







命名空间
在c语言当中:当我们定义了一个函数,但是这个函数与库函数发生了重名,或者这个函数和我们之前定义的函数发生了重名,这时候我们就只能更换这个函数名,以此来避免。
但是在C++中,我们处理的方式有所区别:我们使用的是命名空间的方式,这样就可以避免发生命名冲突的情况了
命名空间的使用方法
命名空间的构建方式:与结构体的构建方式非常相似。
namespace A
{
int a = 10;
int Add(int x, int y)
{
return x + y;
}
}
1.using namespace [命名空间名称]:这样做相当于把命名空间中所有的定义都展开到了全局作用域中,这样做的话,如果命名空间中存在和全局作用域重复的名称,也会发生命名冲突。
2.using [命名空间]::[变量名]:这样做相当于将命名空间中的部分变量放到了全局作用域中,我们推荐这种做法
3.不适用using,当我们需要用到命名空间中的部分变量名时,使用命名空间+::变量名:例如 std::cout << 【输出值】 <<std::endl;
注意:当我们在同一个或者不同源文件中,多次使用同一个命名空间,编译器会将同名的命名空间合并到一起,组成一个更加庞大的命名空间
IO
什么是IO?
实际上IO就指的是input和Outpot,输入输出。
c和c++的区别
当我们在C语言中使用标准IO时,使用的函数是scanf和printf,但是我们会发现,这样的方式好像存在一些不安全的因素。
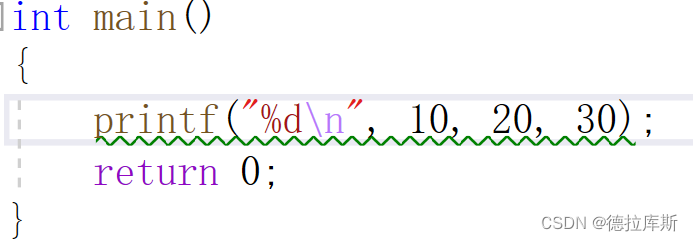
当我们使用printf()函数的时候,如果只打印一个值,但是给了多个值的时候,依然可以打印出来结果,可是按照严谨的逻辑来说,编译器应该报错,告诉我们这个写法不正确,但是c语言的编译器并没有这样做,这样就会导致程序的安全性不足。
还有另外一个缺点,我们需要记住不同数据类型的编码,如果记错了,也会无法打印。
而C++语言就避免了这些缺陷,我们可以直接使用cin和cout搭配<<>>来进行输入和输出。
当我们需要使用c++的代码时,标准输入输出库函数就需要修改为,并且cin cout是包含在std这个命名空间的,我们需要将这些函数都放到全局作用域中,才能正常使用这些函数。
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
int main()
{
int data;
cout << "hello world" << endl;
cin >> data;
cout << data << endl;
return 0;
}
此外,当我们使用c语言定义函数的时候,可以不指定函数的返回值类型,编译器会默认返回值类型的int,而c++不可以,必须指定返回值类型,否则就会报错。
同时,c语言是不支持函数重载的,而c++是支持的
这里我们简单介绍一下什么是函数重载
函数重载
在c++语言中,在同一个作用域中,出现函数名称相同,但是函数的参数类型,函数参数数量,函数参数顺序不同,标志着这是不同的函数实现的功能也不相同。
int Add(int a,int b)
{
return a + b;
}
int Add(double a, double b)
{
return a + b;
}
int Add(int a, double b)
{
return a + b;
}
这三个函数会发生函数重载,如果我们调用Add这个函数,那么编译器会区分我们传的值来确定调用哪个Add函数,如果完美匹配到可以调用的函数,则进行调用,如果没有找到可以完美匹配的,并且可以发生隐式整形提升,那么也可以调用,否则报错。
Add(10, 20)//可以进行调用
Add(10.0, 20.0)//可以进行调用
Add(10, 20.0)//可以进行调用
Add('a', 'b')//无法进行调用
那么就有一个问题,为何c语言不支持函数重载,但是c++就支持呢?
实际上,是因为编译器在编译的时候对函数的命名方式不同
c语言在编译的时候,函数的命名是在函数名称前加一个_,因此,多个同名函数是无法进行区分的,那么就无法进行函数重载。
而c++语言的函数命名是一个较为复杂的情况,编译器会将这个函数的名称,参数类型,返回值类型都编译到最终的函数名称中,这样在编译的时候,根据我们传的参数,编译器就可以知道调用哪个函数。
引用
引用并不是定义一个变量,而是给已经存在的变量取了一个别名,编译器也不会为引用开辟新的内存空间,引用和被引用的变量共用一块内存空间。
引用的使用方法
int a = 10;
int& ra = a;//注意,引用类型和引用实体必须是同种类型
在c语言中,我们传参的方式共有两种,传值和传地址,传值实际上是对实参的一份临时拷贝,并不能修改实参,若需要通过形参改变实参的值,就需要传地址
void Add(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 10;
int b = 20;
Add(a, b);
cout << a << endl << b << endl;
return 0;
}
而在c++中,既有上述两种传参的形式,又增加了一种名为引用的概念,我们可以通过传引用来实现和传地址相同的操作,来修改实参的值。
现象:
int& Add(int a, int b)
{
int res = a + b;
return res;
}
int main()
{
int& r = Add(10, 20);
Add(30, 40);
Add(50, 60);
printf("%d\n", r);
printf("%d\n", r);
return 0;
}

为何打印两次的结果不相同,并且在debug过程中,查看r的值,在三次函数调用的过程中都会得到正确的计算结果?
解释:第一次调用Add函数的时候,我们将返回值res进行了引用,而这个res是在栈上被开辟的,当Add函数调用结束,Add开辟的函数栈帧就会被释放,此时r这个引用实际上对应的空间也被释放了,但是操作系统并没有对其中的垃圾数据进行清理,而下次这块内存空间需要被使用时,内存中的数据才会被清理,这样就看到了r对应的值得到了正确的计算结果(因为每次调用相同的函数,因此开辟的函数栈帧也是相同大小的,r指向那块内存恰好也是上次res的位置)。当第一次调用printf函数时,首先函数进行了传参,此时将r对应位置上的值进行了传递,因此将r位置的值记录了下来,随后,因为需要开辟printf的函数栈帧,所以会将上一次内存空间中的垃圾数据进行清理置为随机值,第二次调用printf函数时,传参r读取到的实际上已经被初始化了,因此看到的是一个随机值。
产生原因:将引用作为返回值返回,并且返回的是栈上开辟的空间。
避免方法:引用作为方法的返回值时,返回的实体一定不能返回栈上空间,返回的实体的生命周期要比方法的运行周期长,例如:返回全局变量,返回static修饰的变量。
引用和指针的区别
在实现的底层汇编指令来看,引用和指针是相同的实现方式,都是以指针的方式来实现的,但是从概念层面来看,二者是有区别的。
从概念上看,引用是变量的一个别名,和被引用的变量共用内存空间。
指针需要进行取地址和解引用操作,引用没有这两个操作,是编译器自动实现的。
引用一个变量后,这个引用就不能再改变了
相当于int& ra = a; ra的类型实际为int* const,因为ra的指向是不能改变的。
总结一下引用和指针的区别:
1.引用概念上定义一个变量的别名,指针存储一个变量的地址
2.引用在定义时必须初始化,指针没有要求
3.引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4.没有NULL引用,但是有NULL指针
5.在sizeof中的含义不同,引用结果为引用类型的大小,指针是地址空间所占字节个数
6.引用自增为引用的实体自增,而指针自增为指针向后偏移一个类型的大小
7.有多级指针,但是没有多级引用
8.指针需要显式解引用,而引用可以通过编译器自己处理
9.由于3的存在,使得引用比指针使用起来更加安全















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









