






报错提示:
>>> import nltk
>>> nltk.download('stopwords')
按照提示执行后
[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]
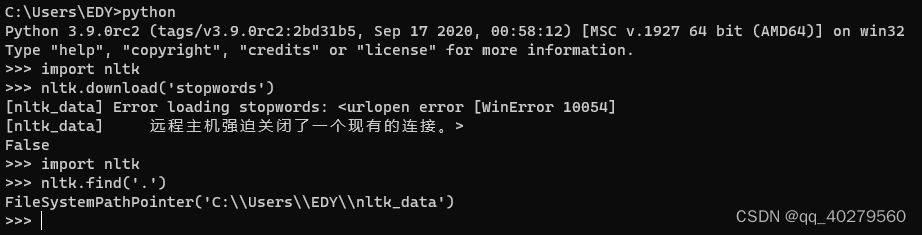
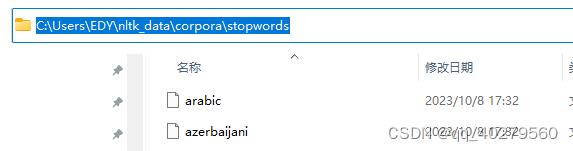
找到路径'C:\\Users\\EDY\\nltk_data',如果没有nltk_data文件夹,在C:\\Users\\EDY下新建nltk_data文件夹,再进去nltk_data新建corpora文件夹,到git下载:packages/corpora/stopwords.zip · gh-pages · mirrors / nltk / nltk_data · GitCode 后燃解压到corpora文件夹里就可以了














 2266
2266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









