







 本文介绍了如何在Windows 10环境下,使用Python 3.6和PyCharm,通过Scrapy框架爬取jobbole博客的所有技术文章。首先,通过国内镜像安装Scrapy和pypiwin32库。接着分析目标网站,确定文章入口URL和翻页方法。文章内容包括提取文章标题、日期等信息,并在Scrapy的shell中进行调试。最后提到需要将抓取的数据存储,为后续入库做准备。
本文介绍了如何在Windows 10环境下,使用Python 3.6和PyCharm,通过Scrapy框架爬取jobbole博客的所有技术文章。首先,通过国内镜像安装Scrapy和pypiwin32库。接着分析目标网站,确定文章入口URL和翻页方法。文章内容包括提取文章标题、日期等信息,并在Scrapy的shell中进行调试。最后提到需要将抓取的数据存储,为后续入库做准备。
用国内镜像安装,
安装scrapy,
pip install -i http://pypi.douban.com/simple scrapy
pip install -i http://pypi.douban.com/simple pypiwin32
安装以上2个库就能正常运行scrapy了
环境:
win10-64
python3.6
开发工具:pycharm
首先分析目标网站:
http://blog.jobbole.com/

然后我们打开开发者工具看下所有的文章的入口URL是保存在哪个标签里.
根据观察发现:
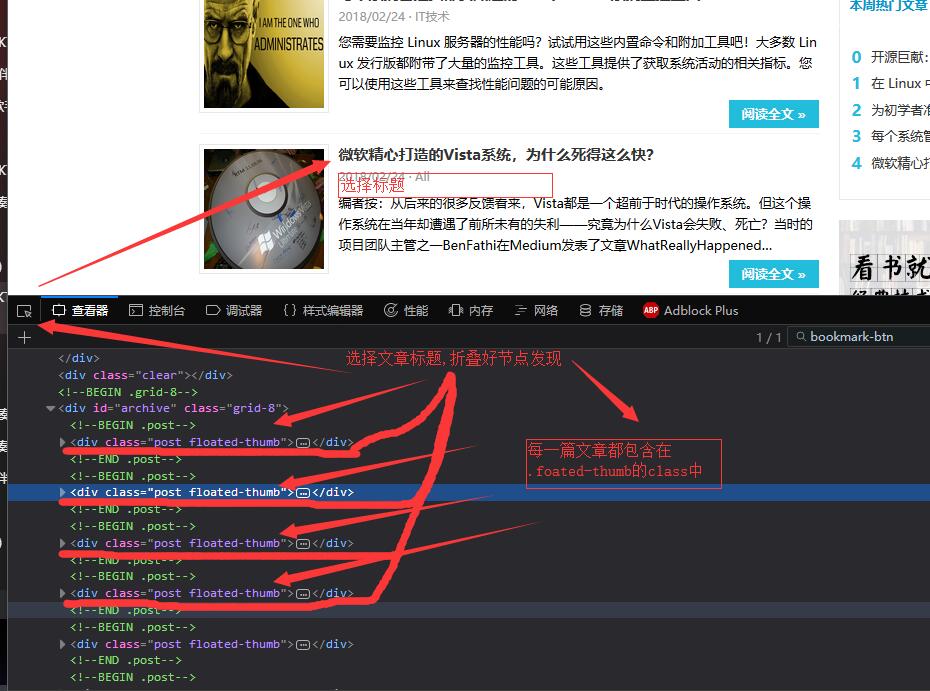
由上图可见,我们已经知道了应该走哪进入相关文章的列表,那么我们再看看翻页怎么去实现,有两个方法,
一个是 for page in rang(n),但是我们怎么知道今天553页,但是明天是否还是553呢?所以这个方法排除.
另外一个方法,还是走网页里找答案.

好了,我们翻页的方法页找到了,那么.我们进入文章看看,有哪些关键的信息可以给我们提取的,随便点击一篇文章进行分析。
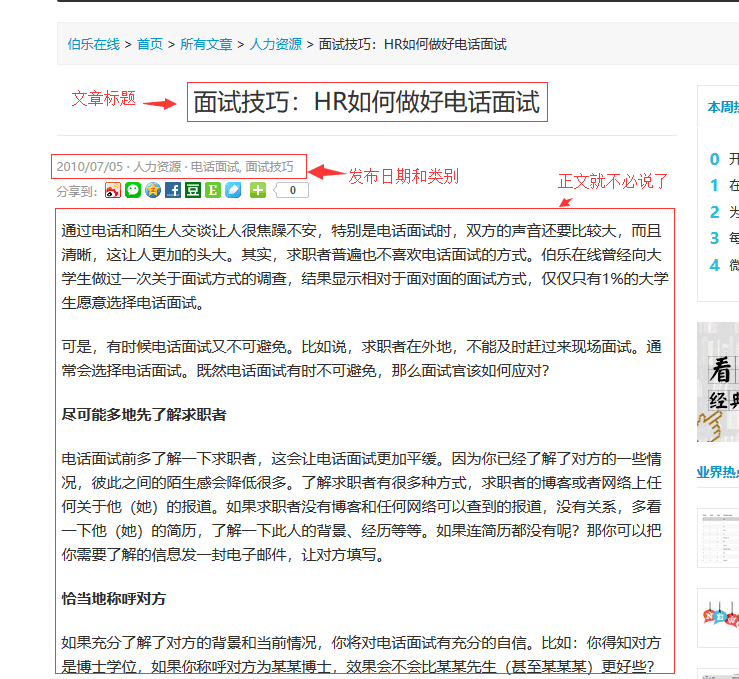
就爬这些吧,如果有别的需求,也可以增加对吧,然后 我们打开别的文章看看,有什么不一样的地方.
另外一篇文章里面,多出来了重复的消息!!因为我们本来就要抓评论数.所以,这个东西我们需要在代码里面把他去除.

我们现在分析,我们所需要的东西都网页的哪些位置以及什么关键字!!方便我们后面写代码!还是老办法,F12开发者工具走起!

其它元素就自己找了!下面我们用scrapy提供的调试工具开始调试我们所需要的代码.
WIN+R键打开运行,输入cmd.

在命令提示符下面输入:
scrapy shell 文章地址,

因为翻页的东西我们都找到了.所以我们先调试需要获取的参数,翻页的url.我们一会儿再调试.
scrapy为我们提供了一些方法.

我们用到的就是response这个方法!
这里我用的匹配节点的方法是css选择器.如果不了解css选择器,可以自行了解哈!!!

发现一件尴尬的事情,我们还没创建爬虫项目!=.=~~~~~
不过无关紧要,现在创建也可以!!!
打开一个新的命令提示符:
然后cd到你想创建爬虫的文件夹!
scrapy startproject (项目名称,个人发挥)

示例,创建好了项目,然后创建爬虫!
scrapy gensider (爬虫名字,依然个人发挥) 目标url , 实例看图咯:

然后用Pychram打开项目!,找到爬虫文件!

这就是我们刚建的爬虫,def parse这里就是我们需要写代码逻辑的地方!!!
不过我们需要添加一个函数,用于写提取文章相关的代码!完整代码下面会有的.下面,我们继续分析网站!!.我们已经把标题提出来了,我们所需要的东西,也需要一个一个在网站里面去找!现在我们提取日期,

依然在shell下面调试!

下面的提取基本就没什么难点了!我就不说了.下面直接上代码!
# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy.http import Request
from urllib import parse
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
'''用于翻页以及提取相关url并交给我们定义的函数提取文章相关信息'''
post_nodes = response.css("#archive .floated-thumb .post-meta a")
for post_node in post_nodes:
image_url = post_node.css("img ::sttr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url}, callback=self.parse_detail)
next_urls = response.css(".next.page-numbers ::attr(href)").extract_first("")
if next_urls:
yield Request(url=parse.urljoin(response.url, post_url), callback=self.parse)
'''
Xpath提取方法
'''
# article_title = response.xpath('//div[@class="entry-header"]/h1/text()').extract()
# create_date = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].strip().replace("·", "").strip()
# praise_nums = response.xpath('//span[contains(@class,"vote-post-up")]/h10/text()').extract()[0]
# fav_nums = response.xpath('//span[contains(@class,"bookmark-btn")]/text()').extract()
# match_re = re.match(".*(\d+).*", fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath('//a[href="#article-comment"]/text()').extract()
# match_re = re.match(".*(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# tag_list = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/a/text()').extract()
# content = response.xpath('//div[@class="entry"]').extract()[0]
# tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
# tags = ",".join(tag_list)
def parse_detail(self, response):
'''css提取文章方法'''
front_image_url = response.meta.get('front_image_url', '')
article_title = response.css('.entry-header h1 ::text').extract()
create_data = response.css('.entry-meta-hide-on-mobile ::text').extract()[0].strip().replace("·", "").strip()
praise_nums = response.css('.vote-post-up h10 ::text').extract()[0]
fav_nums = response.css('.bookmark-btn ::text').extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0
comment_nums = response.css('a[href="#article-comment"] span ::text').extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = int(match_re.group(1))
else:
comment_nums = 0
content = response.css('.entry').extract()[0]
tag_list = response.css('.entry-meta-hide-on-mobile a ::text').extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)还有一个地方需要改动,就是

相关文章的提取就到 这里,下一章说明一下怎么把提取到的东西入库.咳咳!!!不存起来就烂掉了.
欢迎各位看官指正,谢谢!!!















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









