






代码运行教程:https://blog.csdn.net/qq_40343117/article/details/100363101
1、环境变量
首先右键我的电选择属性,打开高级系统设置
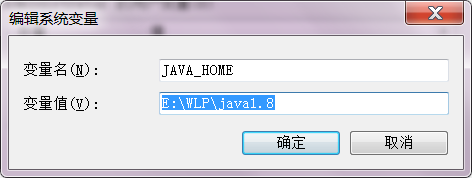
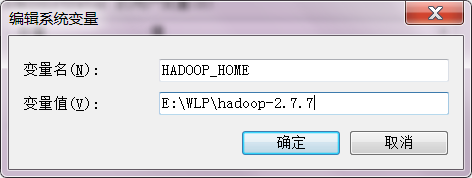
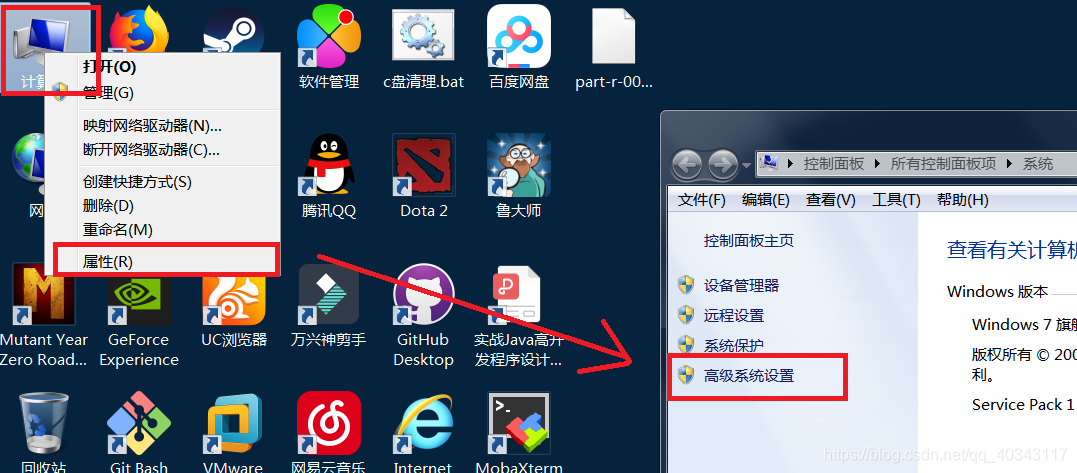 打开找到环境变量,在右边的系统变量中新建JAVA_HOME 和 HADOOP_HOME 如下,就名字是这个,内容是你解压后的java和hadoop 的文件夹路径。
打开找到环境变量,在右边的系统变量中新建JAVA_HOME 和 HADOOP_HOME 如下,就名字是这个,内容是你解压后的java和hadoop 的文件夹路径。
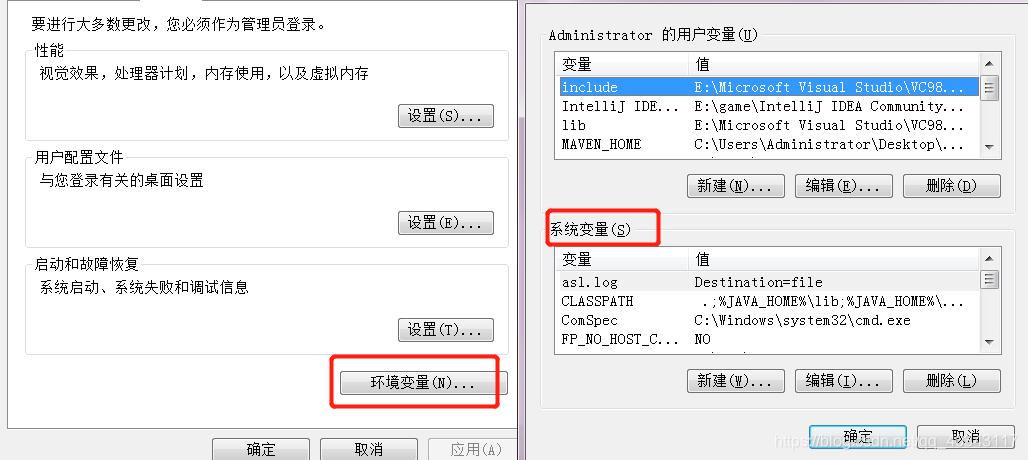
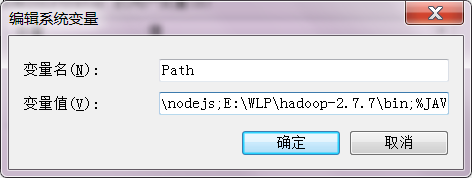
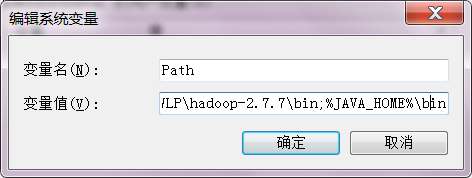
再找到Path,在里面添加设置好的java_home和hadoop_home
(下图第一个是我们用绝对路径指定的,第二个是java_home指定的,因为path的内容很多,虽然两种方法都可以,不过不推荐第一种,因为你设置好了java_home之后,更新java版本只要更新java_home就可以了,他只对应这么一个参数,而第一种你要自己再找到,一旦改错了,你的环境可能就出错了,甚至有些系统功能都无法使用了。)
2、配置IDEA
2.1 导入jar包
1、更新jar包
这一步看大家个人情况,由于我解压的都是我在载安装在虚拟机的liuix版本的hadoop,所以解压完成之后需要去王宏说那个找到对应的windoes版本的lib文件夹,复制进去
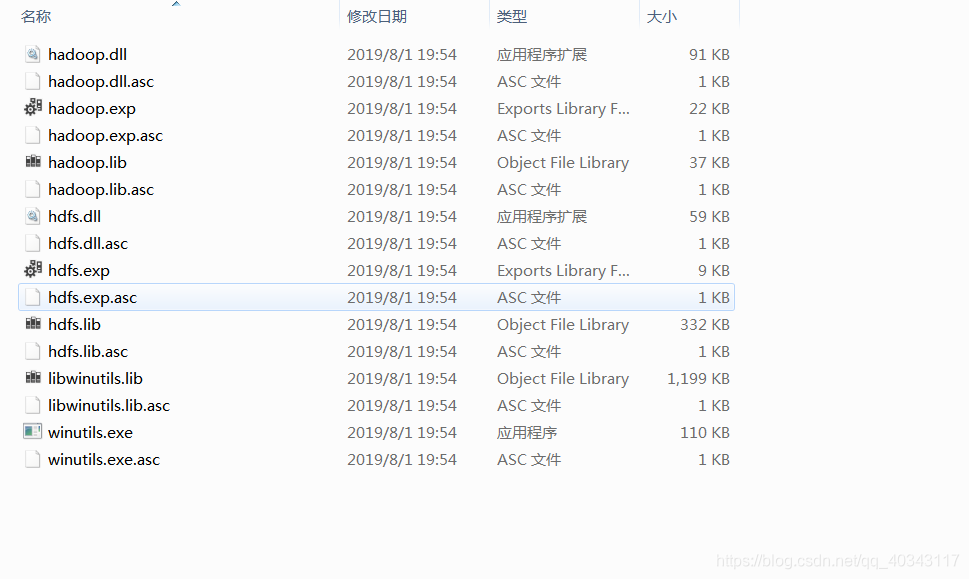
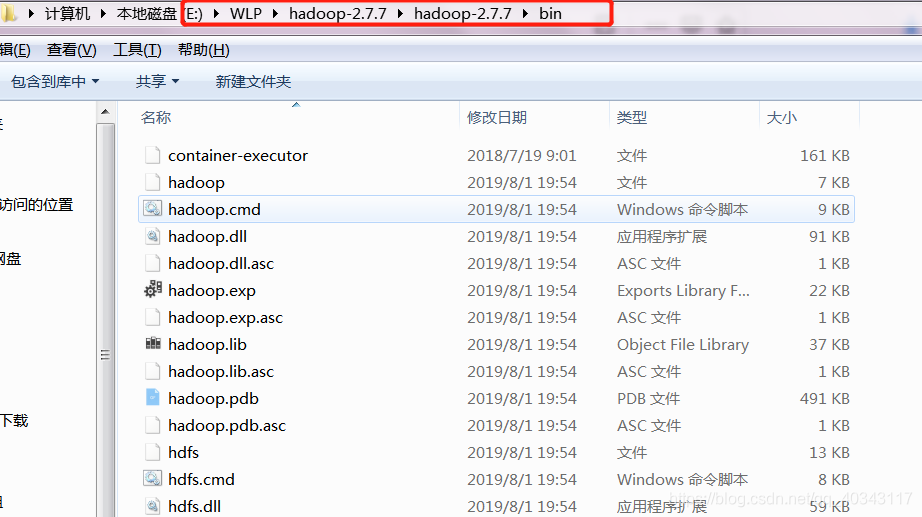 注意可能会有一样的文件出现,这时我们选择不要复制,意思就是吧windows版bin有的复制进来,但已经存在的不要更改版本,因为我找到的几个里没有完美符合我的版本的,我不同版本的,到现在暂时没什么问题。
注意可能会有一样的文件出现,这时我们选择不要复制,意思就是吧windows版bin有的复制进来,但已经存在的不要更改版本,因为我找到的几个里没有完美符合我的版本的,我不同版本的,到现在暂时没什么问题。
windows版bin下载地址:https://pan.baidu.com/s/1tk8eYCTp1tvwclS1k4zENg
提取码:r5ec
2.新建项目
选择file——newproject

选择MAVEN,右边选择你java的路径,点击new找到你的java_home路径就可以
(下面是我之前配置过的,为了演示我就不用了,我们重新配置)
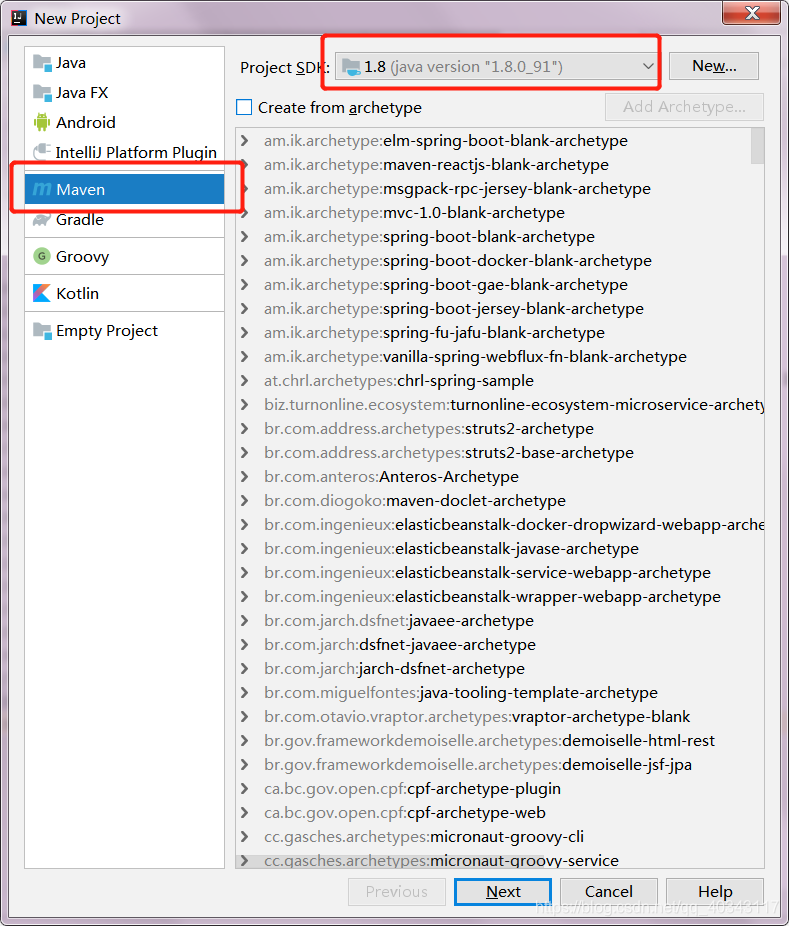 填写自己想起的名字就行
填写自己想起的名字就行
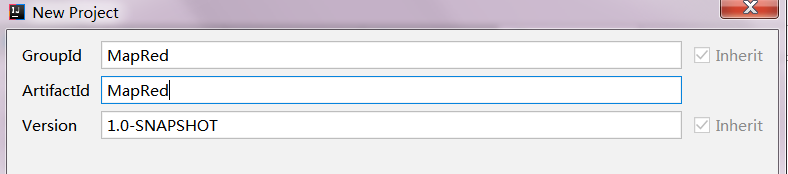 上一步填好了这一步默认就可以,然后点击finsh
上一步填好了这一步默认就可以,然后点击finsh
(当然没有讲过项目的不推荐把项目建在C盘桌面,虽然很好找,但是我们要是一直会更新学习内容的话,这个项目也会越来越大,当C盘快满了,就会导致电脑性能低下)
 3.借助maven导入jar包
3.借助maven导入jar包
我们建好项目会看到相比平常的java项目这里多了pom.xml文件,我们双击打开
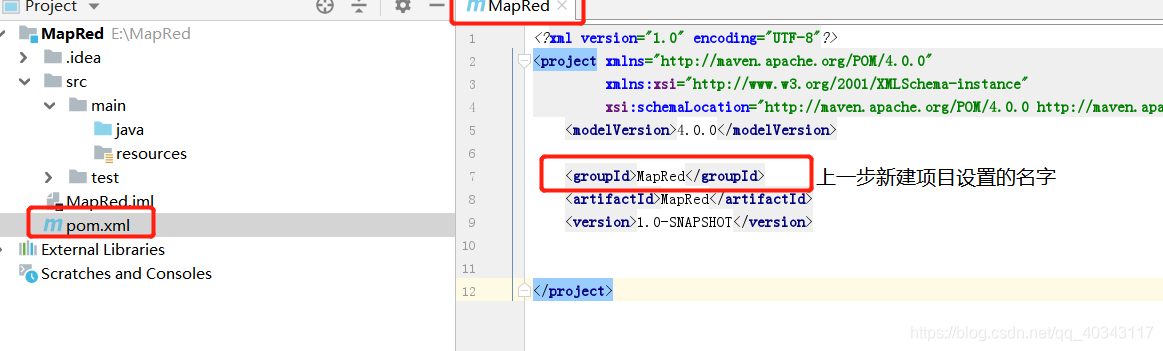
打开之后我们输入如下信息进行jar包的下载
注意这里的hadoop版本一定更换成自己电脑配置好的版本
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>6</source>
<target>6</target>
</configuration>
</plugin>
</plugins>
</build>
<packaging>jar</packaging>
<name>MapRed</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
</project>
注:build上面的用自己的就行

 复制完成后右下方会出现下图,我是配置过了所以选import changes,没配过的直接下载就可以了,然后就会出现读条,下完了就行。
复制完成后右下方会出现下图,我是配置过了所以选import changes,没配过的直接下载就可以了,然后就会出现读条,下完了就行。

4.导入配置文件
进入虚拟机的hadoop文件夹,找到core-site/hdfs-site,放到项目src——resource下面
(hbse是我自己需要的,mapreduce没必要放进去)
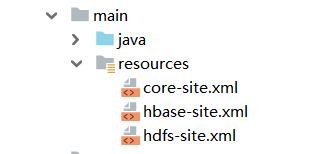
3、完成配置
配置完成,我们尝试编写一个wordcount,首先可以检测的一点就是你在idea中输入我们如下的代码会有提示,类是apche.hadoop…什么的,这就成功一半了。














 6065
6065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









