







**
引言
**
在 Windows 内核编程中,处理字符串是一个常见的任务。本文将通过一个示例代码,介绍在 Windows 内核编程中如何声明、初始化、拷贝、拼接和比较字符串。在这个示例代码中,我们将使用以下几种方法来处理字符串:
- 使用
DECLARE_CONST_UNICODE_STRING宏 - 使用
RtlInitUnicodeString函数 - 使用
RTL_CONSTANT_STRING宏 - 使用
ExAllocatePoolWithTag函数动态分配内存 - 使用
RtlCopyUnicodeString函数拷贝字符串 - 使用
RtlAppendUnicodeStringToString和RtlAppendUnicodeToString函数拼接字符串 - 使用
RtlCompareUnicodeString函数比较字符串
示例代码解析
以下是一个 Windows 内核驱动程序的示例代码,我们将逐步解析该代码以了解字符串处理的不同方法。
#include "ntifs.h"
VOID DriverUnload(PDRIVER_OBJECT pDreverObject) {
UNREFERENCED_PARAMETER(pDreverObject);
}
NTSTATUS DriverEntry(PDRIVER_OBJECT pDreverObject, PUNICODE_STRING pRegPath) {
UNREFERENCED_PARAMETER(pRegPath);
pDreverObject->DriverUnload = DriverUnload;
...
}
在这个示例代码中,我们首先包含了 “ntifs.h” 头文件,然后定义了一个 DriverUnload 函数,该函数在驱动程序卸载时调用。DriverEntry 是驱动程序的入口点,它接收一个指向 DRIVER_OBJECT 结构体的指针和一个指向 UNICODE_STRING 结构体的指针作为参数。
声明和初始化字符串
在 DriverEntry 函数中,我们将展示如何使用不同的方法声明和初始化字符串。
第一种方法:使用 DECLARE_CONST_UNICODE_STRING 宏
DECLARE_CONST_UNICODE_STRING(usStr0, L"Hello World_1");
DbgPrint("%wZ\r\n", usStr0);
我们可以使用 DECLARE_CONST_UNICODE_STRING 宏来声明一个常量的 Unicode 字符串。这里我们声明了一个名为 usStr0 的 UNICODE_STRING 结构体,然后使用 DbgPrint 函数将其打印到调试输出。
第二种方法:使用 RtlInitUnicodeString 函数
UNICODE_STRING usStr1 = { 0 };
RtlInitUnicodeString(&usStr1, L"Hello World_2");
DbgPrint("%wZ\r\n", usStr1);
我们可以使用 RtlInitUnicodeString 函数来初始化一个 UNICODE_STRING 结构体。这里我们声明了一个名为 usStr1 的 UNICODE_STRING 结构体,然后调用 RtlInitUnicodeString 函数初始化它,并使用 DbgPrint 函数将其打印到调试输出。
第三种方法:手动初始化 UNICODE_STRING 结构体
UNICODE_STRING usStr2 = { 0 };
WCHAR wcStr[512] = L"Hello World\_3";
usStr2.Buffer = wcStr;
usStr2.Length = (USHORT)wcslen(wcStr) \* sizeof(WCHAR);
usStr2.MaximumLength = usStr2.Length;
DbgPrint("%wZ\\r\\n", usStr2);
这里,我们手动初始化一个名为 usStr2 的 UNICODE_STRING 结构体。我们首先声明一个宽字符数组 wcStr,然后将其赋值给 usStr2.Buffer。接着,我们计算字符串的长度,并将其赋值给 usStr2.Length 和 usStr2.MaximumLength。最后,我们使用 DbgPrint 函数将其打印到调试输出。
第四种方法:使用 RTL_CONSTANT_STRING 宏
UNICODE_STRING usStr3 = RTL_CONSTANT_STRING(L"Hello World_4");
DbgPrint("%wZ\r\n", usStr3);
我们可以使用 RTL_CONSTANT_STRING 宏来创建一个常量的 Unicode 字符串。这里我们声明了一个名为 usStr3 的 UNICODE_STRING 结构体,并使用 DbgPrint 函数将其打印到调试输出。
第五种方法:使用 ExAllocatePoolWithTag 函数动态分配内存
UNICODE_STRING usStr4 = { 0 };
USHORT uLength = (USHORT)((wcslen(L"Hello World_5")) * sizeof(WCHAR));
usStr4.Buffer = ExAllocatePoolWithTag(NonPagedPool, uLength, 'ABCD');
if (usStr4.Buffer == NULL) {
return STATUS_SUCCESS;
}
else {
RtlZeroMemory(usStr4.Buffer, uLength);
RtlCopyMemory(usStr4.Buffer, L"Hello World_5", uLength);
usStr4.Length = uLength;
usStr4.MaximumLength = uLength;
DbgPrint("%wZ\r\n", usStr4);
}
在这种方法中,我们使用 ExAllocatePoolWithTag 函数动态分配内存来创建一个 UNICODE_STRING 结构体。首先,我们声明一个名为 usStr4 的 UNICODE_STRING 结构体,并计算字符串所需的内存大小。然后,我们使用 ExAllocatePoolWithTag 函数为字符串分配内存,接着使用 RtlZeroMemory 和 RtlCopyMemory 函数初始化字符串。最后,我们设置字符串的长度和最大长度,并使用 DbgPrint 函数将其打印到调试输出。
拷贝字符串
c
UNICODE_STRING usStr5 = { 0 };
WCHAR wcBuffer[256];
RtlInitEmptyUnicodeString(&usStr5, (PWCHAR)&wcBuffer, 256 * sizeof(WCHAR));
RtlCopyUnicodeString(&usStr5, &usStr0);
DbgPrint("%wZ\r\n", usStr5);
这里,我们使用 RtlCopyUnicodeString 函数拷贝一个 Unicode 字符串。首先,我们声明一个名为 usStr5 的 UNICODE_STRING 结构体,并使用 RtlInitEmptyUnicodeString 函数初始化它。然后,我们使用 RtlCopyUnicodeString 函数将 usStr0 的内容拷贝到 usStr5 中,并使用DbgPrint 函数将其打印到调试输出。
拼接字符串
c
RtlAppendUnicodeStringToString(&usStr5, &usStr0);
DbgPrint("%wZ\r\n", usStr5);
WCHAR wcStr1[512] = L"Core Objects";
RtlAppendUnicodeToString(&usStr5, wcStr1);
DbgPrint("%wZ\r\n", usStr5);
在这部分,我们展示如何使用 RtlAppendUnicodeStringToString 和 RtlAppendUnicodeToString 函数拼接字符串。首先,我们使用 RtlAppendUnicodeStringToString 函数将 usStr0 拼接到 usStr5 的末尾,然后使用 DbgPrint 函数将结果打印到调试输出。接着,我们使用 RtlAppendUnicodeToString 函数将宽字符数组 wcStr1 拼接到 usStr5 的末尾,并再次使用 DbgPrint 函数将结果打印到调试输出。
字符串比较
c
if (0 == RtlCompareUnicodeString(&usStr3, &usStr4, FALSE)) {
DbgPrint("==");
}
else {
DbgPrint("!=");
}
DECLARE_CONST_UNICODE_STRING(usStr6, L"Hello World!");
DECLARE_CONST_UNICODE_STRING(usStr7, L"Hello World!");
if (0 == RtlCompareUnicodeString(&usStr6, &usStr7, FALSE)) {
DbgPrint("==");
}
else {
DbgPrint("!=");
}
return STATUS_SUCCESS;
}
在这部分,我们展示如何使用 RtlCompareUnicodeString 函数比较两个 Unicode 字符串。首先,我们比较 usStr3 和 usStr4,如果它们相等,则输出 “",否则输出 “!=”。然后,我们声明并初始化两个名为 usStr6 和 usStr7 的 UNICODE_STRING 结构体,并比较它们。如果它们相等,则输出 "”,否则输出 “!=”。最后,我们返回 STATUS_SUCCESS,表示驱动程序已成功加载。
运行结果
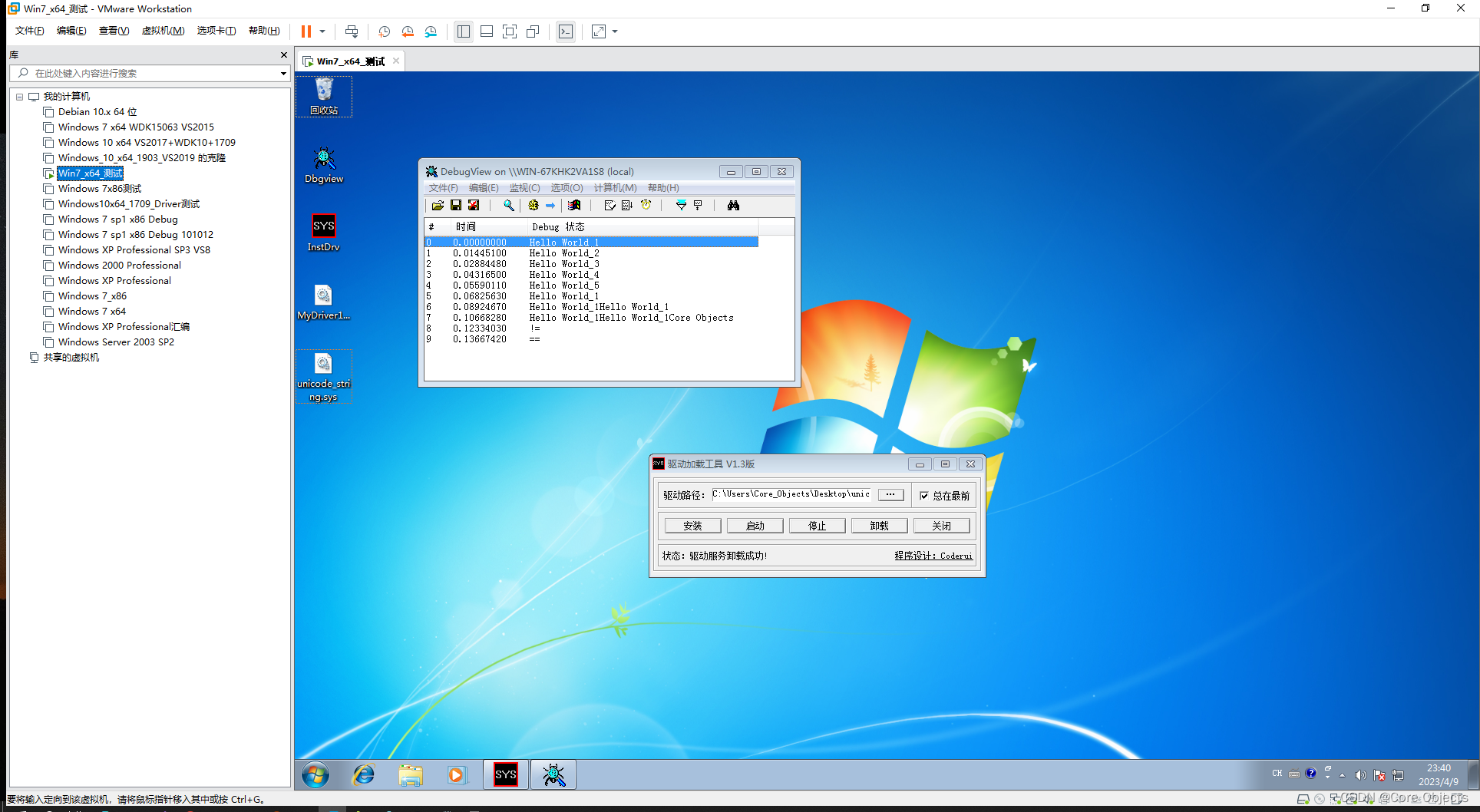
结论
本文通过一个 Windows 内核驱动程序示例代码介绍了如何在 Windows 内核编程中声明、初始化、拷贝、拼接和比较字符串。在实际编程中,我们可能会使用这些方法来处理字符串,以完成各种内核编程任务。需要注意的是,内核编程与用户模式编程有很大的不同,因此在处理字符串时要特别小心,避免出现内存泄漏、越界访问等问题。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









