







安装IK分词器
使用IK分词器可以实现对中文分词的效果。
下载IK分词器:(Github地址:https://github.com/medcl/elasticsearch-analysis-ik)
下载后解压,并将解压的文件拷贝到ES安装目录的plugins下的ik(重命名)目录下,重启es
测试分词效果
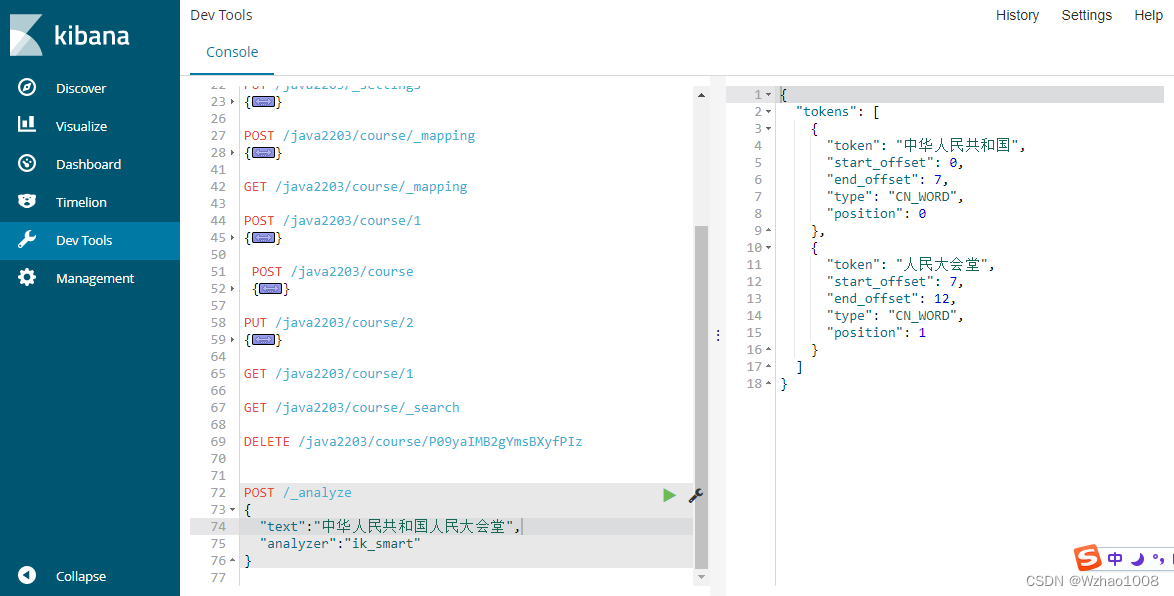
POST /_analyze
{
"text":"中华人民共和国人民大会堂",
"analyzer":"ik_smart"
}
结果
两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民大会堂、人民、共和国、大会堂、大会、会堂等词语。
结果

2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
第一次测试就用的这个
自定义词库
如果要让分词器支持一些专有词语,可以自定义词库
搜索奥利给 结果
iK分词器自带的…/plugins/ik/config/main.dic的文件为扩展词典,stopword.dic为停用词典。
传输下来修改
在main.dic中添加词
注意文件格式保存为为utf-8(不要选择utf-8 BOM)
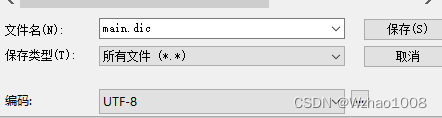
传输覆盖原有文件
重启服务之后再次运行
field详细介绍
上边安装了ik分词器,如何在索引和搜索时去使用ik分词器呢?如何指定field的类型?比如日期类型、数值类型等。
ES6.2核心的字段类型:

field的属性介绍
type
通过type属性指定field的类型。
"name":{
"type":"text"
}
上边指定了analyzer是指在索引和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过
search_analyzer属性。
对于ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性
"name": {
"type": "text",
"analyzer":"ik_max_word", #生成索引目录时
"search_analyzer":"ik_smart" #检索时
}
index
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置
为false。
删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据
"pic": {
"type":"text",
"index":false
}
source
如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,比如:商品描述。查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。
如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如
POST /java06/course/_mapping
{
"_source": {
"includes":["description"]
}
}
同样,可以通过excludes参数排除某些字段:
POST /java06/course/_mapping
{
"_source": {
"excludes":["description"]
}
}
常用field类型
text文本字段
创建新映射:
POST /java2203/course/_mapping
{
"_source": {
"includes":["description"]
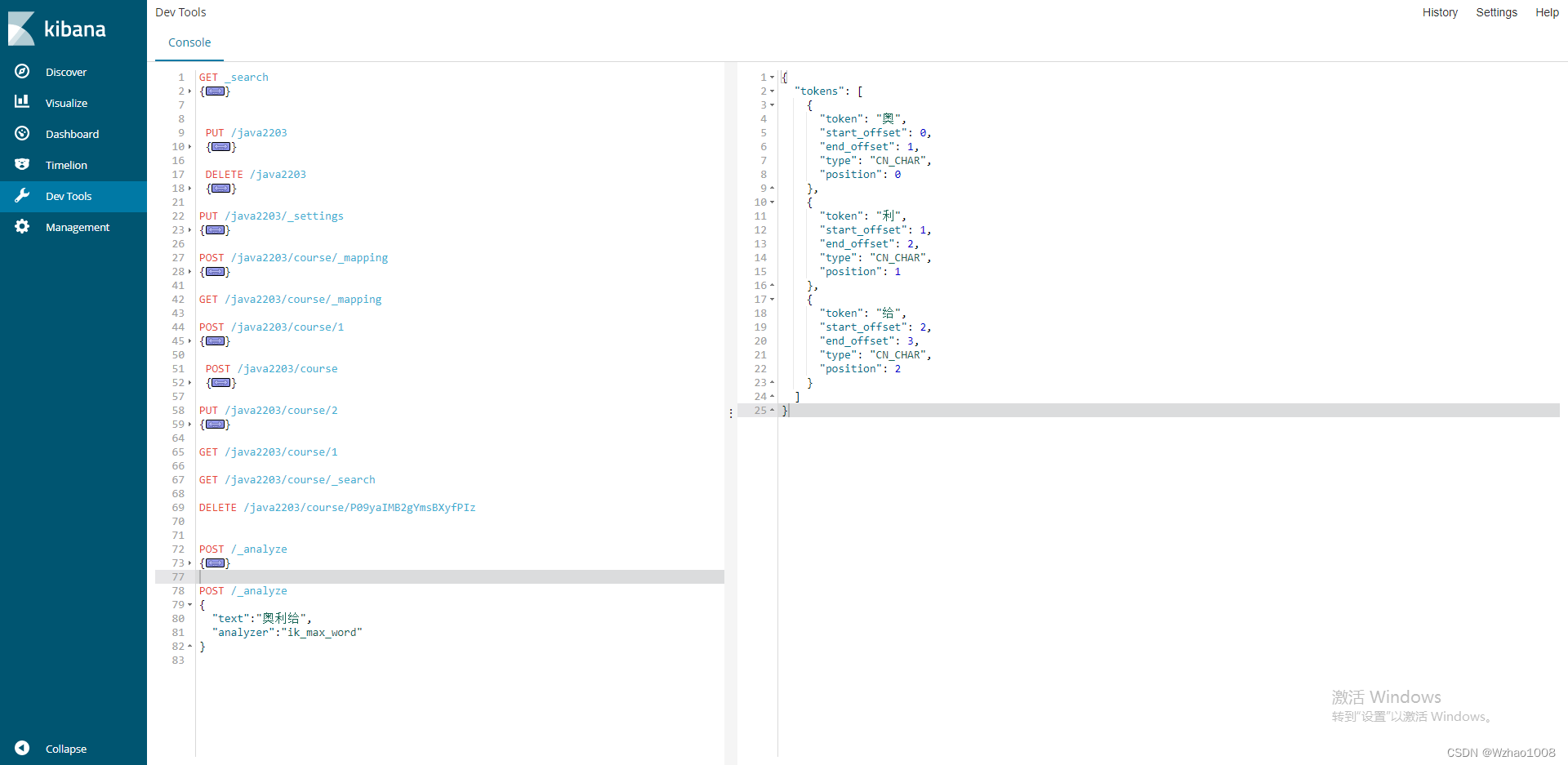
},
"properties": {
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"description": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"pic":{
"type":"text",
"index":false
}
}
}
插入文档
POST /java2203/course/1
{
"name":"java从入门到放弃",
"description":"人生苦短,我用java",
"pic":"250.jpg"
}
查询测试
GET /java06/course/_search?q=name:放弃
GET /java06/course/_search?q=description:人生
GET /java06/course/_search?q=pic:250.jpg
结果:name和description都支持全文检索,pic不可作为查询条件
keyword关键字字段
text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段往索引目录写时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
更改映射
POST /java2203/course/_mapping
{
"properties": {
"studymodel":{
"type":"keyword"
}
}
}
GET /java06/course/_search?q=studymodel:2010年01月
date日期类型
日期类型不用设置分词器,通常日期类型的字段用于排序。
1)format
通过format设置日期格式,多个格式使用双竖线||分隔, 每个格式都会被依次尝试, 直到找到匹配的
设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
POST /java2203/course/_mapping
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
插入文档
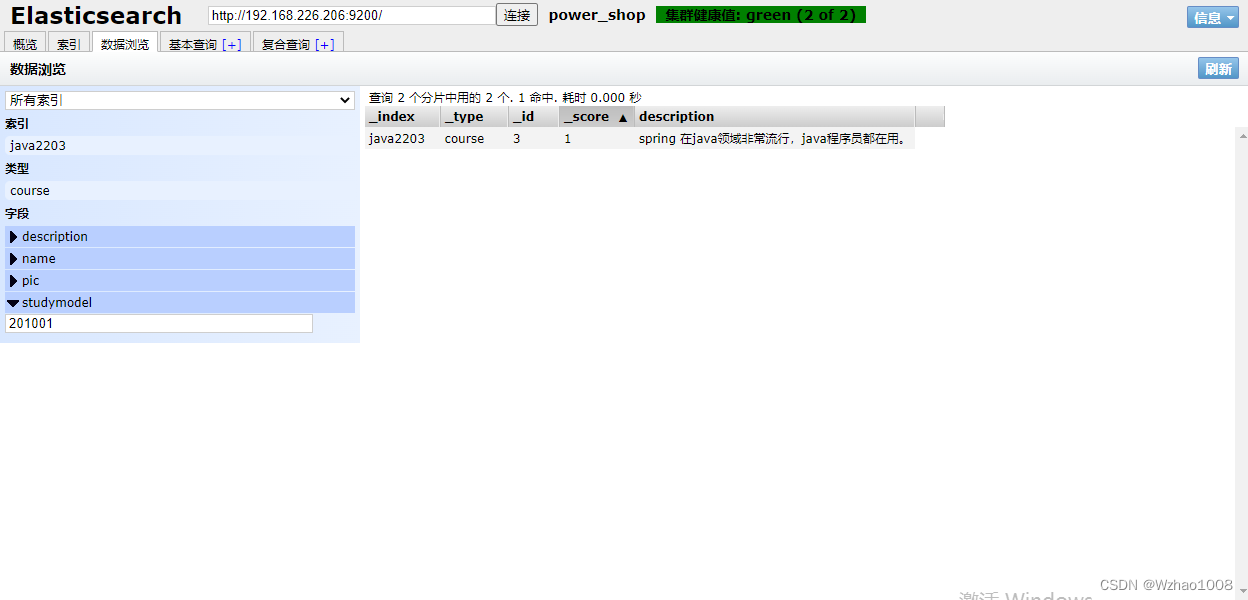
PUT /java2203/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic":"250.jpg",
"timestamp":"2018-07-04"
}
Numeric类型
es中的数字类型经过分词(特殊)后支持排序和区间搜索
更新已有映射:
POST /java2203/course/_mapping
{
"properties": {
"price": {
"type": "float"
}
}
}
插入文档
PUT /java2203/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic": "250.jpg",
"price": 38.6
}
field属性的设置标准
| 属性 | 标准 |
|---|---|
| type | 是否有意义 |
| index | 是否搜索 |
| source | 是否展示 |
Spring Boot整合ElasticSearch
ES提供多种不同的客户端:
1、TransportClient
ES提供的传统客户端,官方计划8.0版本删除此客户端。
2、RestClient
RestClient是官方推荐使用的,它包括两种:REST Low Level Client和 REST High Level Client。ES在6.0之后提供REST High Level Client, 两种客户端官方更推荐使用 REST High Level Client,不过当前它还处于完善中,有些功能还没有。
搭建工程
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
</parent>
<groupId>com.bjpowernode</groupId>
<artifactId>springboot_elasticsearch</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<!-- 修改elasticsearch的版本 -->
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









