







一、实验环境
(1)Ubuntu16.04LTS 3台虚拟机,用于实现分布式文件存储
(2)IDEA2019.1.3,用于编写Maven项目
(3)FileZilla3.42.1,用于Windows与Linux之间的文件传输
(4)XSHELL6,用于远程连接Ubuntu,我在xshell上执行命令
链接:https://pan.baidu.com/s/13qBZ6nnzJfsHIu7ZlPSlsw
提取码:224z
二、程序功能
统计文本中单词出现的次数,该程序原本就存在hadoop的官方文档中,我们自己额外写一份,为了先熟悉整个的开发过程。
三、具体步骤
(1)在Ubuntu上开启hadoop服务和yarn服务,然后再用jps查看一下,有时候有些节点的运行结果不同,需要在一开始就把错误排查出来。
(2)然后再将我们需要处理的文件,上传至hadoop服务器中,然后我们可以通过网站namenode的IP:50070访问我们的文件结构。
(3)创建一个maven项目。
1.通过IDEA创建maven项目,最开始创建的时候,是不会有红色方框内的东西。需要我们添加
2.添加相应的包,首先打开项目的pom.xml文件,添加如下信息(版本不同,添加的信息也不同,可以通过访问https://mvnrepository.com/网站获得自己对应版本文件)
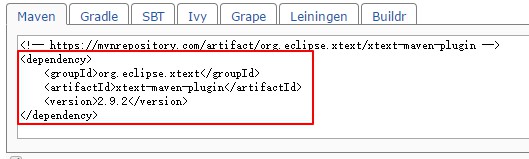
将其添加到我们的pom.xml文件中

最后注意点击Import Changes,在右下角的Even Log中可以看到。
3.在如下的目录中创建我们的java程序,每一个都是.class,就是java的创建格式。(命名规范等都相同)
四、代码编写
(1)WordCount
package net.suncaper.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "word count");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
if (!result){
System.out.println("word count failed");
}
}
}
(2)WordCountMapper
package net.suncaper.hadoop;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String content = value.toString();
String[] words = content.split(" ");
for (String word:
words) {
context.write(new Text(word), new LongWritable(1));
}
}
}
(3)WordCountReducer
package net.suncaper.hadoop;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Long count = 0L;
for (LongWritable value:values) {
count = value.get();
}
context.write(key, new LongWritable(count));
}
}
具体代码解释在下一个连接中,需要大概了解MapReduce程序运行的过程。
五、代码运行
我们需要将我们在Windows上编写的程序打包,然后上传到Ubuntu服务器上运行。
(1)打包我们的文件

完成后,我们可以看到右边有一个target目录,我们只需要其中的.jar包就行。
(2)使用前面提到的FileZilla工具上传我们的文件与jar包,需要处理的数据,可随便上传。

(3)通过命令运行程序。命令如下
hadoop@node-master:/usr/local/hadoop-2.9.2$ hadoop fs -put /usr/local/hadoop-2.9.2/LICENSE.txt /usr/
//这是将你的文件先上传至hadoop服务器中。
hadoop@node-master:/usr/local/hadoop-2.9.2$ yarn jar /usr/local/hadoop-2.9.2/hadoop.bootstrap-1.0-SNAPSHOT.jar net.suncaper.hadoop.WordCount /usr/LICENSE.txt /test
//这是运行WordCount这个程序,处理的文件为,将结果保存至/test,结果依然是在hadoop服务器上。
//如果第二次运行,需要将/test文件删除,命令如下
hadoop@node-master:/usr/local/hadoop-2.9.2$ hadoop fs -rm -r -f /test
(4)查看运行结果,我们可以通过相关网站,查看,也可以在Hadoop服务器上看。网站上面提到过,命令如下
hadoop fs -cat /test/part-r-00000
//这是只有一个分区的时候希望明天能学习如何调试程序,不然一直运行的话,过程较为复杂。















 6820
6820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









