







 本文研究了深度学习在处理长尾分布数据时面临的挑战,提出了特征空间增强方法,利用头部类信息提升尾部类的表现。通过类激活图分解特征,结合头部类的通用特征与尾部类的特定特征,生成增强样本进行微调,实现在多个长尾数据集上的性能提升。
本文研究了深度学习在处理长尾分布数据时面临的挑战,提出了特征空间增强方法,利用头部类信息提升尾部类的表现。通过类激活图分解特征,结合头部类的通用特征与尾部类的特定特征,生成增强样本进行微调,实现在多个长尾数据集上的性能提升。
长尾数据的特征空间增强
ECCV 2020 springer
摘要
现实世界的数据往往遵循长尾分布,因为每个类别的频率通常是不同的。例如,一个数据集可能有大量代表性不足的类,以及少数有足够数据的类。然而,代表数据集的模型通常被期望在不同的类中具有合理的同质性表现。引入类平衡损失和关于数据重新采样和增强的先进方法是缓解数据不平衡问题的最佳做法之一。然而,关于代表性不足的类的另一部分问题将不得不依赖额外的知识来恢复缺失的信息。在这项工作中,我们提出了一种新的方法来解决长尾问题,即用从样本充足的类中学习到的特征来增强特征空间中代表不足的类。特别是,我们利用类的激活图将每个类的特征分解为一个类的通用成分和一个类的特定成分。然后,在训练阶段,通过融合来自代表性不足的类的特定特征和来自混乱类的类属特征,临时生成代表性不足的类的新样本。我们在iNaturalist、ImageNetLT、Places-LT和CIFAR的长尾版本等不同数据集上的研究结果显示了最先进的性能。
1 Introduction
深度神经网络在各种各样的视觉识别任务中显示出相当大的成功。它的有效性和普适性已经被许多最先进的工作[25, 19, 16, 30]和不同行业的各种实际应用所充分证明[6, 49, 3, 12]。然而,通常有一个基本条件,即每个感兴趣的类别都需要得到很好的体现。
量化数据的 "代表性 "本身可能是一个具有挑战性的问题。在实践中,通常使用不同的启发式方法对其进行审查,一个常见的标准是数据集的平衡。事实上,许多公共数据集被有意组织成每一类都有相同数量的样本[33, 24]。对于像分割和检测这样难以保证数据完全平衡的问题,最好是保证良好的数据覆盖率,使稀有类仍有足够的数据,从而得到良好的代表[40, 13]。
然而,现实世界的视觉理解问题通常是细粒度的和长尾的。为了实现人类级别的视觉理解,它几乎意味着能够区分细粒度类别之间的细微差别,并健壮地处理罕见类别[1]的存在。事实上,现实世界数据的这两个属性通常相互伴随,因为大量的细粒度类别经常导致高度不平衡的数据集,
如图2所示。例如,在iNaturalist的物种分类数据集2017[40]中,共有5089个分类,最大的分类超过1000个样本,最小的分类不到10个。在2019年的iNaturalist竞赛中,即使努力过滤掉观测不足的物种,并进一步将最大类大小限制在500个,数据集仍然存在严重的不平衡,因为最小的类大约有10个样本。在其他应用中也可以观察到类似的数据分布,例如基于无人机的目标检测数据集[49]和COCO[28]。
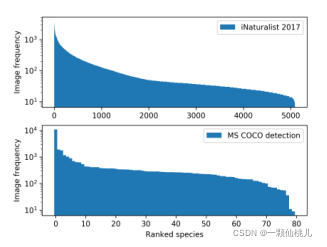
来自不同数据集的每个类别的排序样本量遵循类似的长尾分布。
像许多监督学习算法一样,当训练数据高度不平衡时,深度神经网络的性能也会受到影响[9]。当数据较少的类别被严重采样不足,以至于每个类别内的变化不能被给定的数据完全捕获时,问题会变得更糟[41, 2, 44]。
在现实世界的问题中,长尾数据的普遍存在导致了一些有效的做法,以实现给定机器学习模型的整体性能改进。例如,数据处理,如长尾数据的特征空间增强[4, 14, 10],以及平衡损失函数设计(如焦点损失[27]和类平衡损失[9]),是两种主流方法。这些做法往往能合理地提高性能,然而当某些类别的代表性严重不足时,改进就会恶化,
如图1所示。具体来说,这些方法通常被设计为移动类的决策边界,以减少不平衡的类所带来的偏差。然而,当一个类别的代表性严重不足,以至于很难得出其完整的数据分布时,找到正确的方向来调整决策边界就变得很有挑战性。因此,我们专注于探索从头部类(有充足样本的类)学到的信息,以帮助长尾数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









