






概述
众所周知,flink的一个特性是有状态计算,像经常使用的聚合算子sum就是一个有状态计算。flink是来一条数据处理一条数据,如果没有状态管理中间结果,那么每次只会给我们返回当前这条数据结果而不是累加的,这显然不符合我们预期。
状态分类
按照官方给到分类可以划分为:
Keyed State:在KeyedStream中管理状态
Operator State:绑定在一个操作算子中的状态,它主要是一种特殊类型的状态,用于源/接收器实现和场景中,例如在kafka给每个并行度单独管理状态数据。
Broadcast State:Operator State的一种,将需要下发/广播配置、规则等低吞吐事件流到下游所有 task。
而Keyed State的状态又可以细化分为:
ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。
ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List) 进行添加元素,通过 Iterable get() 获得整个列表。还可以通过 update(List) 覆盖当前的列表。
ReducingState: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。和 ReducingState 相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与 ListState 类似,但使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合。
MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用 put(UK,UV) 或者 putAll(Map<UK,UV>) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。你还可以通过 isEmpty() 来判断是否包含任何键值对。
以下是MapState和ValueState实例:
public class AvgWithValueState extends RichFlatMapFunction<Tuple2<Long,Long>,Tuple2<Long,Double>> {
// 求平均数:记录条数 总和
private transient ValueState<Tuple2<Long,Long>> sum;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Tuple2<Long,Long>> avg = new ValueStateDescriptor<>("avg", Types.TUPLE(Types.LONG, Types.LONG));
sum = getRuntimeContext().getState(avg);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Double>> collector) throws Exception {
// TODO... ==> state 次数 和 总和
Tuple2<Long, Long> currentState = sum.value();
if(null == currentState) {
currentState = Tuple2.of(0L,0L);
}
currentState.f0 += 1; // 次数
currentState.f1 += value.f1; // 求和
sum.update(currentState);
// 达到3条数据 ==> 求平均数 clear
if(currentState.f0 >=3 ){
collector.collect(Tuple2.of(value.f0, currentState.f1/currentState.f0.doubleValue()));
sum.clear();
}
}
}
public class AvgWithMapState extends RichFlatMapFunction<Tuple2<Long,Long>,Tuple2<Long,Double>> {
private transient MapState<String,Long> mapState;
@Override
public void open(Configuration parameters) throws Exception {
MapStateDescriptor<String, Long> descriptor = new MapStateDescriptor<String, Long>("avg", String.class, Long.class);
mapState = getRuntimeContext().getMapState(descriptor);
}
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Double>> out) throws Exception {
mapState.put(UUID.randomUUID().toString(), value.f1);
ArrayList<Long> elements = Lists.newArrayList(mapState.values());
if(elements.size() == 3) {
Long count = 0L;
Long sum = 0L;
for (Long element : elements) {
count += 1;
sum += element;
}
Double avg = sum / count.doubleValue();
out.collect(Tuple2.of(value.f0, avg));
mapState.clear();
}
}
}
public class StateApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
test01(env);
env.execute();
}
/**使用valuestate实现平均数*/
public static void test01(StreamExecutionEnvironment env) throws Exception {
ArrayList<Tuple2<Long,Long>> list = new ArrayList<>();
list.add(Tuple2.of(1L,5L));
list.add(Tuple2.of(2L,7L));
list.add(Tuple2.of(1L,4L));
list.add(Tuple2.of(2L,3L));
list.add(Tuple2.of(1L,8L));
list.add(Tuple2.of(2L,2L));
env.fromCollection(list)
.keyBy(x -> x.f0)
//.flatMap(new AvgWithValueState())
.flatMap(new AvgWithMapState())
.print();
}
}
可以看到在使用state的时候是放在增强的flatmap方法里的,这样做的好处就是可以控制state的生命周期。而且写法参考官方给到的,创建一个状态描述器,然后通过runtimecontext上下文对象获取到,如果元素到达三个后通过clear方法清除state。
当然,如果对状态过期处理需要做精细化配置,可以通过ttl进行设置。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);

状态容错
上面介绍了怎样使用状态,但有一个问题就是state默认都存储在程序的jvm里,如果程序异常终止,那么state也会被清除。在生产中这显然是不被允许的,所以flink官方推出checkpoint-状态保存机制。
状态持久化存储方式:
1、jvm里,这个是默认配置
2、filesystem,可以是本地文件系统,也可以是hdfs,s3 等
3、rocksdb轻量化数据库里
使用起来也很方便,在初始化环境的时候就可以进行配置checkpoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 开启在 job 中止后仍然保留的 externalized checkpoints
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//配置checkpoint保存在本地的路径
env.setStateBackend(new FsStateBackend("file:/data/checkpoint/"));
状态实操案例
以下是checkpoint配合重启策略使用。这边需要注意的是,如果任务需要打包提交到集群运行,就需要将以下代码注释。另外在flink集群中找到flink-conf.yaml配置文件中找到backend相关配置,然后做如下修改:
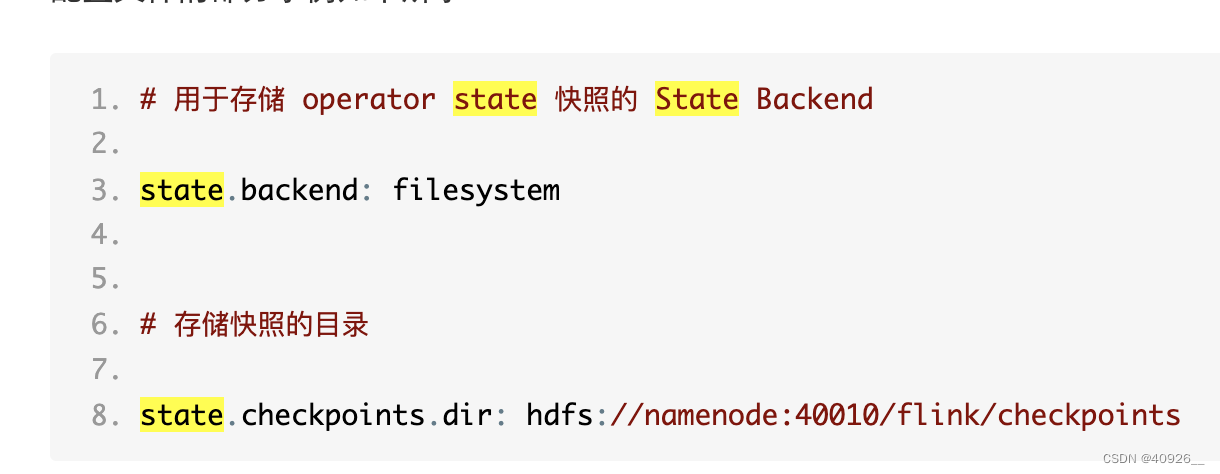
public class StateBackend {
public static void main(String[] args) throws Exception{
//本地模拟根据checkpoint续跑,将ck路径加载到配置里,然后放到env中即可
//Configuration configuration = new Configuration();
//configuration.setString("execution.savepoint.path", "/Users/shuofeng/IdeaProjects/Test/Flink_Project/Flink_BasedApi/src/main/java/com/lxf/data/7256e98b3ec6fe887ee15fbedd91202a/chk-43/");
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setStateBackend(new EmbeddedRocksDBStateBackend());
env.enableCheckpointing(5000);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
/**
* ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态
* ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。
*/
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//env.setStateBackend(new FsStateBackend("file:/Users/shuofeng/IdeaProjects/Test/Flink_Project/Flink_BasedApi/src/main/java/com/lxf/data/checkpoint/"));
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(5, TimeUnit.SECONDS) // 间隔
));
test01(env);
env.execute();
}
private static void test01(StreamExecutionEnvironment env) {
DataStreamSource<String> source = env.socketTextStream("110.40.173.142", 9633);
source.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
if(s.contains("DK")){
throw new RuntimeException("ERROR....");
}else {
return s.toLowerCase();
}
}
}).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] split = s.split(",");
for (String s1 : split) {
collector.collect(s1);
}
}
}).map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s,1);
}
}).keyBy(x -> x.f0)
.sum(1)
.print();
}
}
利用maven打包后可以将jar上传至flink的lib下,然后在bin目录下执行:./flink run -c com.lxf.state.StateBackend -s /usr/local/soft/flink-checkpoints/7256e98b3ec6fe887ee15fbedd91202a/chk-43 ~/lib/Flink_BasedApi-1.0-SNAPSHOT.jar
然后按照最新的checkpoint续跑即可。














 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









