







一、requests get中,content和text的区别?
1、requests.get的 content属性返回的是 “字节流,以 b' 开头 ”(编码是不正常的,后面会讲),text就是 正常的字符串(编码是正常的)
2、请看如下的代码运行结果

二、python 爬虫 网页 出现编码问题,字节流,\xcb\xbc\xc4\xee\xbf\xaa\xb7\xe2\xb9\xe0
1、content属性能够获取出来的 是字节流!!如下:
![]()
2、但是 text 属性获取的是 正常的编码,如下:
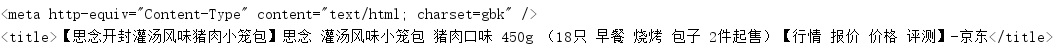
总结:
1、用 requests.get() 方法时候,尽量去通过 text 属性去获取网页的源代码吧,一般不会出现编码问题(编码在 python编程中,个人认为还是蛮不好处理的,我搜索了很多资料,都没找到靠谱的答案。python 2 3编码对比:https://www.jb51.net/article/105518.htm)。
2、不过 requests.get 方法返回的只是网页源码的一部分,目前还在学习、研究中,等研究明白了就往这里写文章哈。不过好像 无头浏览器(selenium)时能获取全部网页源代码的(“js渲染问题吗?欢迎大家留言交流~”)















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









