






1 常见二分类模型的评价指标(均针对测试集)
(1)Accuracy(准确率):总体预测对的比例(不区分正负样本),优点是简单直观,比较适合样本 类别比较均衡 的情况。
(2)Precision(精准率):被预测为正的样本中,有多少为真的,比较适合 错判成本高时 的情况,如癌症预测。
(3)Recall(召回率):实际正样本中有多少被预测出来,比较适合 漏判代价高 时重要,如欺诈识别。
(4)F1-score(F1分数):Precision 和 Recall 的调和平均,权衡精准和召回,在 数据类别不平衡 的时候比较适用。
注:调和平均数:

(5)ROC Curve & AUC(ROC曲线和曲线下的面积):能够表现出模型区分 正、负类 的能力,它是 二分类模型常用 的评价指标,综合性强,视觉直观。
(6)Confusion Matrix(混淆矩阵):各种分类结果的数量分布,可以拆解出所有想看的指标(TP、TN、FP、FN)。
(7)Log Loss(对数损失):概率预测的准确性。
2 案例:基于随机森林算法预测员工是否离职
2.1 数据详情介绍
- 数据维度:(14999, 10)
- 样本数量:14999
- 特征数量:10
[‘turnover’
‘satisfaction’,
‘evaluation’,
‘projectCount’,
‘averageMonthlyHours’,
‘yearsAtCompany’,
‘workAccident’,
‘promotion’,
‘department’,
‘salary’]
其中,turnover 取0或1,0。1表示员工已经离职,0表示员工未离职。
2.2 分类变量进行数字编码
由于 ‘department’ 和 ‘salary’ 是分类变量,因此在数据预处理的时候,我们首先对这两个分类变量进行编码。 见附件附完整代码和数据
#--查看映射关系---
#---将分类变量进行数字编码---
# 部门编码映射表
# 先编码
department_cat = df["department"].astype("category")
df["department"] = department_cat.cat.codes
salary_cat = df["salary"].astype("category")
df["salary"] = salary_cat.cat.codes
department_mapping = dict(enumerate(department_cat.cat.categories))
df_department_map = pd.DataFrame(list(department_mapping.items()), columns=["编码值", "部门"])
print("部门编码表:")
print(df_department_map)
# 薪资编码映射表
salary_mapping = dict(enumerate(salary_cat.cat.categories))
df_salary_map = pd.DataFrame(list(salary_mapping.items()), columns=["编码值", "薪资等级"])
print("\n薪资编码表:")
print(df_salary_map)
分类变量编码结果:

2.2 产生X和y
turnover 就是y(预测变量),其余9个变量则为自变量。
# --- 产生X和y ---
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y = df[target_name]
2.3 训练集和测试集的划分
# --- 划分训练集和测试集 ---
# ---注意参数stratify=y 意味着在产生训练和测试数据的时候,(未)离职员工的百分比等于原来总的数据中的(未)离职员工的百分比
# ---有点类似分层抽样 ---
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.15, random_state=123, stratify=y)
其中,X_test.shape 为 (2250, 9),y_test.shape 为 (2250, 1)。
因为总共有 14999 个样本,test_size=0.15,因此测试集大小为:
14999 × 0.15 = 2249.85 ≈ 2250。
2.5 建立决策树预测模型
2.5.1 配置决策树
我们可以通过设置一些参数来控制决策树的复杂度,从而 限制模型复杂度、防止过拟合。常用的配置包括:
# ---“限制复杂度、防止过拟合”的决策树配置
dtree = tree.DecisionTreeClassifier(
criterion='entropy', #criterion='entropy',指定决策树划分标准,这里用信息增益(信息熵) 来选择最优分裂点(默认是 gini)
# max_depth=3, # (被注释掉)可选,用于限制树的最大深度
min_weight_fraction_leaf=0.01 # 限制每个叶子节点最少占总样本数的1%
)
2.5.2 模型训练
dtree = dtree.fit(X_train,y_train) #训练模型:喂数据让模型学习规律
2.5.3 模型预测
获取预测类别和预测概率 :
# --- 预测类别标签(0/1)---
y_pred_class = dtree.predict(X_test) ##测试集的预测类别标签
# --- 预测概率(用于 ROC 曲线,只取正类的概率)---
y_pred_proba = dtree.predict_proba(X_test)[:, 1] #测试集的预测概率标签
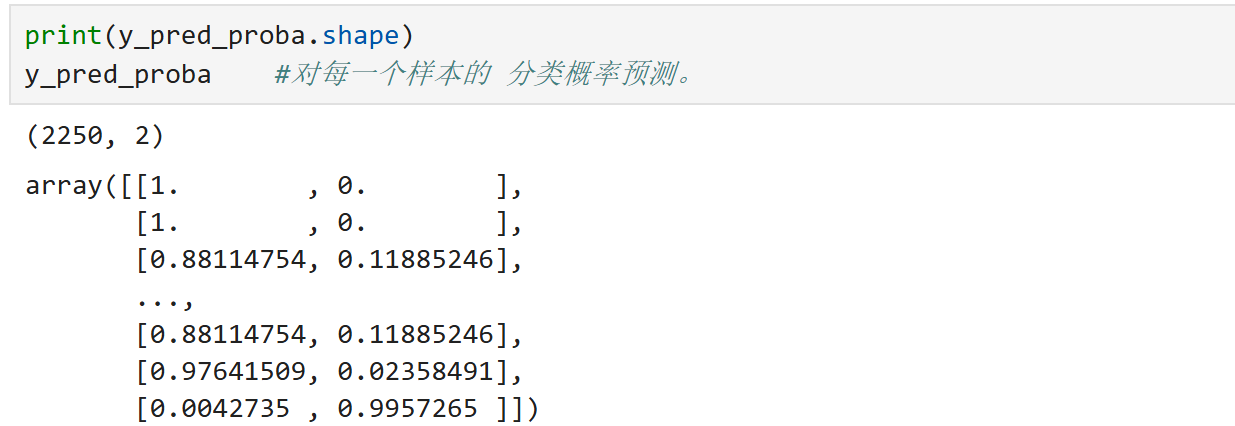
2250个样本的预测类别 :

2250个样本的预测概率 :
输出的格式是:[负类的概率(class 0), 正类的概率(class 1)]
- [1. , 0. ] 表示模型认为该样本 100% 属于类别 0(比如“未离职”)。
- [0.88114754, 0.11885246] 表示模型预测该样本:属于类别 0 的概率是 88.11%,属于类别 1 的概率是 11.89%。
2.5.4 模型评价
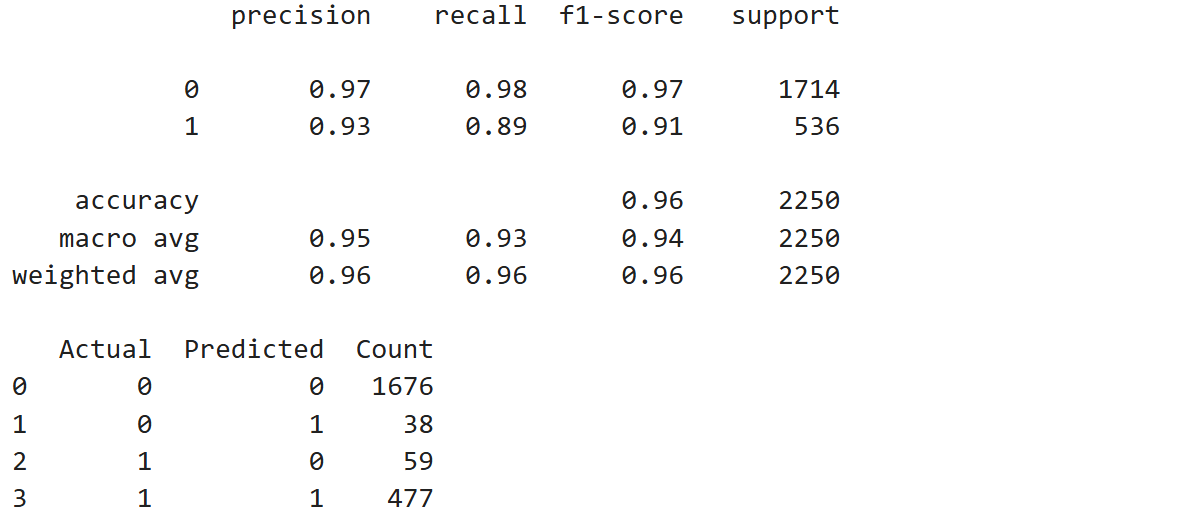
2.5.4.1 分类评估指标:precision(精确率)、recall(召回率)、F1-score(F1值)、support(每类的样本数)
注意:(1)classification_report(y_test, y_pred_class) 用的是“类别”,不是“概率”。
(2)它的输入要求是:y_test:真实的标签(一般是 0 或 1,或者多分类标签);y_pred_class:预测出来的“类别结果”,也是 0 或 1(或多类)。
#---模型评价1:分类评估指标
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_class))
df_compare = pd.DataFrame({
'Actual': y_test.values,
'Predicted': y_pred_class
});df_compare
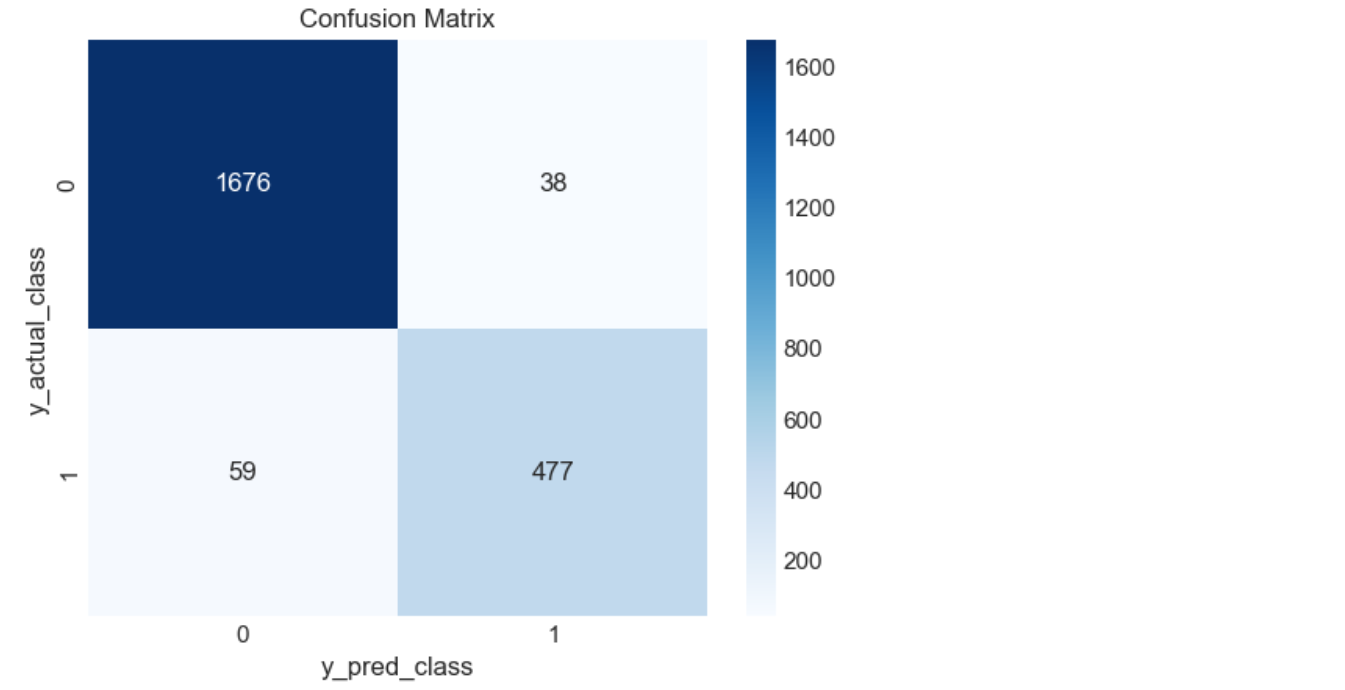
(1)precision(精确率):在所有被模型预测为“正类”的样本中,实际为正类的比例是多少?
precision=477/(38+477)=0.93 预测为正的样本
precision=1676/(1676+59)=0.97 预测为负的样本
(2)recall(召回率): 在所有真实为“正类”的样本中,模型成功预测出“正类”的比例。
recall=477/(59+477) =0.89 实际为正的样本
recall=1676/(1676+38)=0.98 实际为负的样本
(3) F1-score : 精确率和召回率的平均数。
F1-score=(0.93+0.89)/2=0.91 正样本
F1-score=(0.97+0.98)/2=0.97 负样本
(4) Accuracy :所有预测正确的样本 / 总样本数。
Accuracy=(1676+477)/2250=0.96
2.5.4.2 ROC-AUC 评分(模型区分能力)
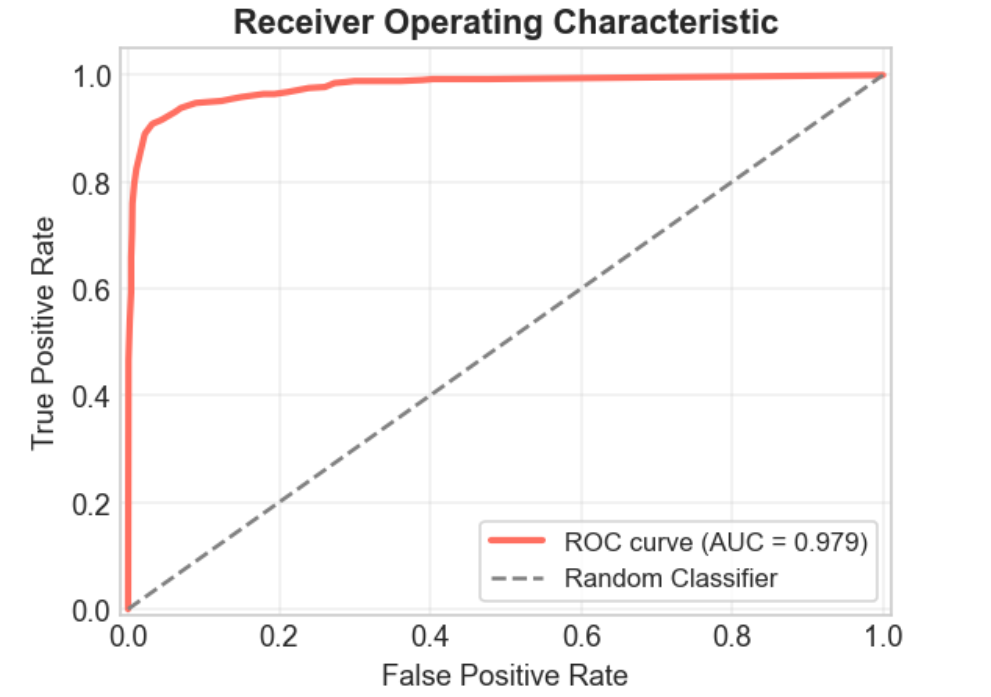
ROC(Receiver Operating Characteristic)曲线,全称是接收者操作特征曲线,原本来自雷达信号检测领域,如今在机器学习中广泛用于评估二分类模型的性能。ROC 曲线的横轴和纵轴是:横轴:FPR(假正率)、纵轴:TPR(真正率) = Recall(召回率)。
怎么看 ROC 曲线好不好?①ROC 曲线 越靠近左上角,说明模型性能越好;②随机模型的 ROC 是一条对角线(AUC = 0.5);③完美模型:ROC 直接到左上角(AUC = 1)。
什么是 AUC?AUC(Area Under the Curve)是 ROC 曲线下的面积。①AUC 越接近 1,模型越优秀;②常用来做模型对比的标准之一。
绘制ROC曲线的代码如下:
#---模型评价2:ROC
from sklearn.metrics import roc_curve, roc_auc_score
# 计算 FPR、TPR 和 AUC
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba[:, 1])
roc_score = roc_auc_score(y_test, y_pred_proba[:, 1])
# 设置图形风格
plt.style.use('seaborn-v0_8-whitegrid')
# 更柔和的背景风格
# 图形尺寸与 DPI(适合高清保存)
plt.figure(figsize=(5, 4), dpi=120)
# 绘制 ROC 曲线
plt.plot(fpr, tpr, color='#FF6F61', linewidth=2.5, label='ROC curve (AUC = %.3f)' % roc_score)
plt.plot([0, 1], [0, 1], color='gray', linewidth=1.5, linestyle='--', label='Random Classifier')
# 设置轴范围和标签
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.05])
plt.xlabel('False Positive Rate', fontsize=11)
plt.ylabel('True Positive Rate', fontsize=11)
plt.title('Receiver Operating Characteristic', fontsize=13, fontweight='bold')
# 图例
plt.legend(loc='lower right', fontsize=10, frameon=True)
# 网格 & 美化
plt.grid(alpha=0.3)
plt.tight_layout()
# 展示图像
plt.show()
ROC曲线:
2.5.4.3 混淆矩阵(直观查看分类效果)
#---模型评价3:混淆矩阵(直观查看分类效果)
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
cm = confusion_matrix(y_test, y_pred_class)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("y_pred_class")
plt.ylabel("y_actual_class")
plt.title("Confusion Matrix")
plt.show()
2.5.4.e PR曲线(特别适用于类别不平衡)
PR 曲线,全称是 Precision-Recall Curve(查准率-查全率曲线),是用于二分类模型性能评估 的一种图形工具,特别适合在 正负样本不均衡的情况下使用。
横轴是 Recall(召回率)((查全率))
纵轴是 Precision(精准率)(查准率)
你通过不断改变分类的概率阈值(比如默认是0.5,改成0.6、0.4等),模型会给出不同的预测结果,从而得到不同的 precision 和 recall 值,连接所有点就得到了 PR 曲线。
#---模型评价4:PR曲线
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_test, y_pred_proba[:, 1])
plt.plot(recall, precision, marker='.')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.grid(True)
plt.show()
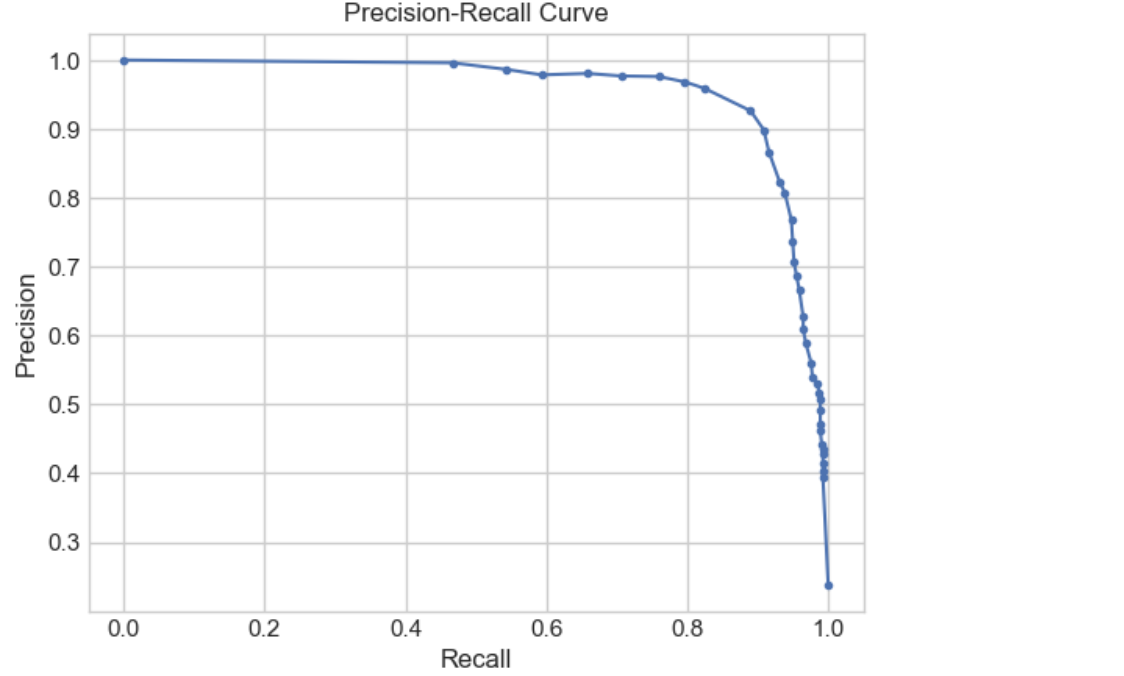
PR 曲线好在哪里?
如果你的正负样本非常不均衡(比如垃圾邮件识别,99% 都是正常邮件),那 ROC 曲线可能会虚高,而 PR 曲线在这种情况下更敏感,更能反映模型真正的区分能力。曲线下的面积越大(AUC-PR)越好,表示模型的查准率和查全率都很高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









