






目录
一、竞赛介绍
ps:附上后续连接 https://blog.csdn.net/qq_40285589/article/details/137042462
附上比赛链接(ps:比赛已经结束,截止2024.3.11仍可以提交)
https://www.kaggle.com/competitions/open-problems-multimodal
简单来说(详细的介绍建议直接看比赛介绍,无需魔法):就是给你2份excel表(有一份是提交模板,一份是单人第二天提交细胞清单),量分别分别记录了提供者、cell_id、gene_id、cell_type、technology,这几个数据以cell_id为key互相关联,.h5文件则记录了cell_id以及DNA,RNA,蛋白质水平(这三者通过不同的转换手段转换为了(1,n)的矩阵)。贴上数据列表:

该比赛以相关度作为评分基准,我们需要产生两个模型,分别对cite以及 Multi两种检测技术进行预测,submission文件中随机分布着两种检测技术的cell_id。
PS:鉴于篇幅问题,我会分成几个模块来进行说明,本章节主要包括数据预处理以及模型训练阶段。
二、数据预处理
这是一个典型的回归任务,如果内存/显存足够,我们甚至可以暴力的使用全连接层来无脑进行分析,然而对于医学数据尤其是基因模块的,数据维度以及大小日常爆炸(但多是稀疏矩阵),以Kaggle提供的GPU(T4*2/P100)16G 的内存,会out of memory,所以对数矩阵进行压缩或是降维便是我们需要进行的基本准备了。
ps:基本的矩阵压缩手段 SRC、COO 降维手段SVD,这里我一开始尝试的使用SRC,COO,但后来想想使用SVD降维会是更好的选择,我在cite模型中就尝试了这种方法,读者可以尝试在Multi模型中使用降维手段,也欢迎留言告诉SVD效果如何
2.1处理.h5文件
kaggle没有自带tables库需要手动安装下,用于读取.h5文件(pandas也可以,不过我习惯tables了)
!pip install tables对CSV文件进行压缩转为parquet格式(能省一点是一点)
def convert_to_parquet(filename, out_filename):
df = pd.read_csv(filename)
df.to_parquet(out_filename + ".parquet")将.h5内的稀疏矩阵保存为.npz文件方便读取
import scipy
import pandas as pd
import numpy as np
def convert_h5_to_sparse_csr(filename, out_filename, chunksize=2500):
start = 0
total_rows = 0 #记录总条数
sparse_chunks_data_list = []
chunks_index_list = []
columns_name = None
while True:
df_chunk = pd.read_hdf(filename, start=start, stop=start+chunksize)
if len(df_chunk) == 0:
break
chunk_data_as_sparse = scipy.sparse.csr_matrix(df_chunk.to_numpy())
sparse_chunks_data_list.append(chunk_data_as_sparse)
chunks_index_list.append(df_chunk.index.to_numpy())
if columns_name is None:
columns_name = df_chunk.columns.to_numpy()
else:
assert np.all(columns_name == df_chunk.columns.to_numpy())
total_rows += len(df_chunk)
print(total_rows)
if len(df_chunk) < chunksize:
del df_chunk
break
del df_chunk
start += chunksize
all_data_sparse = scipy.sparse.vstack(sparse_chunks_data_list)
del sparse_chunks_data_list
all_indices = np.hstack(chunks_index_list)
scipy.sparse.save_npz(out_filename+".npz", all_data_sparse)
np.savez(out_filename+"_idxcol.npz", index=all_indices, columns=columns_name)依次处理文件
convert_to_parquet(r"/kaggle/input/open-problems-multimodal/metadata.csv", "metadata")
convert_to_parquet(r"/kaggle/input/open-problems-multimodal/evaluation_ids.csv", "evaluation")
convert_to_parquet(r"/kaggle/input/open-problems-multimodal/sample_submission.csv", "sample_submission")
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/train_multi_inputs.h5','train_multi_inputs')
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/train_multi_targets.h5','train_multi_targets')
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/train_cite_inputs.h5','train_cite_inputs')
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/train_cite_targets.h5','train_cite_targets')
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/test_cite_inputs.h5','test_cite_inputs')
convert_h5_to_sparse_csr('/kaggle/input/open-problems-multimodal/test_multi_inputs.h5','test_multi_inputs')由于文件比较大,我是分批次处理后新建了一个trian的code来进行训练。(kaggle cpu 处理比本地慢,这部分文件处理我是在本地实现的,然后再手动上传)
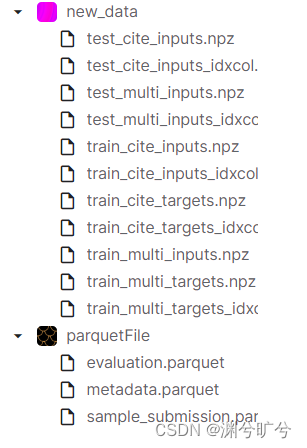
2.2 读取.h5文件并进行压缩
将CSR传入GPU中(ps:后续发现使用CSR会超内存,还是用了COO)
TorchCSR = collections.namedtuple("TorchCSR",'data indices indptr shape')
#将CSR压缩文件传入GPU
def load_csr_data_to_gpu(train_inputs):
th_data = torch.from_numpy(train_inputs.data).to(device)
th_indices = torch.from_numpy(train_inputs.indices).to(device)
th_indptr = torch.from_numpy(train_inputs.indptr).to(device)
th_shape = train_inputs.shape
return TorchCSR(th_data,th_indices,th_indptr,th_shape)CSR转COO
def csr_to_coo(torch_csr,indx):
th_data,th_indices,th_indptr,th_shape = torch_csr
start_pts = th_indptr[indx]
end_pts = th_indptr[indx+1]
coo_data = torch.cat([th_data[start_pts[i]: end_pts[i]] for i in range(len(start_pts))], dim=0)
coo_col = torch.cat([th_indices[start_pts[i]: end_pts[i]] for i in range(len(start_pts))], dim=0)
coo_row = torch.repeat_interleave(torch.arange(indx.shape[0], device=device), th_indptr[indx + 1] - th_indptr[indx])
#转换为coo压缩格式对象
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [indx.shape[0], th_shape[1]])
return coo_batch
def csr_to_coo_batch(torch_csr,indx):
th_data, th_indices, th_indptr, th_shape = torch_csr
if end > th_shape[0]:
end = th_shape[0]
start_pts = th_indptr[start]
end_pts = th_indptr[end]
coo_data = th_data[start_pts: end_pts]
coo_col = th_indices[start_pts: end_pts]
coo_row = torch.repeat_interleave(torch.arange(end-start, device=device), th_indptr[start+1:end+1] - th_indptr[start:end])
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [end-start, th_shape[1]])
return coo_batch
def make_coo_batch_slice(torch_csr, start, end):
th_data, th_indices, th_indptr, th_shape = torch_csr
if end > th_shape[0]:
end = th_shape[0]
start_pts = th_indptr[start]
end_pts = th_indptr[end]
coo_data = th_data[start_pts: end_pts]
coo_col = th_indices[start_pts: end_pts]
coo_row = torch.repeat_interleave(torch.arange(end-start, device=device), th_indptr[start+1:end+1] - th_indptr[start:end])
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [end-start, th_shape[1]])
return coo_batch三、模型训练
3.1损失函数
损失函数选用相关系数(这次比赛打分就是按照相关系数打分,所以损失函数以此为为标准)。
def partial_correlation_score_torch_faster(y_true, y_pred):
y_true_centered = y_true - torch.mean(y_true, dim=1)[:,None]
y_pred_centered = y_pred - torch.mean(y_pred, dim=1)[:,None]
cov_tp = torch.sum(y_true_centered*y_pred_centered, dim=1)/(y_true.shape[1]-1)
var_t = torch.sum(y_true_centered**2, dim=1)/(y_true.shape[1]-1)
var_p = torch.sum(y_pred_centered**2, dim=1)/(y_true.shape[1]-1)
return cov_tp/torch.sqrt(var_t*var_p)
def correl_loss(pred, tgt):
return -torch.mean(partial_correlation_score_torch_faster(tgt, pred))3.2 模型建立
为了尽可能的减少内存,这里使用了2层MLP模型
class MLP(nn.Module):
def __init__(self, layer_size_lst, add_final_activation=False):
super().__init__()
assert len(layer_size_lst) > 2
layer_lst = []
for i in range(len(layer_size_lst) - 1):
sz1 = layer_size_lst[i]
sz2 = layer_size_lst[i + 1]
layer_lst += [nn.Linear(sz1, sz2)]
#如果不是最后一层加入激活函数
if i != len(layer_size_lst) - 2 or add_final_activation:
layer_lst += [nn.ReLU()]
self.mlp = nn.Sequential(*layer_lst)
def forward(self, x):
return self.mlp(x)
def build_model():
model = MLP([INPUT_SIZE] + config["layers"] + [OUTPUT_SIZE])
if config["head"] == "softplus":
model = nn.Sequential(model, nn.Softplus())
else:
assert config["head"] is None
return model3.3批读取器
class DataLoaderCOO:
def __init__(self, train_inputs, train_targets, train_idx=None,
*,
batch_size=512, shuffle=False, drop_last=False):
self.batch_size = batch_size
self.shuffle = shuffle
self.drop_last = drop_last
self.train_inputs = train_inputs
self.train_targets = train_targets
self.train_idx = train_idx
self.nb_examples = len(self.train_idx) if self.train_idx is not None else train_inputs.shape[0]
self.nb_batches = self.nb_examples//batch_size
if not drop_last and not self.nb_examples%batch_size==0:
self.nb_batches +=1
def __iter__(self):
if self.shuffle:
shuffled_idx = torch.randperm(self.nb_examples, device=device)
if self.train_idx is not None:
idx_array = self.train_idx[shuffled_idx]
else:
idx_array = shuffled_idx
else:
if self.train_idx is not None:
idx_array = self.train_idx
else:
idx_array = None
for i in range(self.nb_batches):
slc = slice(i*self.batch_size, (i+1)*self.batch_size)
if idx_array is None:
inp_batch = make_coo_batch_slice(self.train_inputs, i*self.batch_size, (i+1)*self.batch_size)
if self.train_targets is None:
tgt_batch = None
else:
tgt_batch = make_coo_batch_slice(self.train_targets, i*self.batch_size, (i+1)*self.batch_size)
else:
idx_batch = idx_array[slc]
inp_batch = make_coo_batch(self.train_inputs, idx_batch)
if self.train_targets is None:
tgt_batch = None
else:
tgt_batch = make_coo_batch(self.train_targets, idx_batch)
yield inp_batch, tgt_batch
def __len__(self):
return self.nb_batches3.4模型训练
最后便是使用K折验证进行模型训练(emmm这块直接看最后的全部代码吧)
最后会生成如下文件: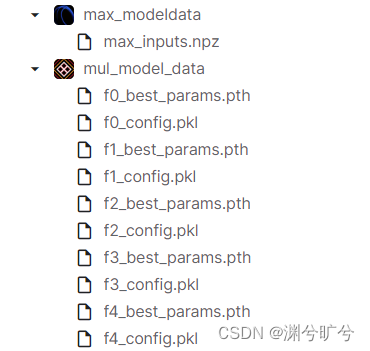
附上这部分代码:
import collections
import pandas as pd
import numpy as np
import torch
from tqdm.notebook import tqdm
import torch.nn as nn
import pickle
import copy
import scipy.sparse
import torch
import gc
import glob
#partial_correlation_score_torch_faster:相关系数(通过协方差实现) correl_loss 以相关系数作为损失函数
def partial_correlation_score_torch_faster(y_true, y_pred):
y_true_centered = y_true - torch.mean(y_true, dim=1)[:,None]
y_pred_centered = y_pred - torch.mean(y_pred, dim=1)[:,None]
cov_tp = torch.sum(y_true_centered*y_pred_centered, dim=1)/(y_true.shape[1]-1)
var_t = torch.sum(y_true_centered**2, dim=1)/(y_true.shape[1]-1)
var_p = torch.sum(y_pred_centered**2, dim=1)/(y_true.shape[1]-1)
return cov_tp/torch.sqrt(var_t*var_p)
def correl_loss(pred, tgt):
return -torch.mean(partial_correlation_score_torch_faster(tgt, pred))
#CSR 传GPU
TorchCSR = collections.namedtuple("TorchCSR",'data indices indptr shape')
def load_csr_data_to_gpu(train_inputs):
th_data = torch.from_numpy(train_inputs.data).to(device)
th_indices = torch.from_numpy(train_inputs.indices).to(device)
th_indptr = torch.from_numpy(train_inputs.indptr).to(device)
th_shape = train_inputs.shape
return TorchCSR(th_data,th_indices,th_indptr,th_shape)
#参数设置
config = dict(
layers=[128, 128, 128],
patience=4,
max_epochs=20,
criterion=correl_loss, # nn.MSELoss(),
n_folds=5,
folds_to_train=[0, 1, 2, 3, 4],
kfold_random_state=42,
optimizerparams=dict(
lr=1e-3,
weight_decay=1e-2
),
head="softplus"
)
INPUT_SIZE = 228942
OUTPUT_SIZE = 23418
import torch
# 获取当前分配的GPU内存量
allocated_memory = torch.cuda.memory_allocated()
print("train_data load后当前分配的GPU内存量:", allocated_memory / 1024**3, "GB")
#CSR 转COO
def csr_to_coo(torch_csr,indx):
th_data,th_indices,th_indptr,th_shape = torch_csr
start_pts = th_indptr[indx]
end_pts = th_indptr[indx+1]
coo_data = torch.cat([th_data[start_pts[i]: end_pts[i]] for i in range(len(start_pts))], dim=0)
coo_col = torch.cat([th_indices[start_pts[i]: end_pts[i]] for i in range(len(start_pts))], dim=0)
coo_row = torch.repeat_interleave(torch.arange(indx.shape[0], device=device), th_indptr[indx + 1] - th_indptr[indx])
#转换为coo压缩格式对象
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [indx.shape[0], th_shape[1]])
return coo_batch
def csr_to_coo_batch(torch_csr,indx):
th_data, th_indices, th_indptr, th_shape = torch_csr
if end > th_shape[0]:
end = th_shape[0]
start_pts = th_indptr[start]
end_pts = th_indptr[end]
coo_data = th_data[start_pts: end_pts]
coo_col = th_indices[start_pts: end_pts]
coo_row = torch.repeat_interleave(torch.arange(end-start, device=device), th_indptr[start+1:end+1] - th_indptr[start:end])
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [end-start, th_shape[1]])
return coo_batch
def make_coo_batch_slice(torch_csr, start, end):
th_data, th_indices, th_indptr, th_shape = torch_csr
if end > th_shape[0]:
end = th_shape[0]
start_pts = th_indptr[start]
end_pts = th_indptr[end]
coo_data = th_data[start_pts: end_pts]
coo_col = th_indices[start_pts: end_pts]
coo_row = torch.repeat_interleave(torch.arange(end-start, device=device), th_indptr[start+1:end+1] - th_indptr[start:end])
coo_batch = torch.sparse_coo_tensor(torch.vstack([coo_row, coo_col]), coo_data, [end-start, th_shape[1]])
return coo_batch
#DataLoader
class DataLoaderCOO:
def __init__(self, train_inputs, train_targets, train_idx=None,
*,
batch_size=512, shuffle=False, drop_last=False):
self.batch_size = batch_size
self.shuffle = shuffle
self.drop_last = drop_last
self.train_inputs = train_inputs
self.train_targets = train_targets
self.train_idx = train_idx
self.nb_examples = len(self.train_idx) if self.train_idx is not None else train_inputs.shape[0]
self.nb_batches = self.nb_examples//batch_size
if not drop_last and not self.nb_examples%batch_size==0:
self.nb_batches +=1
def __iter__(self):
if self.shuffle:
shuffled_idx = torch.randperm(self.nb_examples, device=device)
if self.train_idx is not None:
idx_array = self.train_idx[shuffled_idx]
else:
idx_array = shuffled_idx
else:
if self.train_idx is not None:
idx_array = self.train_idx
else:
idx_array = None
for i in range(self.nb_batches):
slc = slice(i*self.batch_size, (i+1)*self.batch_size)
if idx_array is None:
inp_batch = make_coo_batch_slice(self.train_inputs, i*self.batch_size, (i+1)*self.batch_size)
if self.train_targets is None:
tgt_batch = None
else:
tgt_batch = make_coo_batch_slice(self.train_targets, i*self.batch_size, (i+1)*self.batch_size)
else:
idx_batch = idx_array[slc]
inp_batch = make_coo_batch(self.train_inputs, idx_batch)
if self.train_targets is None:
tgt_batch = None
else:
tgt_batch = make_coo_batch(self.train_targets, idx_batch)
yield inp_batch, tgt_batch
def __len__(self):
return self.nb_batches
#模型建立
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, layer_size_lst, add_final_activation=False):
super().__init__()
assert len(layer_size_lst) > 2
layer_lst = []
for i in range(len(layer_size_lst) - 1):
sz1 = layer_size_lst[i]
sz2 = layer_size_lst[i + 1]
layer_lst += [nn.Linear(sz1, sz2)]
#如果不是最后一层加入激活函数
if i != len(layer_size_lst) - 2 or add_final_activation:
layer_lst += [nn.ReLU()]
self.mlp = nn.Sequential(*layer_lst)
def forward(self, x):
return self.mlp(x)
def build_model():
model = MLP([INPUT_SIZE] + config["layers"] + [OUTPUT_SIZE])
if config["head"] == "softplus":
model = nn.Sequential(model, nn.Softplus())
else:
assert config["head"] is None
return model
from tqdm.notebook import tqdm
def train_fn(model, optimizer, criterion, dl_train):
loss_list = []
model.train()
for inpt, tgt in tqdm(dl_train):
mb_size = inpt.shape[0]
tgt = tgt.to_dense()
optimizer.zero_grad()
pred = model(inpt)
loss = criterion(pred, tgt)
loss_list.append(loss.detach())
loss.backward()
optimizer.step()
avg_loss = sum(loss_list).cpu().item() / len(loss_list)
return {"loss": avg_loss}
# 验证集
from tqdm.notebook import tqdm
def valid_fn(model, criterion, dl_valid):
loss_list = []
all_preds = []
all_tgts = []
partial_correlation_scores = []
model.eval()
for inpt, tgt in tqdm(dl_valid):
mb_size = inpt.shape[0]
tgt = tgt.to_dense()
#不计算梯度,不跟新参数
with torch.no_grad():
pred = model(inpt)
loss = criterion(pred, tgt)
loss_list.append(loss.detach())
partial_correlation_scores.append(partial_correlation_score_torch_faster(tgt, pred))
avg_loss = sum(loss_list).cpu().item() / len(loss_list)
partial_correlation_scores = torch.cat(partial_correlation_scores)
score = torch.sum(partial_correlation_scores).cpu().item() / len(
partial_correlation_scores)
return {"loss": avg_loss, "score": score}
import pickle
import copy
def train_model(model, optimizer, dl_train, dl_valid, save_prefix):
criterion = config["criterion"]
save_params_filename = save_prefix + "_best_params.pth"
save_config_filename = save_prefix + "_config.pkl"
best_score = None
for epoch in range(config["max_epochs"]):
log_train = train_fn(model, optimizer, criterion, dl_train)
log_valid = valid_fn(model, criterion, dl_valid)
print(log_train)
print(log_valid)
score = log_valid["score"]
#早停
if best_score is None or score > best_score:
best_score = score
patience = config["patience"]
best_params = copy.deepcopy(model.state_dict())
else:
patience -= 1
if patience < 0:
print("out of patience")
break
torch.save(best_params, save_params_filename)
pickle.dump(config, open(save_config_filename, "wb"))
def train_one_fold(num_fold,train_inputs,train_targets,FOLDS_LIST):
train_idx, valid_idx = FOLDS_LIST[num_fold]
train_idx = torch.from_numpy(train_idx).to(device)
valid_idx = torch.from_numpy(valid_idx).to(device)
dl_train = DataLoaderCOO(train_inputs, train_targets, train_idx=train_idx,
batch_size=512, shuffle=True, drop_last=True)
dl_valid = DataLoaderCOO(train_inputs, train_targets, train_idx=valid_idx,
batch_size=512, shuffle=False, drop_last=False)
model = build_model()
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), **config["optimizerparams"])
train_model(model, optimizer, dl_train, dl_valid, save_prefix="f%i" % num_fold)
# 数据导入
import torch
# 获取当前分配的GPU内存量
allocated_memory = torch.cuda.memory_allocated()
print("当前分配的GPU内存量:", allocated_memory / 1024**3, "GB")
if torch.cuda.is_available():
device = torch.device('cuda:0')
print(f"服务器有{torch.cuda.device_count()}个devices")
else:
device = torch.device('cpu')
# 导入tarin_multi_data
import scipy.sparse
import torch
train_inputs = scipy.sparse.load_npz(r'/kaggle/input/new-data/train_multi_inputs.npz')
# 获取当前分配的GPU内存量
allocated_memory = torch.cuda.memory_allocated()
print("train_data load后当前分配的GPU内存量:", allocated_memory / 1024**3, "GB")
# 获取最大分配的GPU内存量
max_allocated_memory = torch.cuda.max_memory_allocated()
print("最大分配的GPU内存量:", max_allocated_memory / 1024**3, "GB")
# get max值用于归一化
max_inputs = train_inputs.max(axis = 0)
###防止除0无限大
max_inputs = max_inputs.todense()+1e-10
np.savez("max_inputs.npz", max_inputs = max_inputs)
max_inputs = torch.from_numpy(max_inputs)[0].to(device)
import gc
gc.collect()
train_inputs = load_csr_data_to_gpu(train_inputs)
gc.collect()
# 归一化
#归一化
train_inputs.data[...] /= max_inputs[train_inputs.indices.long()]
import scipy.sparse
train_targets = scipy.sparse.load_npz(r'/kaggle/input/new-data/train_multi_targets.npz')
import gc
train_targets = load_csr_data_to_gpu(train_targets)
gc.collect()
# 判别:转换过程中shape是否变化
assert INPUT_SIZE == train_inputs.shape[1]
assert OUTPUT_SIZE == train_targets.shape[1]
NB_EXAMPLES = train_inputs.shape[0]
assert NB_EXAMPLES == train_targets.shape[0]
print(INPUT_SIZE, OUTPUT_SIZE, NB_EXAMPLES)
from sklearn.model_selection import KFold
kfold = KFold(n_splits=config["n_folds"], shuffle=True, random_state=config["kfold_random_state"])
FOLDS_LIST = list(kfold.split(range(train_inputs.shape[0])))
for num_fold in config["folds_to_train"]:
train_one_fold(num_fold,train_inputs,train_targets,FOLDS_LIST)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











