






论文写不出来,先做个题吧,本文用了暴力解法和滑动窗口法。前边两篇说的比较详细了,可以参考下。
1.题目描述:
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
2.题解思路:
我觉得本题就是在s中取p长度的字符串,然后遍历比较,如果相等就返回起始索引。如图所示:
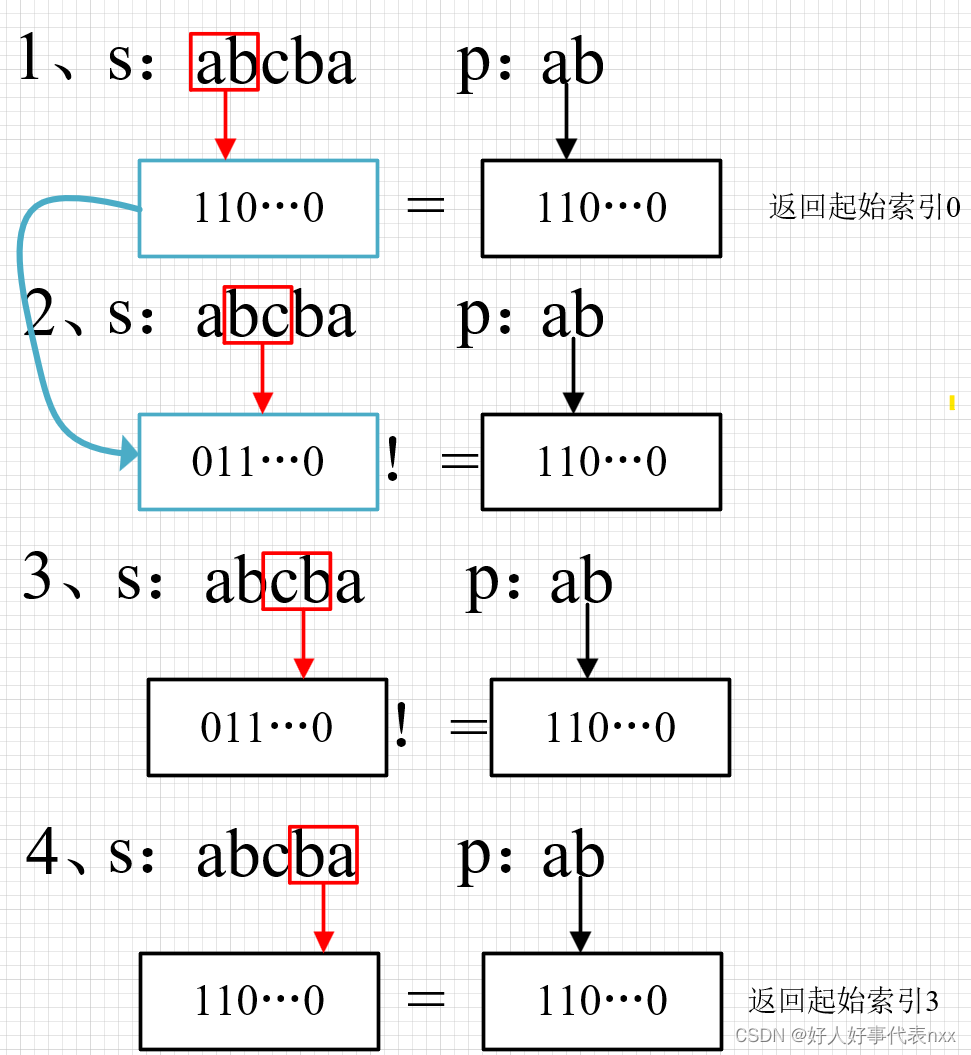
其中核心在于数组遍历,找对应的key。如图蓝色方框的转换。
按照这个思路,我直接暴力解题,先对字符串遍历,再对红框内遍历。再每一次比较之后将红框对应的key全部清零再重新赋值。

后来发现太暴力了,学习了精彩的滑动窗口法:不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果。用一个for循环,完成了两个for循环的效果。
完全不需要重新遍历红框,只需要把删除首位字符,在末尾增加一个新字符。

3.本地实现
#include<iostream>
#include<string>
#include<vector>
using namespace std;
//滑动窗口法
class Solution
{
public:
vector<int>findAnagrams(string s, string p)
{
vector<int> ans;
int slen = s.size();
int plen = p.size();
if (slen < plen) return vector<int>();//s<p是不成立的
vector<int> stable(26, 0);//存放s转换成的key
vector<int> ptable(26, 0);//存放p转换成的key
//先判0索引开始的
for (int i = 0; i < plen; i++)
{
ptable[p[i] - 'a']++;//把字符串p转化成了key
stable[s[i] - 'a']++;//把字符串s转化成了key
}
if (ptable == stable) ans.push_back(0);
//本来想模仿链表的虚拟结点,增加一个首字符。
//结果发现删除前一个,增加后一个的前提是中间有数,比如 abc 由ab变为bc,要先保证b存在stable里。所以增加假头不行。
for (int i = 0; i < slen - plen; i++) //slen-plen判断能滑动多少次
{
stable[s[i] - 'a']--; //删除滑动前首位字符
stable[s[i + plen] - 'a']++;//增加滑动后最后一位字符 (等效为滑动效果)
if (stable == ptable) ans.push_back(i+1);//i=0开始滑动,其实判断的是i=1起始的字符串,所以+1
}
return ans;
}
};
int main()
{
string s = "abab", p = "ab";
Solution solution;
vector<int> res = solution.findAnagrams(s, p);
for (int i = 0; i < res.size(); i++)
{
cout << res[i];
}
system("pause");
return 0;
}不过暴力法也Ac了,嘻嘻
//暴力法,太暴力了
class Solution
{
public:
vector<int>findAnagrams(string s, string p)
{
int slen = s.size();
int plen = p.size();
if (slen < plen) return vector<int>();
vector<int> stable(26, 0);
vector<int> ptable(26, 0);
vector<int> ans;
for (int i = 0; i < plen; i++)
{
ptable[p[i] - 'a']++;//把字符串p转化成了vector
}
for (int i = 0; i <= slen - plen ; i++)
{
for (int j = i; j < i + plen; j++)
{
stable[s[j] - 'a']++;
}
if (stable == ptable)
{
ans.push_back(i);
}
for (auto& val : stable)
{//clear 不行;vector<int> stable(26, 0),重定义也是错的;只能重新填0
val = 0;
}
}
return ans;
}
};














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









