,count(1),max(ip)
from t_access
where dt>‘2017-08-04’
group by dt,url;
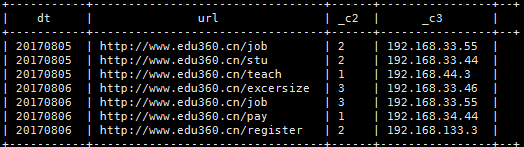
(2)、求8月4号以后,每天每个页面的总访问次数,及访问者中ip地址最大的,且只查询出总访问次数>2的记录
方式1:
select dt,url,count(1) as cnts,max(ip)
from t_access
where dt>‘20170804’
group by dt,url having cnts>2;

方式2:
select dt,url,cnts,max_ip
from
(select dt,url,count(1) as cnts,max(ip) as max_ip
from
t_access
where dt>‘20170804’
group by dt,url) as tmp
where cnts>2;

9、hive中的数据类型
9.1、数字类型
TINYINT(1-byte signed integer,from -128 to 127)
SMALLINT(2-byte signed integer,from -32768 to 32767)
INT/INTEGER(4-byte integer,from -2147483648 to 2147483647)
BIGINT(8-byte signed integer)
FLOAT(4-byte single precision floating point number)
DOUBLE(8-byte double precision floating point number)
示例:
create table t_test(a string,b int, c bigint,d float,e double,f tinyint, g smallint);
9.2、日期时间类型
TIMESTAMP(Note:Only available starting with Hive 0.8.0) ---->时间戳
DATE(Note:Only available starting with Hive 0.12.0)
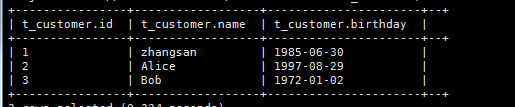
示例,如果有以下数据文件:

9.2.1、那么就可以建一个表来对数据进行映射
create table t_customer(id int,name string,birthday date)
row format delimited
fields terminated by ‘,’;
9.2.2、然后导入数据:
load data local inpath ‘/root/hivetest/customer.dat’ into table t_customer;
9.2.3、然后就可以正确查询;
select * from t_customer;
9.3、字符串类型
STRING
VARCHAR(Note:Only available starting with Hive 0.12.0)
CHAR(Note:Only available starting with Hive 0.13.0)
9.4、混杂类型
BOOLEAN
BINARY(Note:Only available starting with Hive 0.8.0)
9.5、复合类型
9.5.1、array数组类型
arrays:ARRAY<data_type>(Note:negative values and non-constant expression are allowed as of Hive 0.14.0)
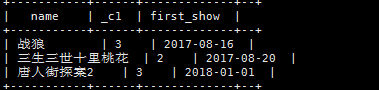
示例:array类型的应用
假如有如下数据需要用hive的表去映射
| 战狼2 |吴京、吴刚、龙母 |2017-08-16
|三生三世十里桃花|刘亦菲、杨洋|2017-08-20
|唐人街探案2|王宝强、刘昊然、肖央|2018-01-01
9.5.1.1、建表
create table t_movie(movie_name string,actors array,first_show date)
row format
delimited fields terminated by ‘,’
collection items terminated by ‘、’;
9.5.1.2、导入数据
load data local inpath ‘/root/hivetest/movie.dat’ into table t_movie;
9.5.1.3、查询
a.查询所有数据
select * from t_movie;

b.查询演员中的第一个
select name,actors[0]
from
t_movie_detail;

c.查询电影中演员包含吴京的
select *
from
t_movie where array_contains(actors,‘吴京’);

d.查询电影中的主演人数
select name,size(actors),first_show
from t_movie_detail;
9.5.2、hive中的map数据类型
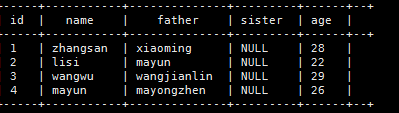
9.5.2.1、假如有如下数据
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
则可以使用一个map类型对上述数据中的家庭成员进行描述
9.5.2.2、建表语句
create table t_person(id int,name string,family_members map<string,string>,age int)
row format
delimited fields terminated by ‘,’
collection items terminated by ‘#’
map keys terminated by ‘:’;
9.5.2.3、导入数据
load data local inpath ‘/root/hivetest/person.dat’ into table t_person;
a.查询所有数据字段
9.5.2.4、查询数据表
select * from t_person; 
a.查出每个人的爸爸,姐妹(没有这个字段显示为NULL)
select id,name,family_members[“father”] as father,family_members[“sister”] as sister,age from t_person;
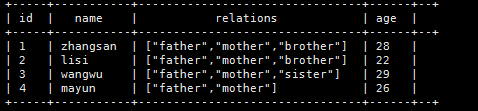
b.查出每个人有哪些亲属关系
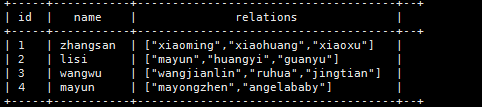
select id,name,map_keys(family_members) as relations,age
from
t_family;
c.查出每个人亲人的名字
select id,name,map_values(family_members) as relations,age from t_person;
d.查出每个人的亲人数量
select id,name,age,size(family_members) as relations
from
t_person;

e.查出所有拥有兄弟的人以及他的兄弟是谁
方案一:一句话写完
select id,name,age,family_members[‘brother’]
from
t_person
where
array_contains(map_keys(family_members),‘brother’); 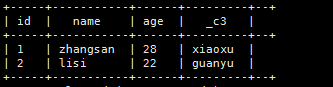
方案二:子查询
select id,name,age,family_members[‘brother’]
from
(select id,name,age,map_keys(family_members) as relations,family_members from t_person) as tmp
where array_contains(relations,‘brother’); 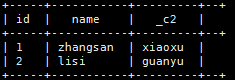
9.5.3、hive中的struct数据类型
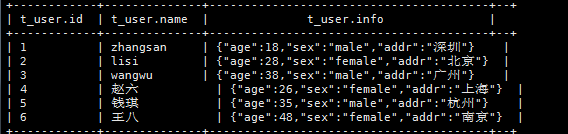
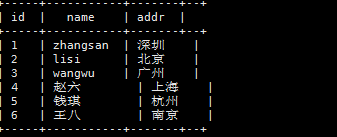
9.5.3.1、数据准备
1,zhangsan,18:male:深圳
2,lisi,28:female:北京
3,wangwu,38:male:广州
4,赵六,26:female:上海
5,钱琪,35:male:杭州
6,王八,48:female:南京
9.5.3.2、建表映射语句
drop table if exists t_user;
create table t_user(id int,name string,info structage:int,sex:string,addr:string)
row format
delimited fields terminated by ‘,’
collection items terminated by ‘:’;
9.5.3.3、加载本地数据
load data local inpath ‘/root/hivetest/user.dat’ into table t_user;
9.5.3.4、查询
a. select * from t_user;
b. 查询每个人的id,name和地址
select id,name,info.addr
from t_user;
10、hive中的函数
10.1、常用内置函数
10.1.1、类型转换函数
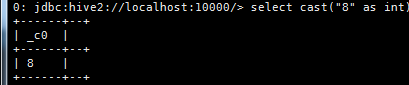
a. create table t_test
as
select cast(“5” as int);
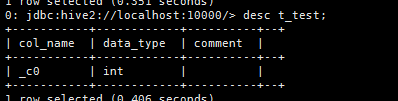
desc t_test;
b. select cast(“2019-02-10” as date); 
c. select cast(curent_timestamp as date); 
10.1.2、数学运算函数
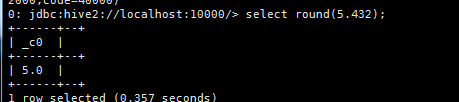
a. 四舍五入round
select round(5.432);
select round(5.4567,2); 
b. 向上取整ceil/ceiling
select ceil(6.1);
select ceiling(6.1);

c. 向下取整floor
select floor(6.9);

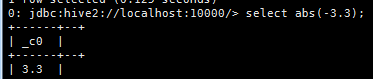
d. 取绝对值
select abs(-3.3);
e. 取几个字段中的最大值,参数必须至少两个
select greatest(1,2,3,5,7,4,4);

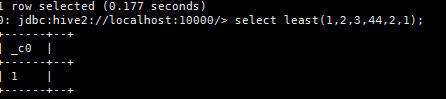
f.取几个字段中的最小值,参数必须至少两个
select least(1,2,3,44,2,1);
案例:如果有表:

select greast(cast(salary1 as double),cast(salary2 as double),cast(salary3 as double)) as mainSalary from t_fun1;
g. select max(age) from t_person; —>聚合函数
h. select min(age) from t_person; —>聚合函数
10.1.3、字符串函数
a. 截取子串 substr(string,int start[,int len]);
select substr(‘abcbdsx’,3);

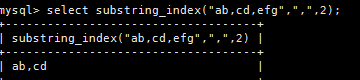
mysql中可以使用:substring_index(string A,string delim,int count);
eg:select substring_index(“ab,cd,efg”,",",2);
b.拼接字符串concat(string A,string B…)
eg:select concat(“ac”,“n”,"?;

拼接并且加上分割符concat_ws(string SEP,string A,string B…)
eg:select concat_ws(",",“a”,“b”,“c”);

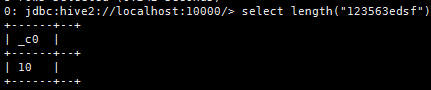
c. 求字符串的长度length(string A);
eg:select length(“123563edsf”);
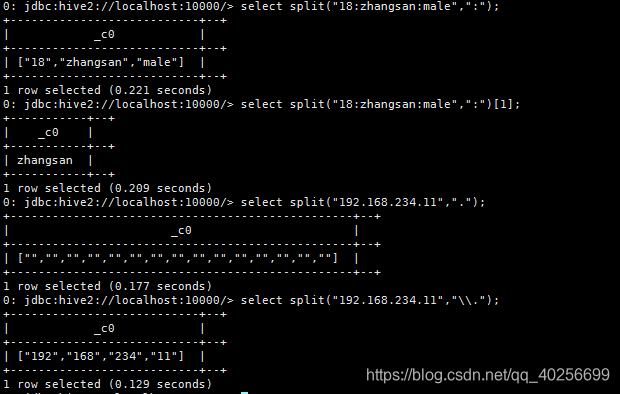
d. 切割字符串split(string str,string pat)
eg:
10.1.4、时间函数
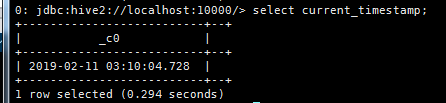
a. select current_timstamp;
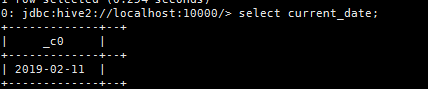
b. select current_date;
c. 取当前时间的毫秒数时间戳
select unix_timstamp(); 
d. unix时间戳转字符串
from_unixtime(bigint unixtime[, string format])
eg: select from_unixtime(unix_timestamp()); 
select from_unixtime(unix_timestamp(),“yyyy/MM/dd HH:mm:ss”);

e. 字符串转unix时间戳
unix_timestamp(string date,string pattern);
eg: select unix_timestamp(“2017-08-29 00:00:00”,“yyyy-MM-dd HH:mm:ss”); 
f. 将字符串转成日期date
eg:select to_date(“2017-09-17” 19:28:20);















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









