






简介
ES是一个分布式高扩展基于lucense的实时全文搜索引擎,基于RestFul风格的API调用。
ES安装
环境要求: 1.8jdk、NodeJS(ELK需要)
Windows安装
ElasticSearch
注:ES版本7.6.2
-
解压即可
-
目录讲解
# 启动文件
bin
# 配置文件
config
#虚拟机配置 如果是服务器内存小需要修改默认启动内存(注:默认启动内存是1G)
jvm.options
#日志配置
log4j2.properties
#es配置文件 9200默认端口
elasticsearch.yml
# 运行所需环境
jdk
# 依赖
lib
#日志
logs
#功能模块
modules
#插件
plugins
- 运行ES
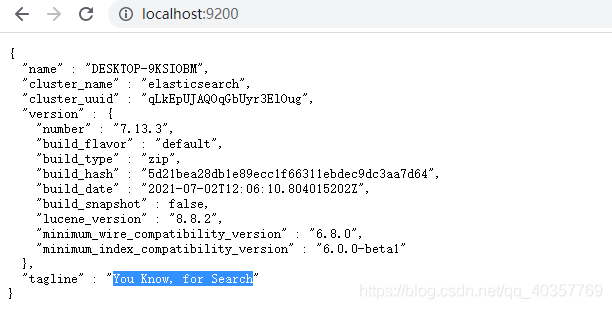
- 访问
Kibana
注:需要和ES版本保持一致
Kibana是一个针对ES的开源分析及可视化平台,用来搜索,查看交互存储在ES索引中的数据。使用Kibana可以通过图表进行高级数据分析及展示。
-
下载相对于ES版本的Kibana(注:需要Node环境)
-
开放es的跨域请求找到Elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
-
启动Kibana

-
访问
-
图形化查找(之后的所有查找都在这里编写)
-
配置国际化
找到Kibana.yml 添加:i18n.locale: “zh-CN” 然后重启
ES核心概念
ElasticSearch是面向文档的,关系型数据库和ElasticSearch对比
注:es8之后的版本将启用type字段
| Mysql | ElasticSearch |
|---|---|
| 数据库(databases) | 索引(indexs) |
| 表(table) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
物理设计:
ElasticSearch在后台把每个索引划分成多个分片;每个分片可以在集群中的不同服务器迁移
一个人就是一个集群!默认的集群名称就是elasticsearch
倒排索引:
是es快速的原因,他会把每个词做分离然后根据关键词去匹配,关键字命中多的权重就高,排序就高
IK分词器
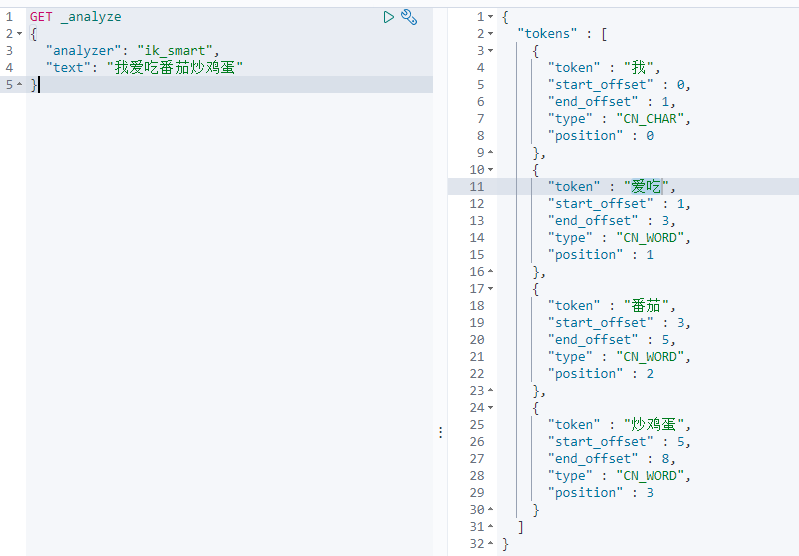
分词器是将一段中文划分成一个个的关键字,而默认的中文分词会将每个字看成一个词,搜索出来的效果就很不尽如人意。例如:我爱吃番茄炒鸡蛋,IK分词就会分成类似爱、吃、番茄、炒鸡蛋这几个关键词
安装
- 找到对应的版本然后下载
- 将下载的文件解压到plugins文件下
- 然后重启kibana和ES
IK_SMART(最少切分算法)
IK_MAX_WORD(最细粒度划分)
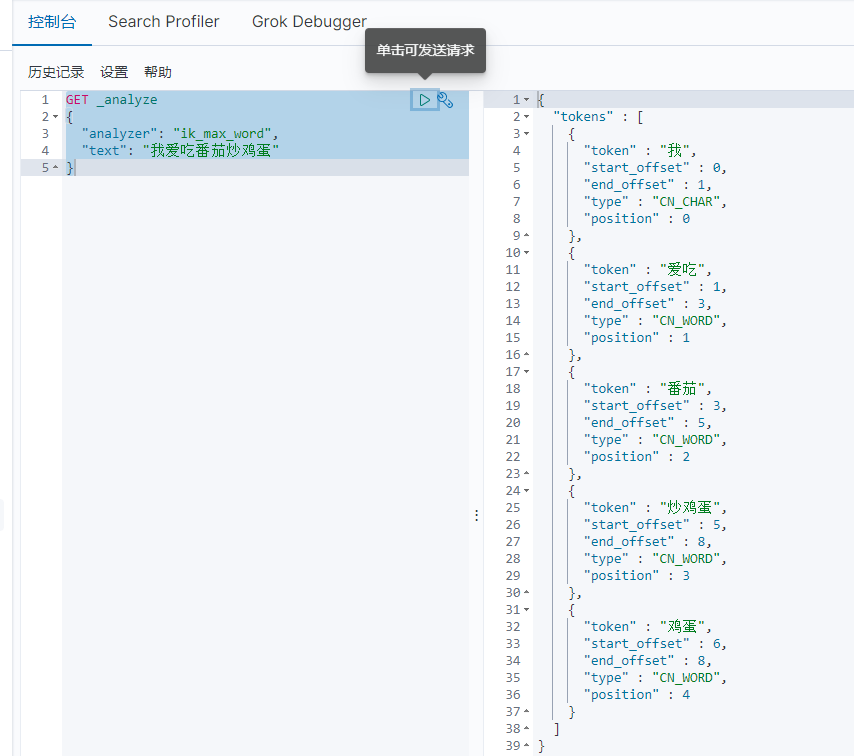
总结:这里比较来看ik_max_word分出来的词汇更加的细致
自定义ik词典
这里我们会发现如果输入当下流行的网络热词的话并没办法进行分词,这里我们就可以自定义词典来适应当代的新潮流词汇
-
找到ik的config目录创建my.dic
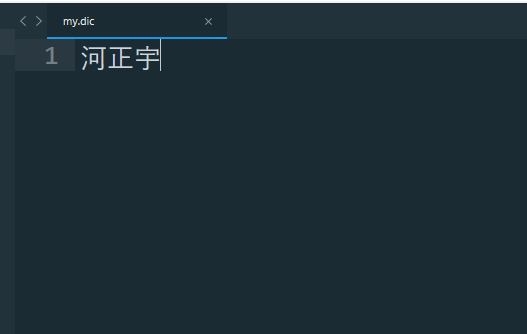
-
打开IKAnalyzer.cfg.xml添加my.dic
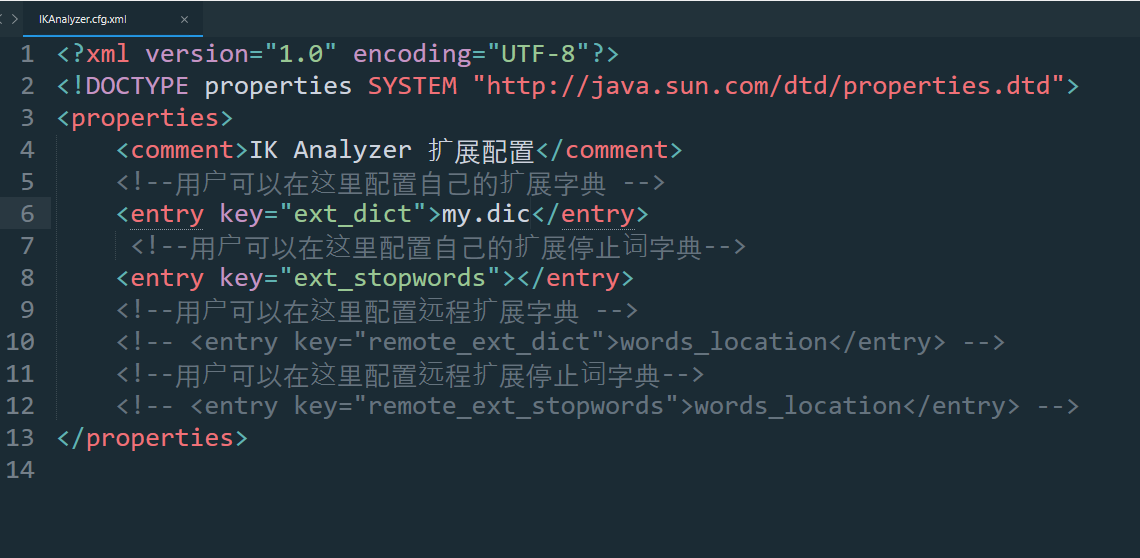
-
重启ES
-
访问发现配置已经生效
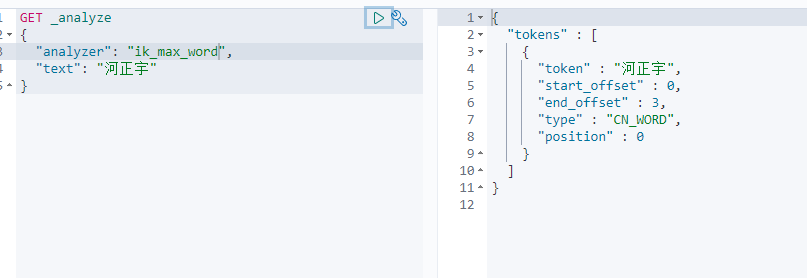
索引基本操作
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引/类型名称 | 创建文档(随机id) |
| POST | localhost:9200/索引/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引/类型名称/文档id | 根据id查询文档 |
| POST | localhost:9200/索引/类型名称/_search | 查询所有数据 |
添加一个xiye的索引、goods类型、id为1的商品
PUT /xiye/goods/1
{
"goodsname":"西红柿",
"price":"29"
}
指定索引字段和类型
PUT xiye2
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"long"
}
,
"birthday":{
"type":"date"
}
}
}
}
注: 如果没给定类型名es会创建一个_doc的默认类型
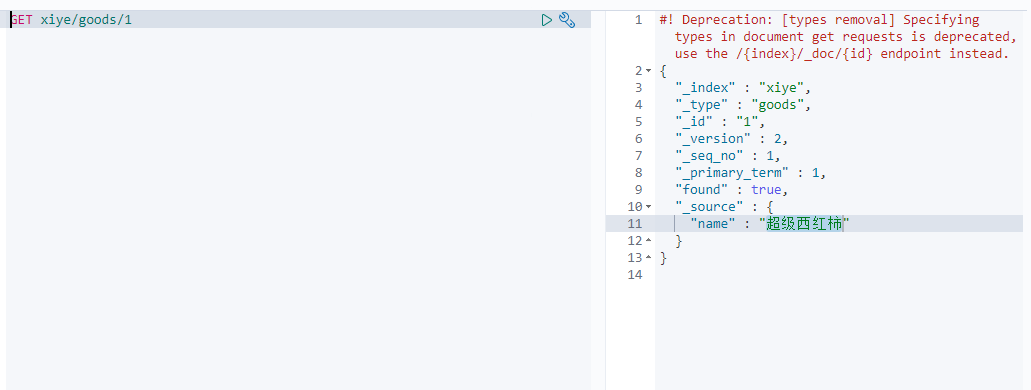
修改es数据
POST xiye/goods/1
{
"name":"超级西红柿"
}
发现name值已经改变
删除
DELETE xiye/goods/1
注 :如果只写xiye 就删除所有索引 写索引和类型 就删除全部的类型 具体到id 就删除精确的id值
文档查询操作(重点)
重点理解:
- match是将搜索的字分词
- term不将搜索的字进行分词
- text 类型在存储时已经分词
- keyword 类型在存储的时候不会分词
添加假数据
PUT xiye/user/1
{
"name":"张麻子",
"age": 19,
"love":["吃饭","交友","唱歌"],
"tag":["麻匪","好人","聪明"]
}
PUT xiye/user/2
{
"name":"汤师爷",
"age":28,
"love":["敛财","美女","权力"],
"tag":["伪善","学士","装糊涂"]
}
PUT xiye/user/3
{
"name":"黄四郎",
"age":39,
"love":["钱","敛财","聪明"],
"tag":["杀人诛心","心机"]
}
PUT xiye/user/4
{
"name":"张麻子copy",
"age": 13,
"love":["吃饭","交友","唱歌"],
"tag":["麻匪","好人","聪明"]
}
根据name 分词查询
GET xiye/user/_search
{
"query": {
#match 分词查找
"match": {
"name":"张麻子"
}
}
#只显示那些字段
, "_source": ["age","name"]
}
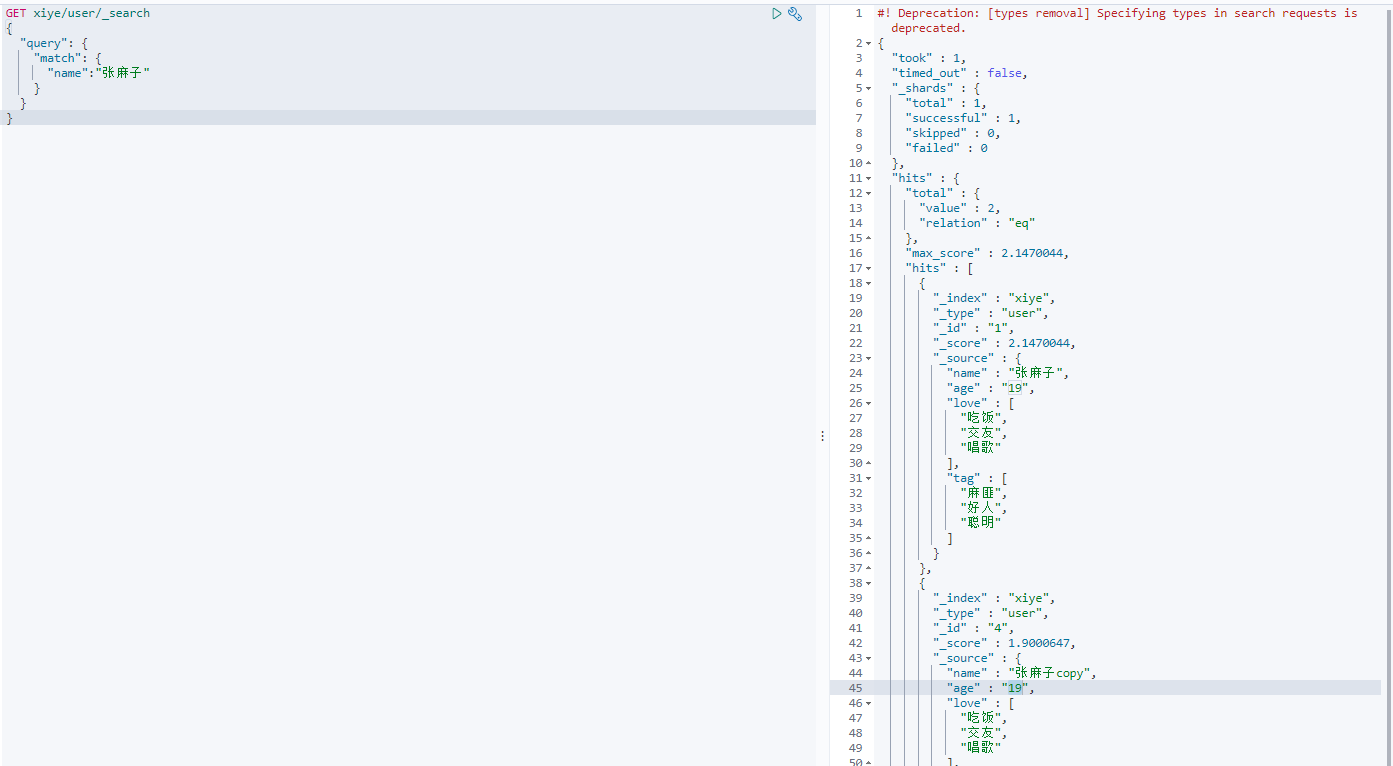
注: 当出现多条匹配的数据时 _score越高 权重就越高展示的优先级就越高
排序
排序:注意要排序的字段需是long类型
GET xiye/user/_search
{
"query": {
"match": {
"name": "张麻子"
}
},
#根据age字段升序
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
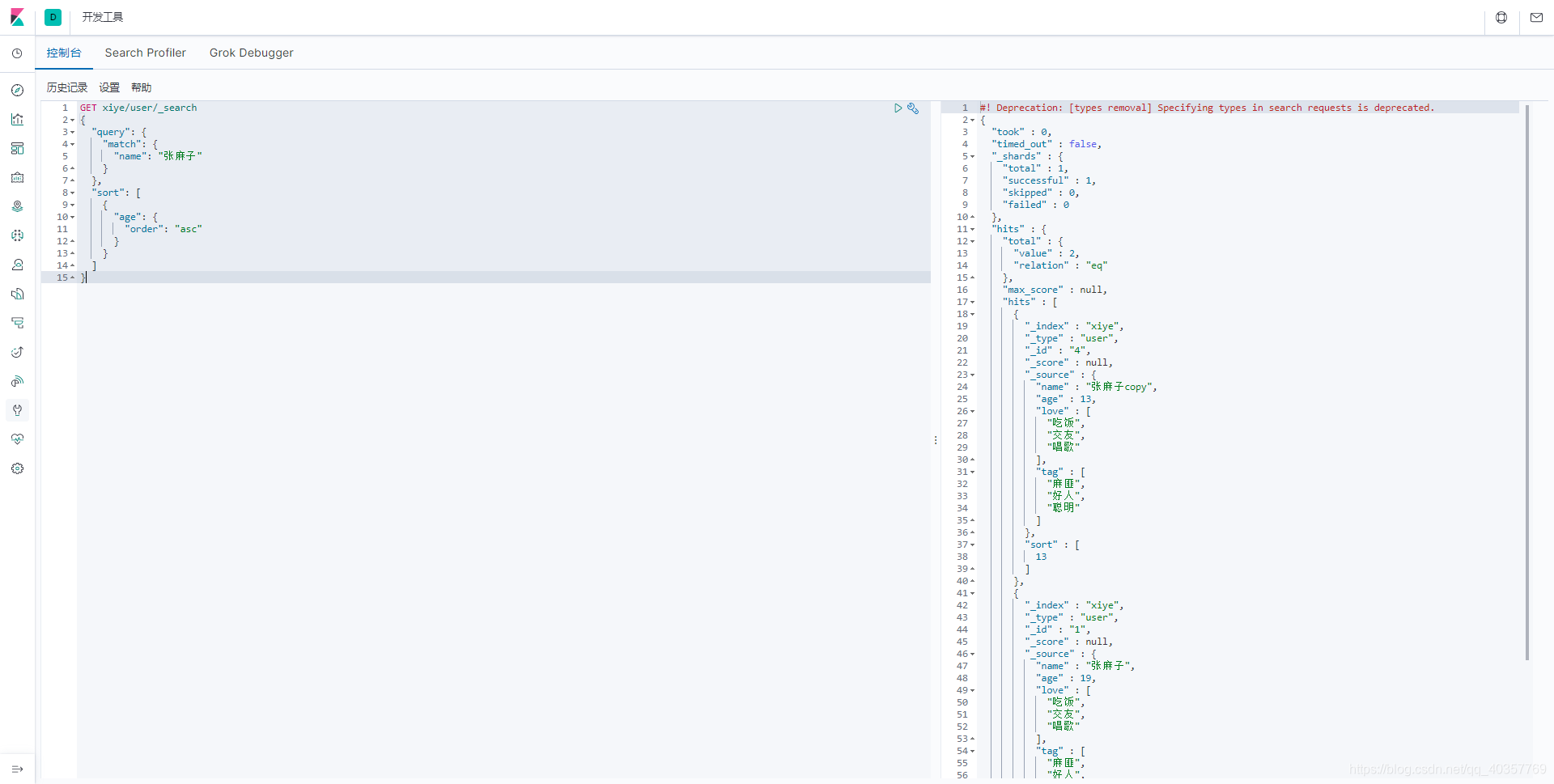
分页
类似mysql limit
GET xiye/user/_search
{
"query": {
"match": {
"name": "张麻子"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
#limit 的start
"from": 0,
#limit 显示多少数据
"size": 20
}
多条件查询
must 类似mysql and
shoult 类似mysql or
must_not 类似mysql !=
GET xiye/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张麻子"
}
},
{
"match": {
"age": "19"
}
}
]
}
}
}
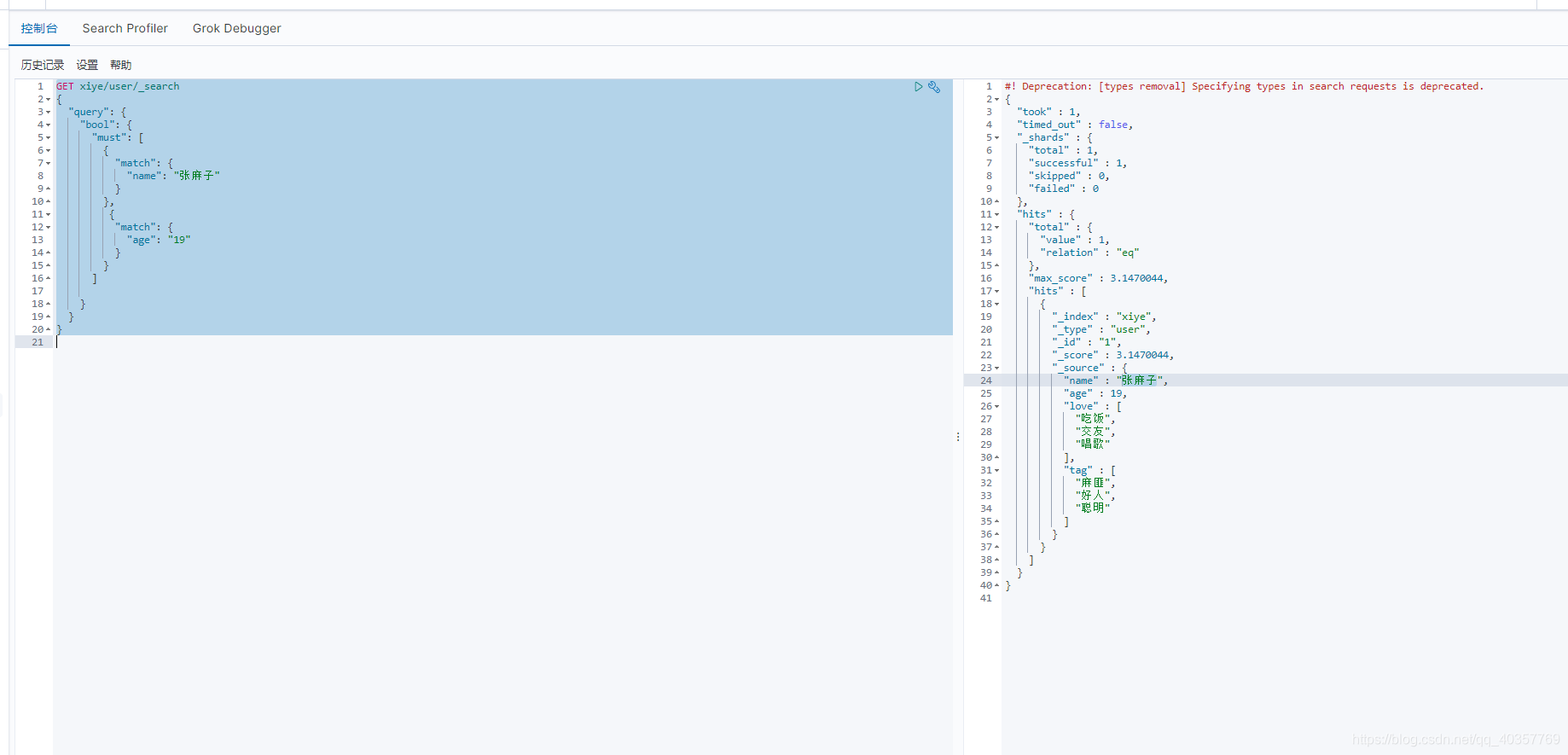
查询结果年龄大于10小于20的数据
GET xiye/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张麻子"
}
}
]
, "filter": [
{"range": {
"age": {
"gte": 10,
"lte": 20
}
}}
]
}
}
}
单字段匹配多条件查询
多条件按空格分割查询
GET xiye/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"tag": "好人 匪"
}
}
]
}
}
}
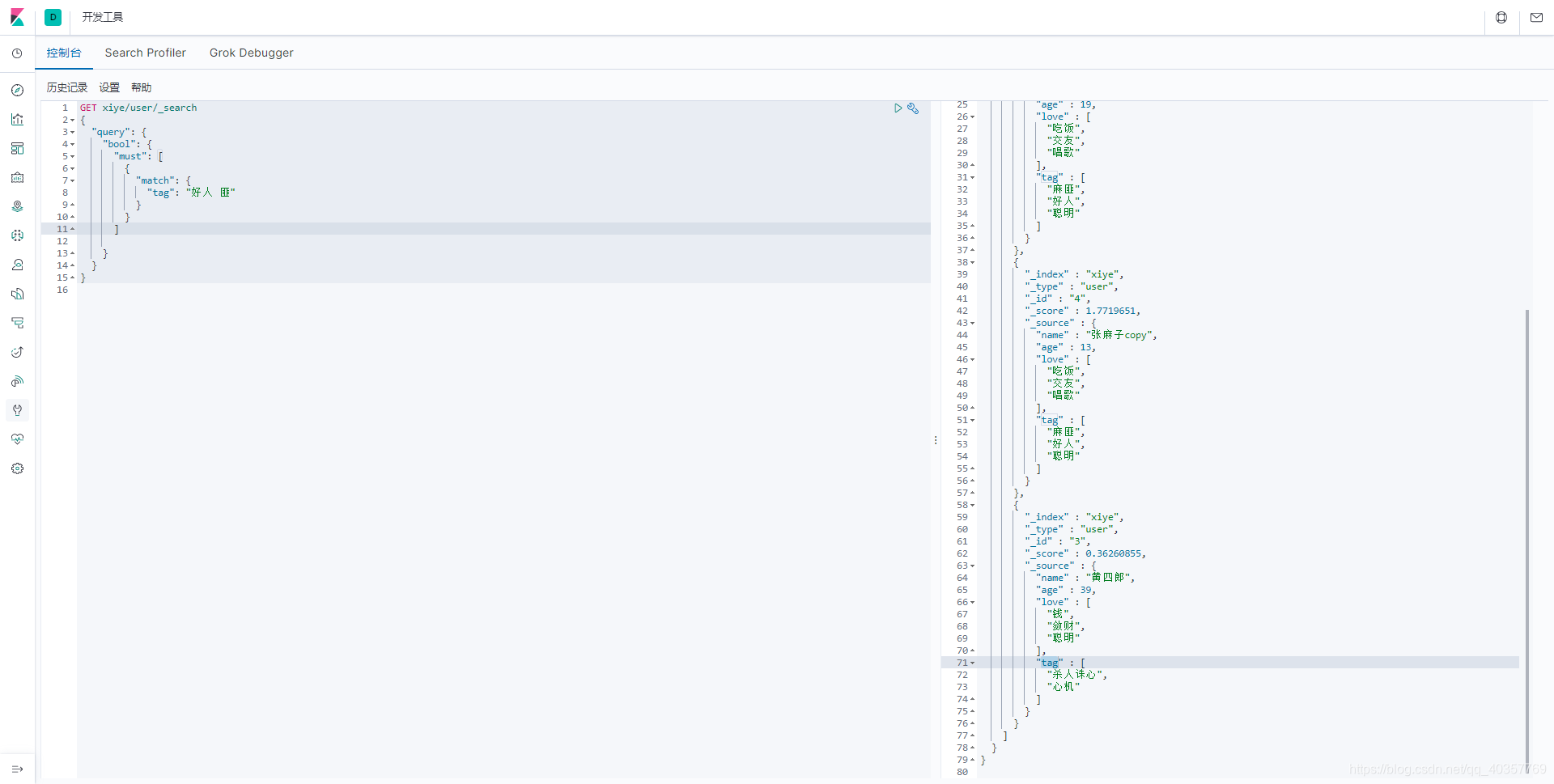
精确查询
注:需要精确查找需要满足term+keyword 类型的字段两个条件
#设计表结构
PUT xiye3
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"desc":{
"type":"keyword"
}
}
}
}
#添加模拟数据
PUT xiye3/_doc/1
{
"name":"范源鑫",
"desc":"我是一个粉刷匠"
}
PUT xiye3/_doc/2
{
"name":"范仲淹",
"desc":"我是一个粉刷匠123"
}
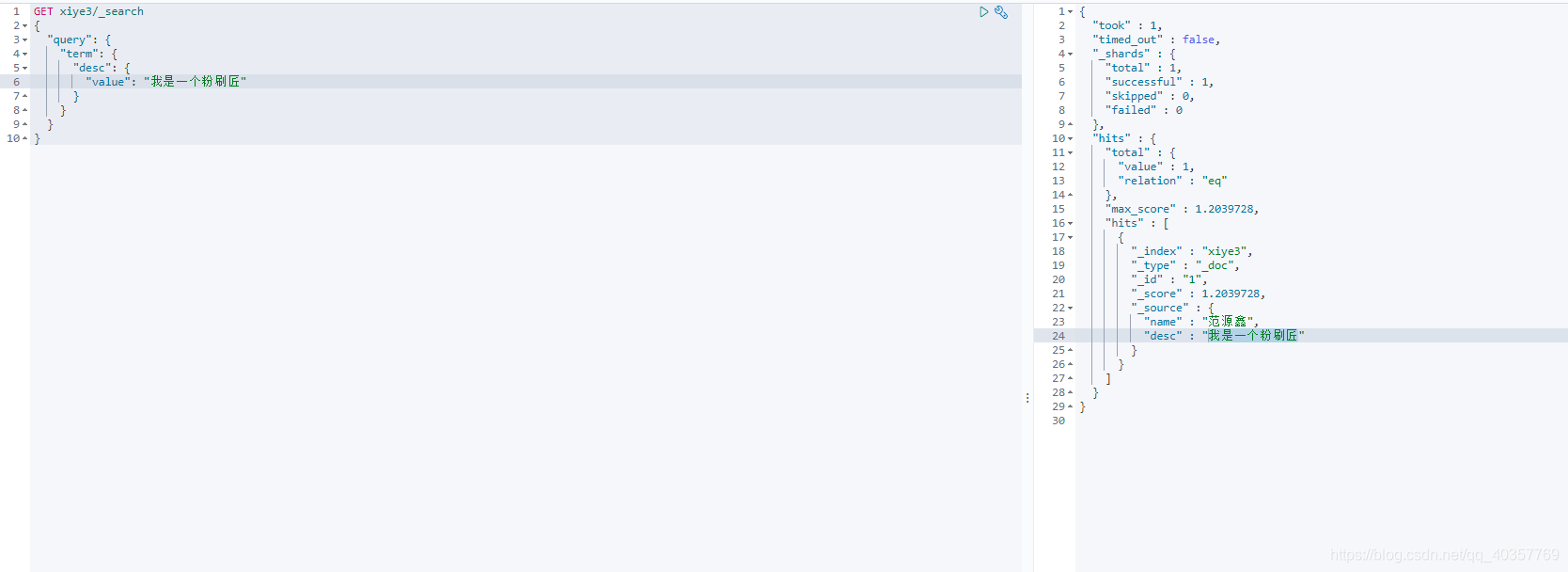
#精确查询
GET xiye3/_search
{
"query": {
"term": {
"desc": {
"value": "我是一个粉刷匠"
}
}
}
}
高亮查询
GET xiye3/_search
{
"query": {
"match": {
"name": "范源鑫"
}
},
"highlight": {
#定义标签前缀 可自定义
"pre_tags": "<h2>",
#定义标签后缀 可自定义
"post_tags": "</h2>",
# 高亮的字段
"fields": {
"name": {}
}
}
}
SpringBoot集成ES
参考网络其它文章















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









