






-
背景说明
我们都知道自定义source是可以自定义并行度的,数据读写有几个并行度就意味着有几个分区。那么怎么控制我想要的数据流入到指定分区呢?flink1.12官方文档给我们提供了一下几种方式,接下来我们分别进行讨论。
-
partitionCustom分区器
按照官方的原话翻译过来就是使用一个用户自定义的分区策略为每一个元素分配一个目标task。这里的的分区策略官方提到了两种:第一个是下标,第二个是字段。
下面看一个实例
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TestParaPartition {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
test01(env);
env.execute();
}
public static void test01(StreamExecutionEnvironment env){
DataStreamSource<String> elements = env.fromElements("zhangsan", "lisi", "wangwu");
elements.map(new MapFunction<String, Tuple2<String,String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
return Tuple2.of("value is: ", value);
}
}).partitionCustom(new TestPartition(),1)
.map(new MapFunction<Tuple2<String, String>, String>() {
@Override
public String map(Tuple2<String, String> value) throws Exception {
System.out.println("当前线程是:"+Thread.currentThread().getId()+" value is : "+value.f1);
return value.f1;
}
})
.print();
}
}
自定义分区逻辑
import org.apache.flink.api.common.functions.Partitioner;
/**
* 自定义分区器
*/
public class TestPartition implements Partitioner<String> {
@Override
public int partition(String s, int i) {
if("zhangsan".equals(s)){
return 0;
}else if("lisi".equals(s)){
return 1;
}else{
return 2;
}
}
}
-
shuffle分区器
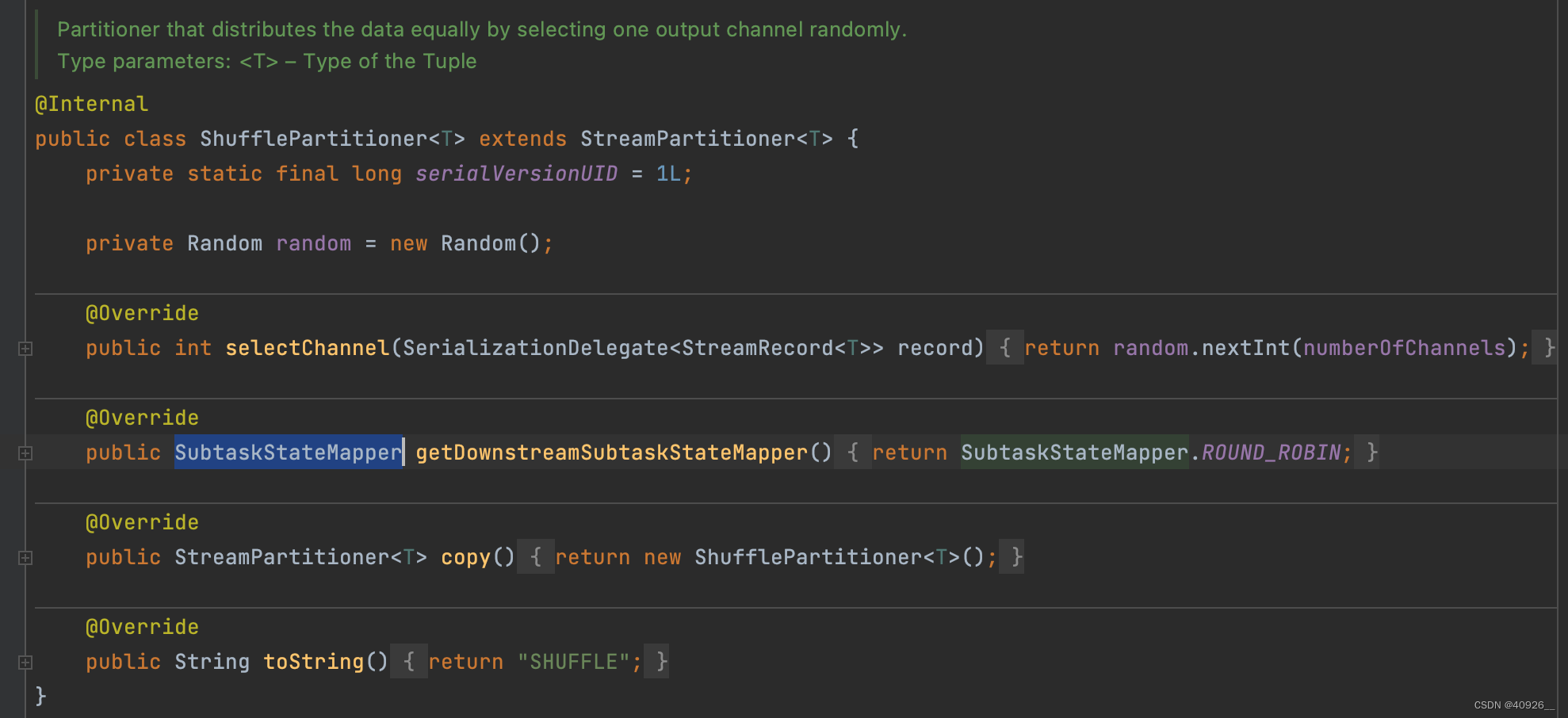
从源码可以看出shuffle分区器自己定义了一个ShufflePartitioner类,此方法里用了随机数将元素随机分配到一个分区里。所以我们无需再定义使用方式,直接调用此分区器即可。 -
rebalance分区器

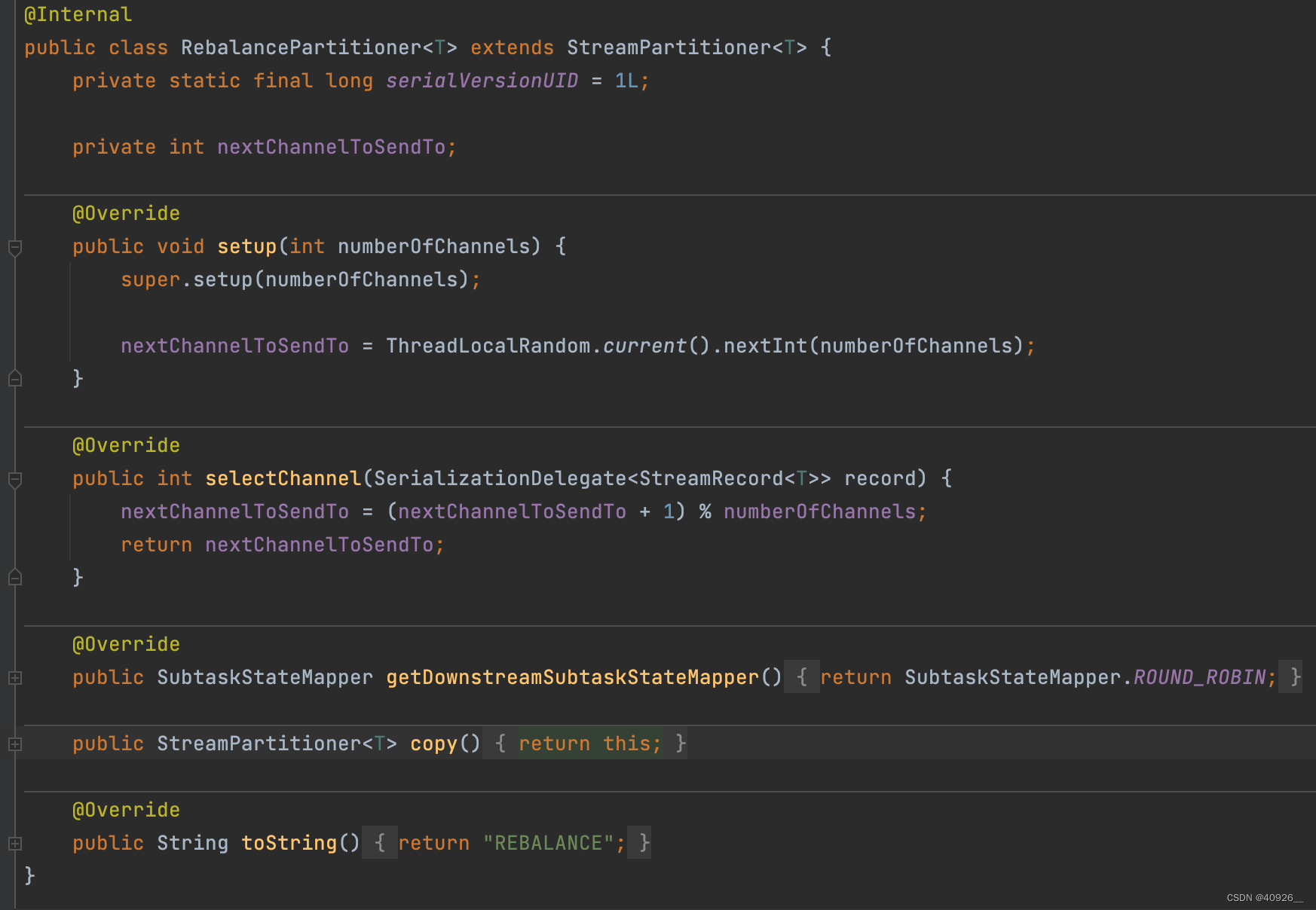
从实现类看出rebalance分区器是第一个元素是随机选择一个分区下发,然后下一个元素通过取模的方式轮询下发。这样就可以将元素均分分布在每一个分区。而shuffle分区器可能会导致数据下发到同一个分区里。使用方式同shuffle分区器直接调用方法即可。 -
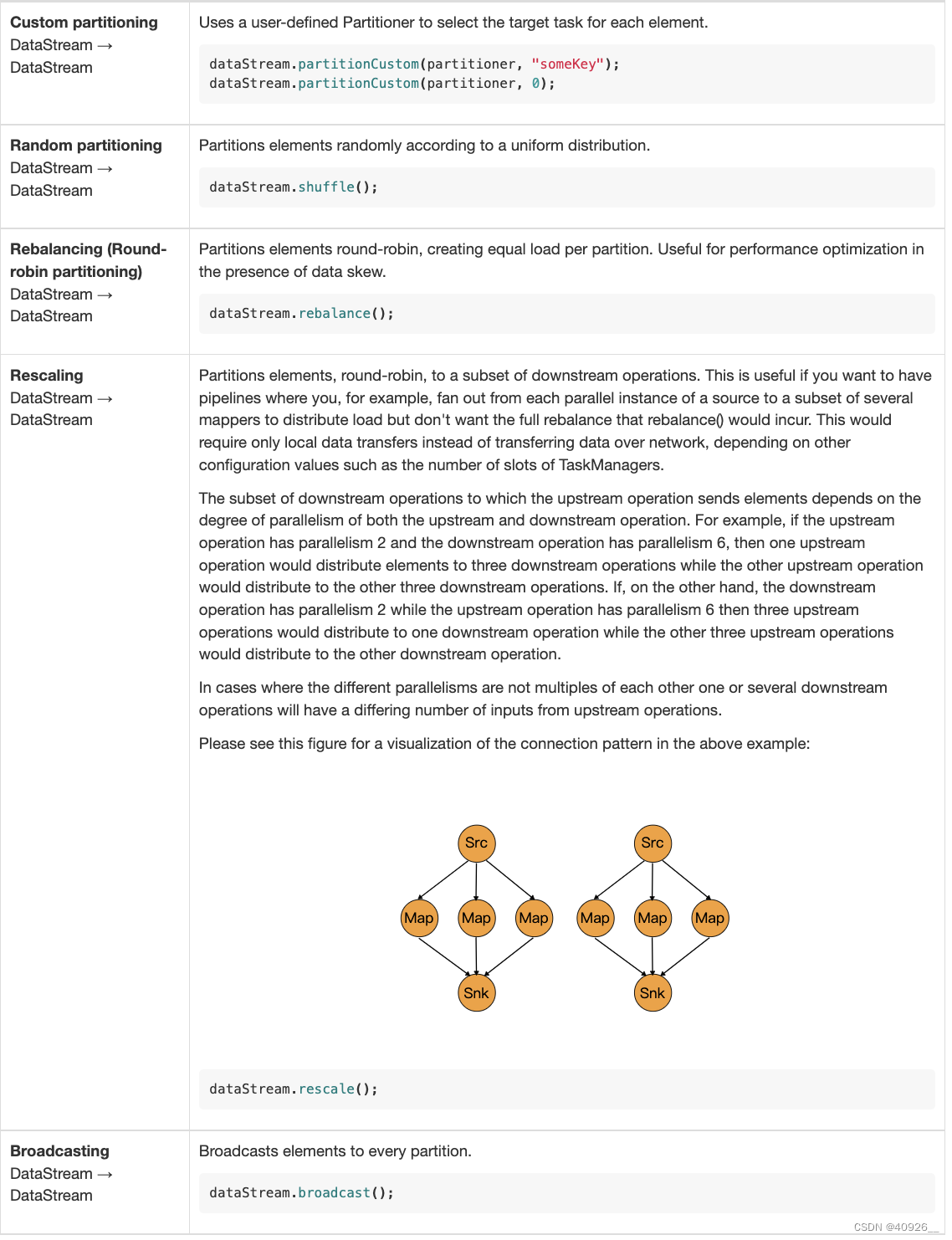
rescale分区器

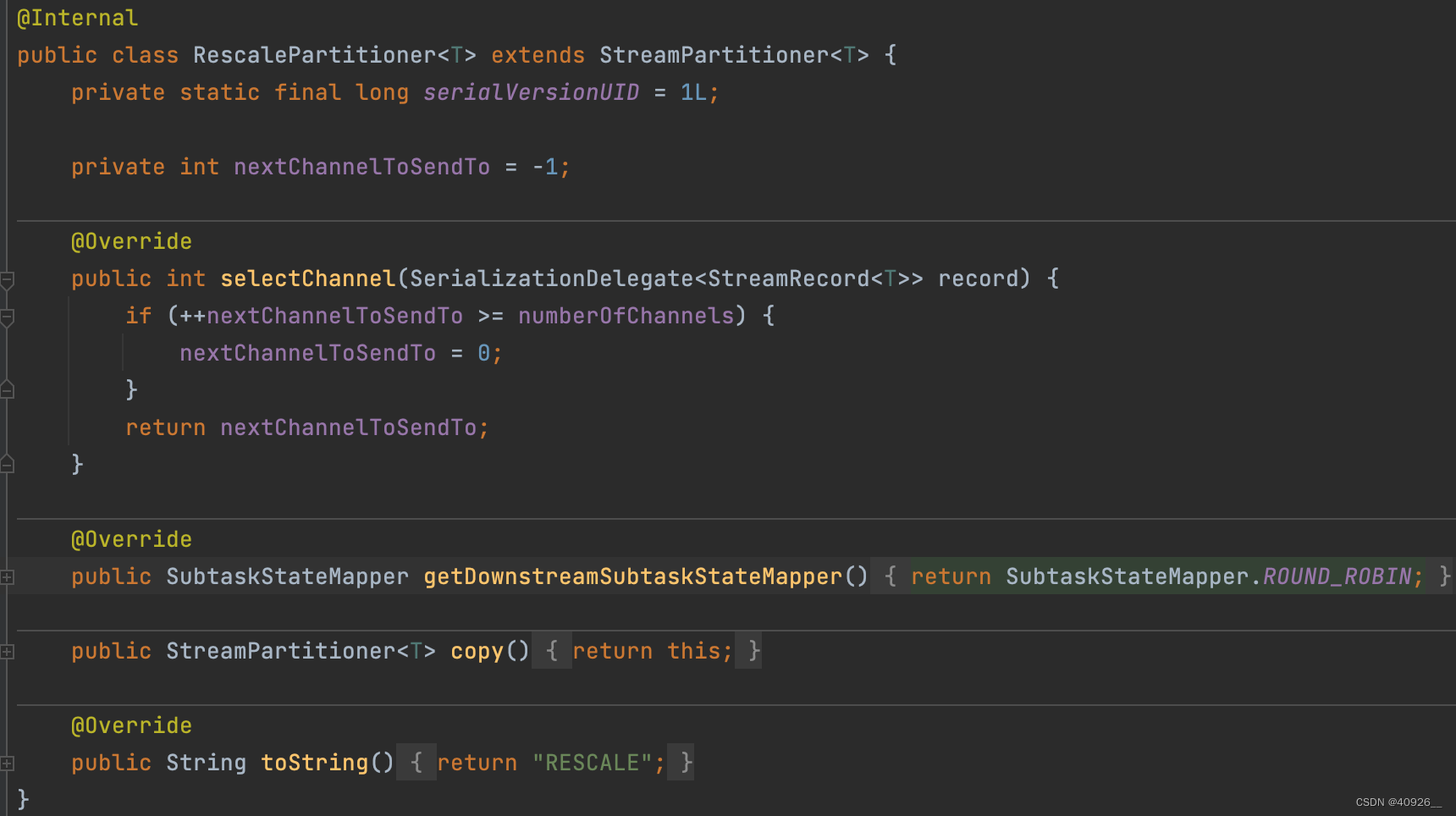
上游操作向其发送元素的下游操作子集取决于上游和下游操作的并行度。例如,如果上游操作具有并行度2,下游操作具有并行性4,则一个上游操作将元素分配给两个下游操作,而另一个上游作业将分配给其他两个下游作业。另一方面,如果下游操作具有并行度2,而上游操作具有并行性4,则两个上游操作将分配给一个下游操作,而另两个上游作业将分配给其他下游操作。
在不同的并行不是彼此的倍数的情况下,一个或多个下游操作将具有来自上游操作的不同数量的输入。
区别于rebalance分区器它是从下游第一个分区开始轮训,而且还是pointwise分发模式。(Flink中有两种分发模式:pointwise 和 all-to-all,两者时间复杂度不同,前者为O(n)后者为O(n)^2,所以在pointwise分发模式下可以减少网络开销。)但对比rebalance分区器其数据均衡性不足。 -
broadcast分区器
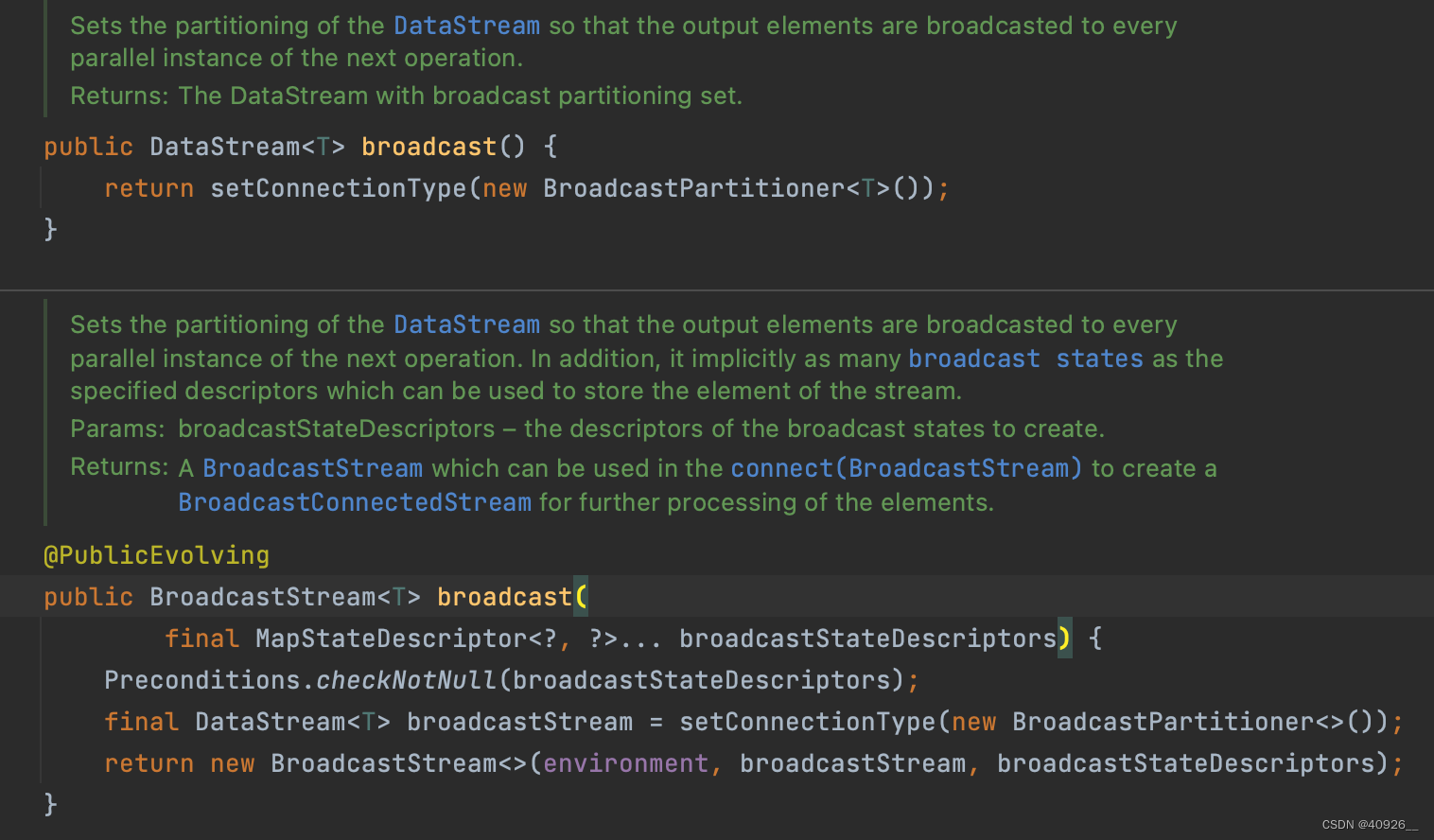
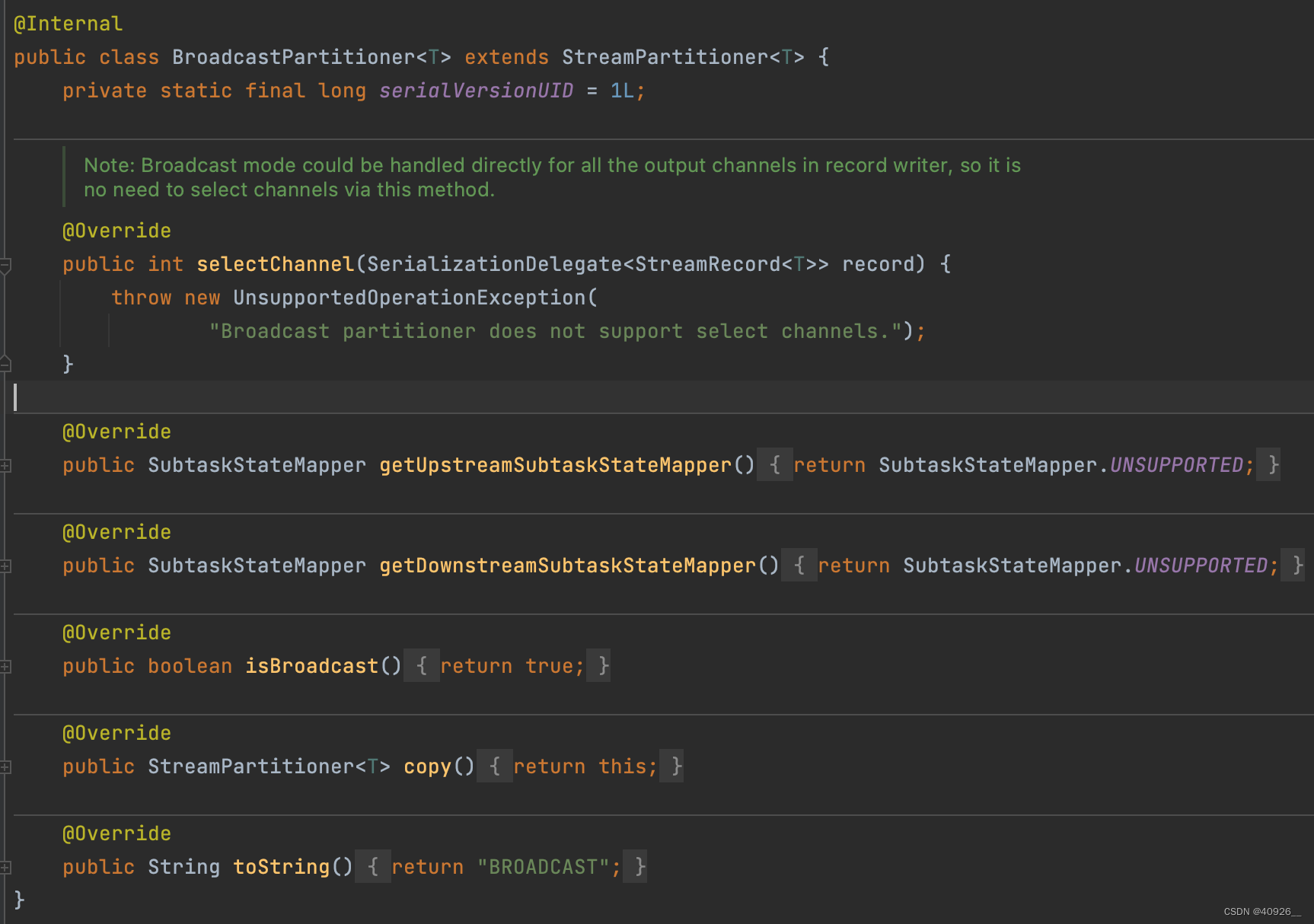
上游所有分区数据会自动给下游所有分区分发一份,分发模式是all-to-all。所以这里官方也提示不支持选择分区。















 7482
7482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









