







存在的问题&研究动机&研究思路
- 多智能体值函数逼近,本质上来说是一个多任务回归问题。
- MAAC从当前策略中采样动作值,而MADDPG从replay buffer中抽样更新(容易造成overgeneralization)。
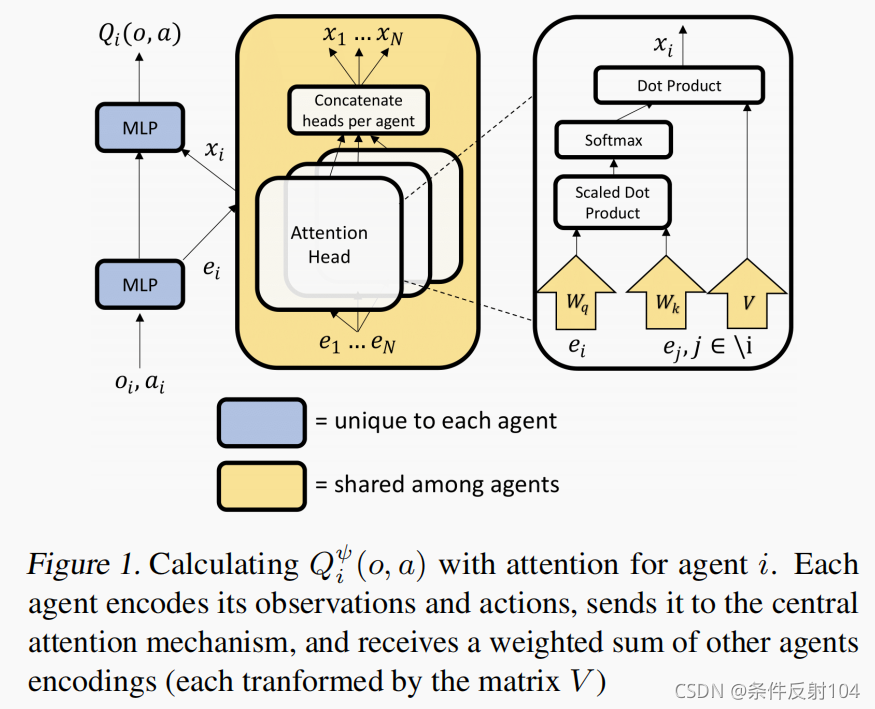
- 通过注意力计算的模型,可以使得每个智能体不需要相同的动作空间,也不需要全局的reward,并且动态的关注其他智能体( α i \alpha_i αi动态变化)。这一切可以通过一个智能体 i i i的编码 e i e_i ei和其他智能体对智能体 i i i的影响 x i x_i xi,concatenate。
创新点
- 遵循CTDE框架,并且通过共享参数的注意力机制来计算critic。(对比ATOC,在策略网络中共享信息,即集中式的策略网络和分散式的critic网络,与MAAC是互补的工作方式。)
- 输入空间随智能体数量的增加而线性增长,而不像MADDPG那样是呈二次增长的。
- 适用于任何奖励设置形式:可适用于只有共同reward的协作环境,也可以用于个体有独立奖励的环境。(协作、竞争、混合式环境皆可。)
- 为了鼓励exploration和避免收敛到非最优的确定性策略,将Actor-Critic替换为Soft Actor-Critic(SAC),损失函数中加入熵。
算法框图
实验
- 实验平台:Cooperative Treasure Collection和Rover-Tower。
- 对比算法:
- DDPG和MADDPG经过Gumbel-Softmax处理为discrete后作为baselines。
- MADDPG和COMA正常版和SAC版。
- 消融实验:MAAC的注意力系数都设置为1/N-1.
- 证明了MAAC算法通过加入attention,使得算法有选择性的重点关注部分智能体,相比于MADDPG+SAC等baseline有较强的scalability。















 3157
3157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









