







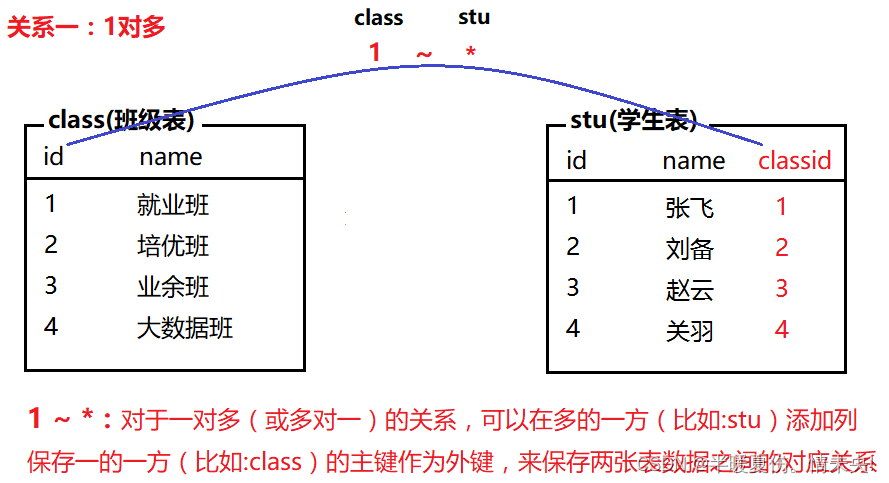
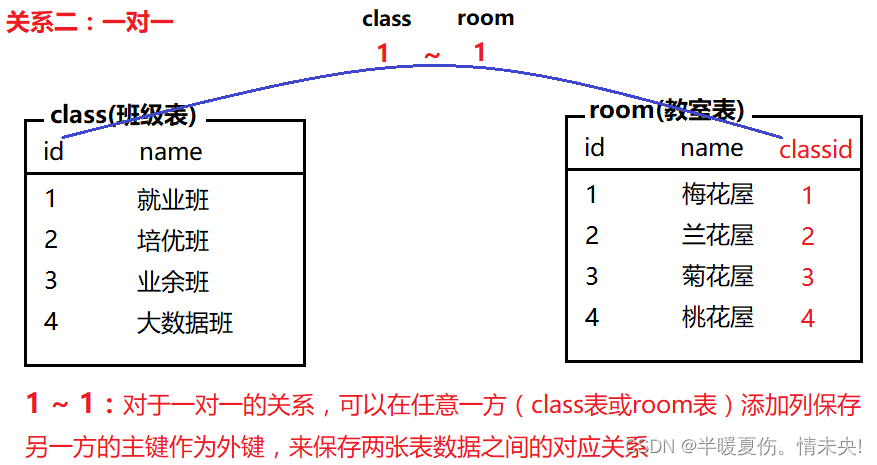
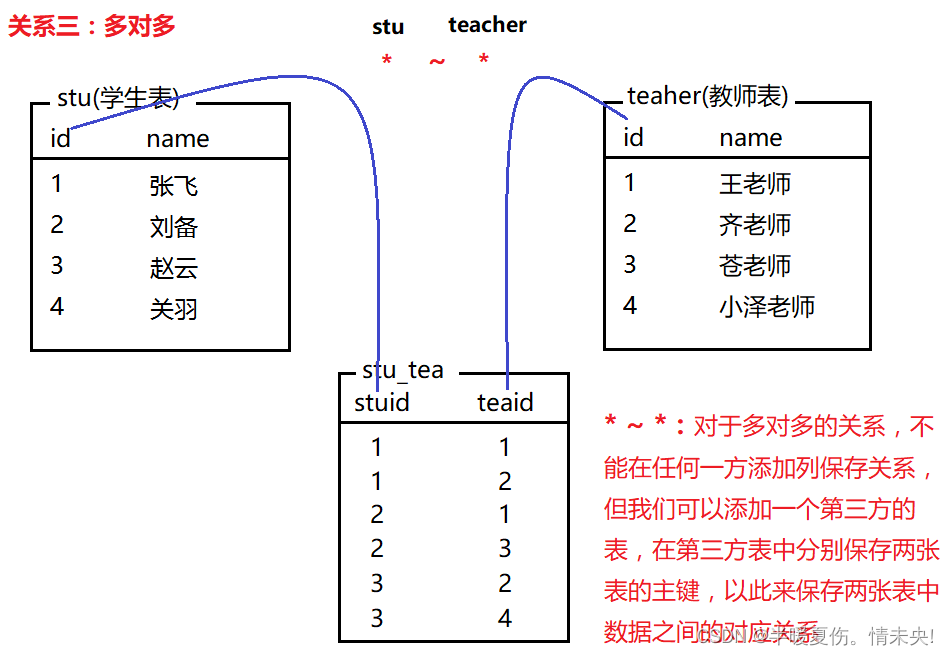
表关系
常见的表关系分为以下三种:
一对多(多对一)·、一对一、多对多
多表查询
– 准备数据: 以下练习将使用db30库中的表及表记录,请先进入db30数据库!!!
连接查询
– 42.查询部门和部门对应的员工信息
select * from dept,emp;
上面的查询中存在大量错误的数据,一般我们不会直接使用这种查询。
笛卡尔积查询:所谓笛卡尔积查询就是指,查询两张表,其中一张表有m条记录,另一张表有n条记录,查询的结果是m*n条。
虽然笛卡尔积查询中包含大量错误数据,但我们可以通过where子句将错误数据剔除,保留下来的就是正确数据。
-- 员工所属的部门编号(emp.dept_id),等于部门的编号(dept.id)
select * from dept,emp
where emp.dept_id=dept.id;
通过where子句将笛卡尔积查询中的错误数据剔除,保留正确的数据,这就是连接查询!
上面的查询可以换成下面的查询:
select * from dept inner join emp
on emp.dept_id=dept.id;
-- 内连接查询,和上面的查询结果一样。
左外连接查询
– 43.查询【所有部门】及部门对应的员工,如果某个部门下没有员工,员工显示为null
select * from dept left join emp
on emp.dept_id=dept.id;

左外连接查询:可以将左边表中的所有记录都查询出来,右边表只显示和左边相对应的数据,如果左边表中某些记录在右边没有对应的数据,右边显示为null即可。
右外连接查询
– 44.查询【所有员工】及员工所属的部门,如果某个员工没有所属部门,部门显示为null即可
select * from dept right join emp
on emp.dept_id=dept.id;

右外连接查询:可以将右边表中的所有记录都查询出来,左边表只显示和右边相对应的数据,如果右边表中某些记录在左边没有对应的数据,可以显示为null。
扩展:如果想将两张表中的所有数据都查询出来(左外+右外并去除重复记录),可以使用全外连接查询,但是mysql又不支持全外连接查询。
select * from dept left join emp on emp.dept_id=dept.id
union
select * from dept right join emp on emp.dept_id=dept.id;
可以使用union将左外连接查询的结果和右外连接查询的结果合并在一起,并去除重复的记录。例如:

需要注意的是:union可以将两条SQL语句执行的结果合并,但是有前提:
(1)两条SQL语句查询的结果列数必须一致
(2)两条SQL语句查询的结果列名、顺序也必须一致
并且union默认就会将两个查询中重复的记录去除(如果不希望去除重复记录,可以使用union all)
子查询练习
– 准备数据:以下练习将使用db40库中的表及表记录,请先进入db40数据库!!!
– 45.列出薪资比’王海涛’的薪资高的所有员工,显示姓名、薪资
-- 求出'王海涛'的薪资
select sal from emp where name='王海涛'; -- 2450
-- 求出薪资比 '王海涛'的薪资 还高的所有员工
select name, sal from emp
where sal > (select sal from emp where name='王海涛');
– 46.列出与’刘沛霞’从事相同职位的所有员工,显示姓名、职位。
-- 查询'刘沛霞'从事的职位
select job from emp where name='刘沛霞'; -- 推销员
-- 求从事'推销员'职位的所有员工
select name, job from emp
where job = (select job from emp where name='刘沛霞');
– 47.列出薪资比’大数据部’部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
如果不考虑没有部门的员工
-- 连接查询部门表和员工表, 显示员工姓名、薪资和部门名称
select emp.name,sal,dept.name from dept,emp
where emp.dept_id=dept.id;
-- 求大数据部门的最高薪资是多少
select max(sal) from emp where dept_id=30; -- 3000
-- 在连接查询的基础上, 求出 薪资 比大数据部门最高薪资 还高的员工信息
select emp.name,sal,dept.name from dept,emp
where emp.dept_id=dept.id
and sal > (select max(sal) from emp where dept_id=30);
如果加上没有部门的员工
-- 用外连接查询部门和所有员工, 显示员工姓名、薪资和部门名称
select emp.name,sal,dept.name from dept right join emp
on emp.dept_id=dept.id;
-- 求大数据部门的最高薪资是多少
select max(sal) from emp where dept_id=30; -- 3000
-- 在外连接查询的基础上, 求出 薪资 比大数据部门最高薪资 还高的员工信息
select emp.name,sal,dept.name from dept right join emp
on emp.dept_id=dept.id
where sal > (select max(sal) from emp where dept_id=30);
多表查询练习
– 48.列出在’培优部’任职的员工,假定不知道’培优部’的部门编号,显示部门名称,员工名称。
-- 连接查询部门表和员工表(可以给表名指定别名,指定后就需要使用别名,不能再使用表名)
select d.name, e.name from dept d,emp e
where e.dept_id=d.id;
-- 在上面查询的基础上, 求出培优部的员工
select d.name, e.name from dept d,emp e
where e.dept_id=d.id
and d.name='培优部';
//添加别名 为两个表分别添加指定表的别名
select d.nmae,e.name fromm emp e,dept d
where e.dept_id=d.id
and d.name='培优部';
– 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
/*
将 emp 表看做两张表, 分别是员工表(emp e1) 和 上级表(emp e2)
显示的列: e1.name, e2.id, e2.name
查询的表: emp e1, emp e2
连接条件: e1.topid=e2.id
*/
select e1.name, e2.id, e2.name
from emp e1, emp e2
where e1.topid=e2.id;
– 50.列出最低薪资大于1500的各种职位,显示职位和该职位的最低薪资
-- 根据职位进行分组, 求出每个职位对应的最低薪资
select job,min(sal) from emp
group by job;
-- 求出最低薪资大于1500的职位有哪些
e
补充内容:where和having子句的区别:
相同点: 都是对查询的结果进行筛选过滤
不同点:
(1)where是在分组之前对数据进行筛选过滤; 而having是在分组之后对数据进行筛选过滤
(2)where子句中不能使用多行数据, 也不能使用列别名, 但可以使用表别名; 而having中可以使用多行函数, 也可以使用列别名和表别名;
– 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
-- 根据部门进行分组,每个部门的员工为一组,统计每个部门的员工人数和平均薪资
select dept_id,count(*),avg(sal)
from emp
group by dept_id;
– 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
-- 连接查询部门表和员工表,显示部门编号、名称和位置, 员工名称
select d.id, d.name, d.loc, e.name
from emp e,dept d
where e.dept_id=d.id;
-- 在上面查询的基础上, 根据部门分组, 统计每个部门的人数
select d.id, d.name, d.loc, count(*)
from emp e,dept d
where e.dept_id=d.id
group by d.name;
-- 在上面查询的基础上,按照部门人数降序排序
瑟lect
– 53.列出受雇日期早于直接上级的所有员工,显示员工编号、员工姓名、部门名称。
/* 将emp表分别看做员工表(emp e1)和上级表(emp e2)
显示的列: e1.id, e1.name, d.name
查询的表: emp e1, emp e2, dept d
连接条件,员工表和上级表关联: e1.topid=e2.id
连接条件,员工表和部门表关联: e1.dept_id=d.id
筛选条件,员工的入职日期小于上级的入职日期: e1.hdate < e2.hdate */
select e1.id, e1.name, d.name
from emp e1, emp e2, dept d
where e1.topid=e2.id
and e1.dept_id=d.id
and e1.hdate < e2.hdate;
– 补充:查询员工表中薪资最高的员工信息
-- 求emp表中的最高薪资
select max(sal) from emp;
--name和max(sal)很可能是不对应
select name,max(sal) from emp;
-- 求出emp表中的哪个员工的薪资等于最高薪资
select * from emp where sal = (select max(sal) from emp);
-- 或者 让员工信息按照薪资降序排序,再分页,只取第一条!
select * from emp order by sal desc limit 0,1;














 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









