






由于数据集需要翻墙,先附上数据集
链接:https://pan.baidu.com/s/10MTlK_3kXMRw6JsSTT8tVg?pwd=6666
提取码:6666
注意正文会讲述我的步骤处理思路(代码可能并不会完整的放在正文中(这过于繁琐了),需要整段代码的请直接跳转至文末)
一、题目背景
在这个任务中,你的目标是预测在泰坦尼克号宇宙飞船与时空异常相撞期间,乘客是否被送往另一个维度,并传送回1000年前的同名时空。为了辅助你进行这些预测,你将获得一组从船上受损的计算机系统中恢复的个人记录。
1. 题目
在这场比赛中,你的任务是预测在泰坦尼克号宇宙飞船与时空异常相撞期间,乘客是否被运送到另一个维度,传送回1000年前同名的时空。为了帮助你做出这些预测,你会得到一组从船上损坏的计算机系统中恢复的个人记录。
2. 计算机中恢复的个人记录
- train.csv - 包含约三分之二(约8700)乘客的个人记录,作为训练数据。
- test.csv - 包含剩余三分之一(约4300)乘客的个人记录,作为测试数据。你的任务是预测这个集合中乘客的 Transported 值。
字段解释:
- PassengerId - 每位乘客的唯一ID。每个ID的格式为 gggg_pp,其中 gggg 表示乘客所属的团体, pp 表示他们在团体中的序号。团体可以是家庭成员,但不限于此。
- HomePlanet - 乘客的出发星球,通常是他们的永久居住星球。
- CryoSleep - 指示乘客是否选择在航行期间进入冷冻睡眠状态。处于冷冻睡眠状态的乘客被限制在他们的客舱内。
- Cabin - 乘客所住的舱位号,格式为 deck/num/side,其中 side 可以是 P(左舷)或 S(右舷)。
- Destination - 乘客计划前往的目的地星球。
- Age - 乘客的年龄。
- VIP - 旅客在航程中是否支付了特殊VIP服务费用。
- RoomService,FoodCourt,ShoppingMall,Spa,VRDeck - 乘客在泰坦尼克号宇宙飞船上享受各项豪华设施所支付的费用。
- Name - 乘客的姓名。
二、数据预处理
下图是excel中的数据(这比python显示会来的更加直观些),注意:每列数据都可能会有所空缺
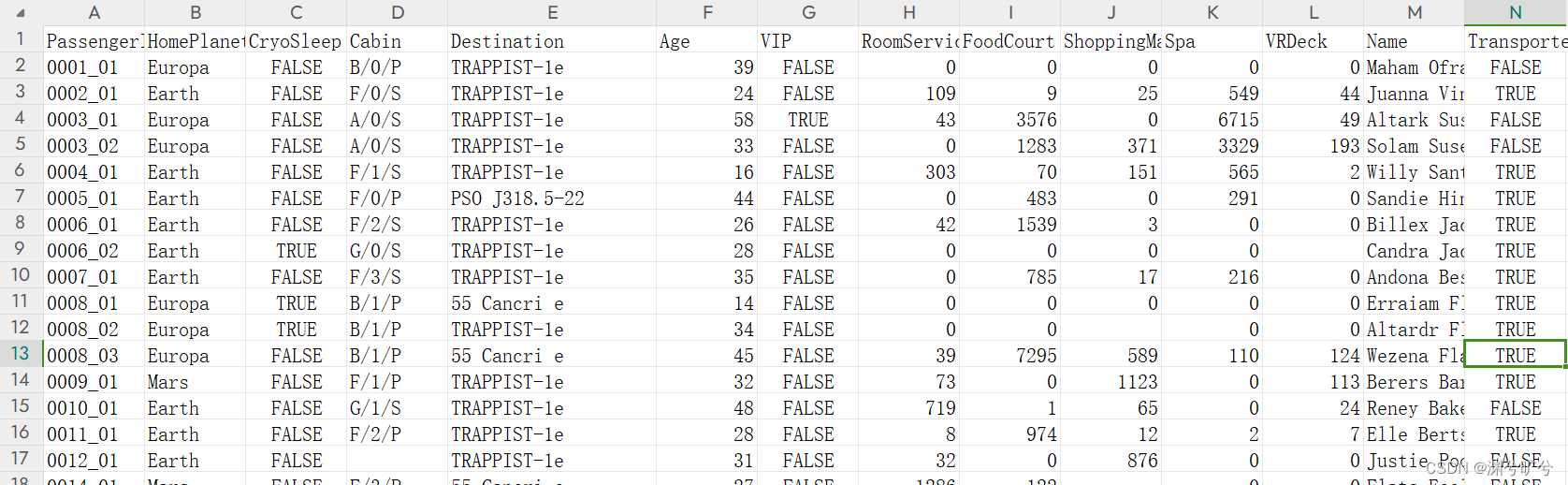
下面我们来对各列数据 进行逐列分析来确认它们的补全策略(ps:初步补全可以利用生成,更加直观,当然excel直接利用筛选来看分布(这对于类别较少的列快些),两者可以看喜好使用)
2.1 空值补缺
首先观察各列空值情况,如下图id以及是否被传入异次元是无空值的,那么我们对其他列进行分析补空
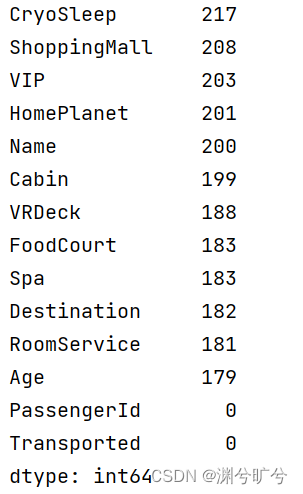
首先,我们将空值去除(空值占比较少)后来管啥各个数据之间以及其与Transported是否有明显的关联性(对于关联性较差的空值可以选取众值或者均值补充,对于高关联性的则需要谨慎对待)
data_connectionreaserch = train_data.dropna()丢弃后还有6606个数据,保存相对较多,可以体现相关性。

舍去id、name等难以编码的行,然后计算皮尔逊相关系数矩阵。
train_num = train_data.shape[0]
data = pd.concat([train_data,test_data],ignore_index=True)
data_connectionreaserch = train_data.dropna()#用来映射
data_connectionreaserch = data_connectionreaserch.drop(['Name'], axis=1)
data_connectionreaserch = data_connectionreaserch.drop(['Cabin'], axis=1)
data_connectionreaserch = data_connectionreaserch.drop(['PassengerId'], axis=1)
print(data_connectionreaserch)
map_HomePlanet ={
'Earth':0,
'Europa':1,
'Mars':2
}
map_bool = {
False : 0,
True : 1
}
map_Destination = {
'55 Cancri e' : 0,
'PSO J318.5-22' : 1,
'TRAPPIST-1e' : 2
}
data_connectionreaserch.loc[:,'HomePlanet'] = data_connectionreaserch.HomePlanet.map(map_HomePlanet)
data_connectionreaserch.loc[:,'Destination'] = data_connectionreaserch.Destination.map(map_Destination)
data_connectionreaserch.loc[:,'CryoSleep'] = data_connectionreaserch.CryoSleep.map(map_bool)
data_connectionreaserch.loc[:,'VIP'] = data_connectionreaserch.VIP.map(map_bool)
data_connectionreaserch.loc[:,'Transported'] = data_connectionreaserch.Transported.map(map_bool)
print(data_connectionreaserch.corr())结果如下:
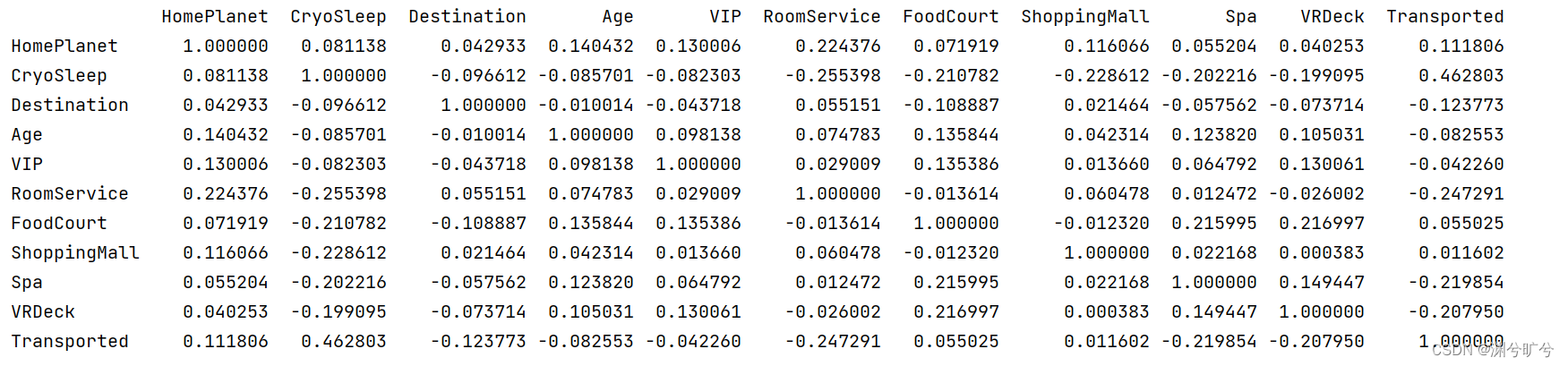
从矩阵可以看书Transported与是否冷冻休眠有高相关,对于年龄、是否VIP相关性较低,综上,采取如下补空策略
1.ID pass,无空值
2.HomePlanet(居住星球),我们取众数Earth填充

3.CryoSleep(是否冷冻休眠):相关度较高,参考7奢侈服务,指定补空规则:若在旅途中产生任何服务费用,则选择非冷冻休眠,泛指则选择冷冻休眠
4.Destination(目的地)选用众数填充
5.Age 选用均数填充
6.VIP 选用众数填充
7.奢侈服务用5项中有3项相关度较高,采用若成员选择了冷冻休眠,服务均置零(当前数据集基冷冻休眠除控制外服务费用均为0,所以不考虑中途解冻可能性),剩余以均值填充(这点可以优化)
8.Name 直接drop掉
9.Cabin 暂时不处理(见特征拆分)
2.2 特征拆分
PlanA:
最后选择前6相关度高的作为训练集数据即: CryoSleep RoomService Spa VRDeck Destination Age,最后得分71,平均80以上,所以对于特征工程还需要进一步分析
PlanB:
进一步提取特征
Cabin 列,格式如下:(A-Z)/(int)/(P/S),其中A-Z表示休息仓区,int表示仓号,P/S表示在左舷或者右舷(PS:这里本来是做绘图的但是后来改着改着被我删了,懒得再写一遍),可以根据绘图比较明显的看出各个休息厂区以及左舷右舷被传送的概率并不是均匀的,这也就意味着,在这个项目中,位置关系是一个比重比较高的要素,所以我们将Cabin列拆分'Cabin_Deck', 'Cabin_Num', 'Cabin_Side'三项,类别特征以众数填充,数值特征以均值填充(K临近或许会更好些,但会比较耗费处理时间,读者可以尝试一下)
D列,格式类似 0002-02,其中0002是序列号,没有实际意义,02表示他和0002-01,0002-03(如果存在)是一个group的,所以可以根据此提取出组员的特征,由于id无空值,所以无需补空。(组员更加可能会同时外出,对于有一定的空间影响因素)
df_train[['Cabin_Deck', 'Cabin_Num', 'Cabin_Side']] = df_train['Cabin'].str.split('/', expand=True)
df_test[['Cabin_Deck', 'Cabin_Num', 'Cabin_Side']] = df_test['Cabin'].str.split('/', expand=True)
df_train=df_train.drop('Cabin', axis=1)
df_test=df_test.drop('Cabin', axis=1)
df_train['Family_id'] = df_train['PassengerId'].str.extract('(\d+)_', expand=False)
df_train['Family_num'] = df_train['PassengerId'].str.extract('_(\d+)', expand=False)
df_train['Family'] = df_train.groupby('Family_id')['Family_num'].transform('count')
df_train = df_train.drop(['Family_id', 'Family_num'], axis=1)
df_test['Family_id'] = df_test['PassengerId'].str.extract('(\d+)_', expand=False)
df_test['Family_num'] = df_test['PassengerId'].str.extract('_(\d+)', expand=False)
df_test['Family'] = df_test.groupby('Family_id')['Family_num'].transform('count')
df_test = df_test.drop(['Family_id', 'Family_num'], axis=1)这样我们就获得了额外的4个特征项用于训练(PS:得出新的特征后还是可以通过plt或者sns绘图,来看分布,或者通过关系系数来找数值上的关联)
三、模型选择以及调参
3.1模型选择
这是一个典型的二分类任务,对于二分类任务有很多的模型适用,机器学习算法中决策树、随机森林、XGBoost、Catboost等等算法,我们可以根据其性质选择最优的算法。(当然,这是入门级项目,大部分人了解可能并不深入,那么不妨试试用默认参数使用不同算法,选择得分最高的几个再进行调优,然后从结果往后推,为什么会适用这种情况)
最终我选择了决策树以及CatBoost两个模型(决策树78.74,CatBoost0.80)
3.2调参
调参很多人说是经验主义,那么经验较少的如何微调参数来提升模型正确率么(注意:我下面提供的方法当模型较大的时候会花费比较长的时间,小模型比较推荐),首先利用随机调参来获取较优的参数,然后在在该参数组区间内进行网格取优。
最后提交得分。

最后附上全部代码2024.3.5,kaggle可以跑通(这里我只选用了随机调参,但其实是经过了几次随机+网格后确定大致范围了,再使用随机调参(毕竟网格穷举很慢。。。)减少模型运行时间)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
##模型
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
## 评估
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.model_selection import RandomizedSearchCV , GridSearchCV
from sklearn.metrics import confusion_matrix , classification_report
from sklearn.metrics import precision_score , recall_score , f1_score,accuracy_score
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
train=pd.read_csv("/kaggle/input/spaceship-titanic/train.csv")
test=pd.read_csv("/kaggle/input/spaceship-titanic/test.csv")
df_train=train.drop("Name",axis=1)
df_test=test.drop("Name",axis=1)
# print(df_test.isna().sum())
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
#完成数据清洗+训练测试集切分
def preprocess_data(df_train, df_test):
# Cabin按‘/'切分数据
df_train[['Cabin_Deck', 'Cabin_Num', 'Cabin_Side']] = df_train['Cabin'].str.split('/', expand=True)
df_test[['Cabin_Deck', 'Cabin_Num', 'Cabin_Side']] = df_test['Cabin'].str.split('/', expand=True)
df_train=df_train.drop('Cabin', axis=1)
df_test=df_test.drop('Cabin', axis=1)
Needed_columns = ['HomePlanet', 'CryoSleep', 'Destination', 'VIP', 'Cabin_Deck', 'Cabin_Num', 'Cabin_Side']
# #强关系填充
df_train['CryoSleep'] = df_train.apply(lambda row: True if (
row['RoomService'] == 0 and row['FoodCourt'] == 0 and row['ShoppingMall'] == 0 and row['Spa'] == 0 and
row['VRDeck'] == 0 and row.isna().any()) else False, axis=1)
df_train['RoomService'] = df_train.apply(lambda row: 0 if row['CryoSleep'] else row['RoomService'], axis=1)
df_train['FoodCourt'] = df_train.apply(lambda row: 0 if row['CryoSleep'] else row['FoodCourt'], axis=1)
df_train['ShoppingMall'] = df_train.apply(lambda row: 0 if row['CryoSleep'] else row['ShoppingMall'], axis=1)
df_train['Spa'] = df_train.apply(lambda row: 0 if row['CryoSleep'] else row['Spa'], axis=1)
df_train['VRDeck'] = df_train.apply(lambda row: 0 if row['CryoSleep'] else row['VRDeck'], axis=1)
df_test['CryoSleep'] = df_test.apply(lambda row: True if (
row['RoomService'] == 0 and row['FoodCourt'] == 0 and row['ShoppingMall'] == 0 and row['Spa'] == 0 and
row['VRDeck'] == 0 and row.isna().any()) else False, axis=1)
df_test['RoomService'] = df_test.apply(lambda row: 0 if row['CryoSleep'] else row['RoomService'], axis=1)
df_test['FoodCourt'] = df_test.apply(lambda row: 0 if row['CryoSleep'] else row['FoodCourt'], axis=1)
df_test['ShoppingMall'] = df_test.apply(lambda row: 0 if row['CryoSleep'] else row['ShoppingMall'], axis=1)
df_test['Spa'] = df_test.apply(lambda row: 0 if row['CryoSleep'] else row['Spa'], axis=1)
df_test['VRDeck'] = df_test.apply(lambda row: 0 if row['CryoSleep'] else row['VRDeck'], axis=1)
df_train['Family_id'] = df_train['PassengerId'].str.extract('(\d+)_', expand=False)
df_train['Family_num'] = df_train['PassengerId'].str.extract('_(\d+)', expand=False)
df_train['Family'] = df_train.groupby('Family_id')['Family_num'].transform('count')
df_train = df_train.drop(['Family_id', 'Family_num'], axis=1)
df_test['Family_id'] = df_test['PassengerId'].str.extract('(\d+)_', expand=False)
df_test['Family_num'] = df_test['PassengerId'].str.extract('_(\d+)', expand=False)
df_test['Family'] = df_test.groupby('Family_id')['Family_num'].transform('count')
df_test = df_test.drop(['Family_id', 'Family_num'], axis=1)
#获取没列众数
most = df_train[Needed_columns].mode().iloc[0]
# 众数填充
df_train[Needed_columns] = df_train[Needed_columns].fillna(most)
df_test[Needed_columns] = df_test[Needed_columns].fillna(most)
numerical_cols = df_train.columns[df_train.dtypes == 'float64']
# 均值填充
df_train[numerical_cols] = df_train[numerical_cols].fillna(df_train[numerical_cols].mean())
df_test[numerical_cols] = df_test[numerical_cols].fillna(df_test[numerical_cols].mean())
df_train['Cabin_Num'] = df_train['Cabin_Num'].astype(int)
df_test['Cabin_Num'] = df_test['Cabin_Num'].astype(int)
X = df_train.drop(['Transported', 'PassengerId'], axis=1)
y = df_train['Transported'].astype(int)
# 分类特征(bool也算)
categorical_features = ['HomePlanet', 'CryoSleep', 'Destination', 'VIP', 'Cabin_Deck', 'Cabin_Side']
#int
numerical_features = ['Age', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck', 'Cabin_Num','Family']
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_features),#0-1转换
('cat', OneHotEncoder(), categorical_features) #独热
])
X_prep = preprocessor.fit_transform(X)
test_prep = preprocessor.fit_transform(df_test)
X_train, X_test, y_train, y_test = train_test_split(X_prep, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test,test_prep
X_train, X_test, y_train, y_test, test_prep = preprocess_data(df_train, df_test)
# import catboost as cb
# cb_claasifier = cb.CatBoostClassifier()
# # params = {'n_estimators': [50, 100, 200],
# # # 'max_depth': [None, 10, 20]}
# params ={'iterations':[160,180,190,200], 'depth':[4,5,6,7], 'learning_rate':[0.05,0.1,0.15],'random_strength':[1,2,4,6]}
# #{'depth': 5, 'iterations': 180, 'learning_rate': 0.1, 'random_strength': 1} 0.7999
# grid_search_ranf = GridSearchCV(estimator=cb_claasifier, param_grid=params, cv=3, scoring='neg_log_loss', n_jobs=-1)
# grid_search_ranf.fit(X_train, y_train)
# print("Best RandomForest:", grid_search_ranf.best_params_)
# best_ranf_model = grid_search_ranf.best_estimator_
# y_pred_ranf2 = best_ranf_model.predict(X_test)
# accuracy_2_ranf = accuracy_score(y_test, y_pred_ranf2)
# print("Accuracy:", accuracy_2_ranf)
# y_pred_ranf = best_ranf_model.predict(test_prep)
# pred_df = pd.DataFrame({
# 'PassengerId': df_test['PassengerId'],
# 'Transported': y_pred_ranf
# })
# pred_df['Transported'] = pred_df['Transported'].astype(bool)
# pred_df.to_csv("sample_submission.csv", index = False)
##随机取优
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
cb_classifier = CatBoostClassifier(verbose=False)
param_space = {
'iterations': randint(100, 1000), # 迭代次数
'depth': randint(4, 10), # 树的最大深度
'learning_rate': [0.01, 0.05, 0.1, 0.15, 0.2], # 学习率
'l2_leaf_reg': randint(1, 10), # L2 正则化系数
'border_count': randint(100, 200), # 边界计数
'subsample': [0.5,0.6, 0.7, 0.8, 0.9, 1.0], # 子样本比例
'colsample_bylevel': [0.5, 0.6 , 0.7 , 0.8 , 0.9 ,1.0], # 列采样比例
'random_strength': randint(1, 10) # 随机强度
}
random_search_cb = RandomizedSearchCV(estimator=cb_classifier, param_distributions=param_space, n_iter=100, cv=3, scoring='accuracy', n_jobs=-1)
random_search_cb.fit(X_train, y_train)
print("Best parameters:", random_search_cb.best_params_)
best_cb_model = random_search_cb.best_estimator_
y_pred_cb = best_cb_model.predict(X_test)
accuracy_cb = accuracy_score(y_test, y_pred_cb)
print("Accuracy:", accuracy_cb)
y_pred_test_cb = best_cb_model.predict(test_prep)
pred_df_cb = pd.DataFrame({
'PassengerId': df_test['PassengerId'],
'Transported': y_pred_test_cb
})
pred_df_cb['Transported'] = pred_df_cb['Transported'].astype(bool)
pred_df_cb.to_csv("submission_cb_random_search.csv", index=False)














 1809
1809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











